Изоляционный лес - Isolation forest
Изоляционный лес является обучение без учителя алгоритм для обнаружение аномалии который работает по принципу изолирования аномалий,[1] вместо наиболее распространенных методов профилирования обычных точек.[2]

В статистика, аномалия (также известная как выброс ) - это наблюдение или событие, которое настолько отличается от других событий, что вызывает подозрения, что оно было вызвано другим способом. Например, график на рисунке 1 представляет входящий трафик на веб-сервер, выраженный как количество запросов с трехчасовыми интервалами за период в один месяц. Достаточно просто взглянуть на картинку, что некоторые точки (отмеченные красным кружком) необычно высоки, что вызывает подозрение, что веб-сервер мог быть атакован в то время. С другой стороны, плоский сегмент, обозначенный красной стрелкой, также кажется необычным и, возможно, может быть признаком того, что сервер не работал в течение этого периода времени.
Аномалии в большом наборе данных могут следовать очень сложным схемам, которые в подавляющем большинстве случаев трудно обнаружить «на глаз». Это причина того, что область обнаружения аномалий хорошо подходит для применения Машинное обучение техники.
Наиболее распространенные методы, используемые для обнаружения аномалий, основаны на построении профиля того, что является «нормальным»: аномалии сообщаются как те экземпляры в наборе данных, которые не соответствуют нормальному профилю.[2] Isolation Forest использует другой подход: вместо того, чтобы пытаться построить модель обычных экземпляров, он явно изолирует аномальные точки в наборе данных. Главное преимущество такого подхода - возможность эксплуатации отбор проб методы до такой степени, которая не разрешена для методов на основе профилей, создавая очень быстрый алгоритм с низким потреблением памяти.[1][3][4]
История
Алгоритм Isolation Forest (iForest) был первоначально предложен Фей Тони Лю, Кай Мин Тингом и Чжи-Хуа Чжоу в 2008 году.[1] Авторы воспользовались двумя количественными характеристиками аномальных точек данных в выборке:
- Мало - это меньшинство, состоящее из меньшего количества экземпляров и
- Разные - они имеют значения атрибутов, которые сильно отличаются от значений обычных экземпляров.
Поскольку аномалии «немногочисленны и различны», их легче «изолировать» по сравнению с нормальными точками. Isolation Forest строит ансамбль «Деревьев изоляции» (iTrees) для набора данных, а аномалии - это точки, которые имеют более короткие средние длины пути на iTrees.
В более поздней статье, опубликованной в 2012 г.[2] те же авторы описали серию экспериментов, чтобы доказать, что iForest:
- имеет низкую линейную временную сложность и небольшие требования к памяти
- может работать с многомерными данными с нерелевантными атрибутами
- можно обучать с аномалиями или без них в обучающей выборке
- может предоставлять результаты обнаружения с разными уровнями детализации без повторного обучения
В 2013 году Чжиго Дин и Минруи Фэй предложили фреймворк на основе iForest для решения проблемы обнаружения аномалий в потоковой передаче данных.[5] Более подробное использование iForest для потоковой передачи данных описано в статьях Tan et al.,[4] Susto et al.[6] и Weng et al.[7]
Одна из основных проблем применения iForest для обнаружения аномалий заключалась не в самой модели, а в том, как рассчитывалась «оценка аномалий». Эта проблема была подчеркнута Сахандом Харири, Матиасом Карраско Кинд и Робертом Дж. Бруннером в статье 2018 г.[8] в котором они предложили улучшенную модель iForest под названием Лес расширенной изоляции (EIF). В той же статье авторы описывают улучшения, внесенные в исходную модель, и то, как они могут повысить согласованность и надежность оценки аномалии, полученной для данной точки данных.
Алгоритм
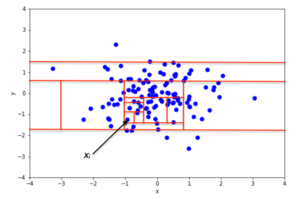
В основе алгоритма Isolation Forest лежит тенденция того, что аномальные экземпляры в наборе данных легче отделить от остальной части выборки (изолировать) по сравнению с нормальными точками. Чтобы изолировать точку данных, алгоритм рекурсивно генерирует разделы для выборки, случайным образом выбирая атрибут, а затем случайным образом выбирая значение разделения для атрибута между минимальным и максимальным значениями, разрешенными для этого атрибута.
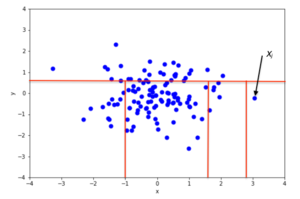
Пример случайного разбиения в 2D-наборе данных нормально распределенный На рис. 2 приведены точки для неаномальной точки, а на рис. 3 - для точки, которая с большей вероятностью является аномалией. Из изображений видно, что аномалии требуют меньшего количества случайных разделов для изолирования по сравнению с нормальными точками.
С математической точки зрения рекурсивное разбиение может быть представлено древовидной структурой с именем Дерево изоляции, в то время как количество разделов, необходимых для изолирования точки, можно интерпретировать как длину пути в дереве до конечного узла, начиная с корня. Например, длина пути точки xя на рис.2 больше, чем длина пути xj на рис.3.
Более формально, пусть X = {x1, ..., Иксп } - набор d-мерных точек, а X ’⊂ X - подмножество X. Дерево изоляции (iTree) определяется как структура данных со следующими свойствами:
- для каждого узла T в дереве T является либо внешним узлом без дочерних узлов, либо внутренним узлом с одним «тестом» и ровно двумя дочерними узлами (Tл, Тр)
- тест в узле T состоит из атрибута q и значения разделения p, так что тест q
л или Tр.
Чтобы построить iTree, алгоритм рекурсивно делит X ’путем случайного выбора атрибута q и значения разделения p до тех пор, пока либо (i) узел не будет иметь только один экземпляр, либо (ii) все данные в узле не будут иметь одинаковые значения.
Когда iTree полностью вырос, каждая точка в X изолирована на одном из внешних узлов. Интуитивно понятно, что аномальные точки - это те точки (поэтому их легче изолировать) с меньшими длина пути в дереве, где длина пути h (xя) точки определяется как количество ребер xя проходит от корневого узла до внешнего узла.

Вероятностное объяснение iTree дается в оригинальной статье iForest.[1]
Свойства изоляционного леса
- Подвыборка: поскольку iForest не нужно изолировать все обычные экземпляры, он часто может игнорировать большую часть обучающей выборки. Как следствие, iForest работает очень хорошо, когда размер выборки остается небольшим, а это свойство контрастирует с подавляющим большинством существующих методов, где обычно желателен большой размер выборки.[1][2]
- Заболачивание: когда нормальные экземпляры слишком близки к аномалиям, количество разделов, необходимых для разделения аномалий, увеличивается, явление, известное как заболачивание, из-за чего iForest сложнее отличить аномалии от нормальных точек. Одной из основных причин заболачивания является наличие слишком большого количества данных для обнаружения аномалии, что подразумевает, что одним из возможных решений проблемы является подвыборка. Поскольку iForest очень хорошо реагирует на подвыборку с точки зрения производительности, уменьшение количества точек в выборке также является хорошим способом уменьшить эффект заболачивания.[1]
- Маскировка: когда количество аномалий велико, возможно, что некоторые из них собираются в плотный и большой кластер, что затрудняет разделение отдельных аномалий и, в свою очередь, обнаружение таких точек как аномальных. Подобно заболачиванию, это явление (известное как «маскировка”) Также более вероятен, когда количество точек в выборке велико, и его можно уменьшить с помощью подвыборки.[1]
- Данные большого размера: одним из основных ограничений стандартных дистанционных методов является их неэффективность при работе с наборами данных большой размерности :.[9] Основная причина этого в том, что в пространстве большой размерности каждая точка одинаково разрежена, поэтому использование меры разделения на основе расстояния довольно неэффективно. К сожалению, данные большого размера также влияют на производительность обнаружения iForest, но производительность можно значительно улучшить, добавив тест выбора функций, например Эксцесс для уменьшения размерности выборочного пространства.[1][3]
- Только обычные экземпляры: iForest работает хорошо, даже если обучающий набор не содержит аномальных точек,[3] причина в том, что iForest описывает распределения данных таким образом, что высокие значения длины пути h (xя) соответствуют наличию точек данных. Как следствие, наличие аномалий практически не влияет на эффективность обнаружения iForest.
Обнаружение аномалий с помощью изолированного леса
Обнаружение аномалий с помощью Isolation Forest - это процесс, состоящий из двух основных этапов:[3]
- на первом этапе обучающий набор данных используется для построения деревьев iTrees, как описано в предыдущих разделах.
- на втором этапе каждый экземпляр в наборе тестов проходит через сборку iTrees на предыдущем этапе, и соответствующая «оценка аномалии» присваивается экземпляру с использованием алгоритма, описанного ниже.
После того, как всем экземплярам в наборе тестов была присвоена оценка аномалии, можно отметить как «аномалию» любую точку, оценка которой превышает предварительно определенный порог, который зависит от области применения анализа.
Оценка аномалий
Алгоритм вычисления оценки аномалии точки данных основан на наблюдении, что структура iTrees эквивалентна структуре Деревья двоичного поиска (BST): завершение внешнего узла iTree соответствует неудачному поиску в BST.[3] Как следствие, оценка среднего h (x) для завершений внешнего узла такая же, как и для неудачных поисков в BST, то есть[10]

где n - размер тестовых данных, m - размер набора выборок, а H - номер гармоники, который можно оценить с помощью , куда это Постоянная Эйлера-Маскерони.


Вышеуказанное значение c (m) представляет собой среднее значение h (x) для данного m, поэтому мы можем использовать его для нормализации h (x) и получения оценки оценки аномалии для данного экземпляра x:

где E (h (x)) - среднее значение h (x) из набора iTrees. Интересно отметить, что для любого данного экземпляра Икс:
- если s близко к 1, тогда Икс очень вероятно, что это аномалия
- если s меньше 0,5, то Икс скорее всего будет нормальным значением
- если для данной выборки всем экземплярам присваивается оценка аномалии около 0,5, то можно с уверенностью предположить, что в образце нет аномалии
Лес расширенной изоляции
Как описано в предыдущих разделах, алгоритм Isolation Forest очень хорошо работает как с точки зрения вычислений, так и с точки зрения потребления памяти. Основная проблема исходного алгоритма заключается в том, что способ ветвления деревьев вносит систематическую ошибку, которая, вероятно, снижает надежность оценок аномалий для ранжирования данных. Это основная мотивация внедрения Лес расширенной изоляции (EIF) алгоритм Hariri et al.[8]

Чтобы понять, почему исходный Isolation Forest страдает от этого смещения, авторы предоставляют практический пример, основанный на случайном наборе данных, взятом из двумерного нормального распределения с нулевым средним и ковариацией, заданными единичной матрицей. Пример такого набора данных показан на рис.4.
Глядя на рисунок, легко понять, что точки, падающие близко к (0, 0), скорее всего, будут нормальными точками, а точка, которая находится далеко от (0, 0), скорее всего, будет аномальной. Как следствие, оценка аномалии точки должна увеличиваться с почти круглым и симметричным рисунком, поскольку точка перемещается радиально наружу от «центра» распределения. На практике это не так, как демонстрируют авторы, генерируя карту оценок аномалий, созданную для распределения алгоритмом Isolation Forest. Хотя оценки аномалии правильно увеличиваются по мере того, как точки перемещаются в радиальном направлении наружу, они также создают прямоугольные области с более низкой оценкой аномалии в направлениях x и y по сравнению с другими точками, которые находятся примерно на том же радиальном расстоянии от центра.

Можно продемонстрировать, что эти неожиданные прямоугольные области на карте оценки аномалий действительно являются артефактом, введенным алгоритмом, и в основном связаны с тем, что границы принятия решений в Isolation Forest ограничены либо вертикальными, либо горизонтальными (см. Рис. 2). и рис. 3).[8]
Это причина, по которой в своей статье Hariri et al. предлагают улучшить исходный Isolation Forest следующим образом: вместо того, чтобы выбирать случайный объект и значение из диапазона данных, они выбирают срез ветви, имеющий случайный «наклон». Пример случайного разбиения с EIF показан на рисунке 5.
Авторы показывают, как новый подход может преодолеть ограничения оригинального Isolation Forest, что в конечном итоге приводит к улучшенной карте оценки аномалий.
Реализации с открытым исходным кодом
- Spark iForest - Распределенная реализация на Scala и Python, работающая на Apache Spark. Написано Ян, Фанчжоу.
- Лес изоляции - Реализация Spark / Scala, созданная Джеймс Вербус от команды LinkedIn Anti-Abuse AI.
- EIF - Реализация расширенного леса изоляции для обнаружения аномалий Саханд Харири
- Реализация Python с примерами в scikit-learn.
- Пакетное одиночество реализация в р к Срикантх Комала Шешачала
Смотрите также
Рекомендации
- ^ а б c d е ж грамм час Лю, Фэй Тони; Тинг, Кай Мин; Чжоу, Чжи-Хуа (декабрь 2008 г.). «Лес изоляции». 2008 Восьмая международная конференция IEEE по интеллектуальному анализу данных: 413–422. Дои:10.1109 / ICDM.2008.17. ISBN 978-0-7695-3502-9.
- ^ а б c d Чандола, Варун; Банерджи, Ариндам; Кумар, Кумар (июль 2009 г.). «Обнаружение аномалий: исследование». Опросы ACM Computing. 41. Дои:10.1145/1541880.1541882.
- ^ а б c d е Лю, Фэй Тони; Тинг, Кай Мин; Чжоу, Чжи-Хуа (декабрь 2008 г.). «Обнаружение аномалий на основе изоляции» (PDF). Транзакции ACM при обнаружении знаний из данных. 6: 1–39. Дои:10.1145/2133360.2133363.
- ^ а б Тан, Суи Чуан; Тинг, Кай Мин; Лю, Фэй Тони (2011). «Быстрое обнаружение аномалий при потоковой передаче данных». Материалы двадцать второй международной совместной конференции по искусственному интеллекту. 2. AAAI Press. С. 1511–1516. Дои:10.5591 / 978-1-57735-516-8 / IJCAI11-254. ISBN 9781577355144.
- ^ Дин, Чжиго; Фей, Минруй (сентябрь 2013 г.). «Подход к обнаружению аномалий на основе алгоритма изолированного леса для потоковой передачи данных с использованием скользящего окна». 3-я Международная конференция МФБ по интеллектуальному управлению и автоматизации.
- ^ Сусто, Джан Антонио; Беги, Алессандро; Маклоун, Шон (2017). «Обнаружение аномалий посредством онлайн-изоляции Forest: приложение для плазменного травления». 2017 28-я ежегодная конференция SEMI Advanced Semiconductor Manufacturing Conference (ASMC) (PDF). С. 89–94. Дои:10.1109 / ASMC.2017.7969205. ISBN 978-1-5090-5448-0.
- ^ Weng, Yu; Лю, Лэй (15 апреля 2019 г.). «Подход коллективного обнаружения аномалий для многомерных потоков в безопасности мобильных услуг». IEEE доступ. 7: 49157–49168. Дои:10.1109 / ACCESS.2019.2909750.
- ^ а б c Харири, Саханд; Карраско Кинд, Матиас; Бруннер, Роберт Дж. (2019). «Лес расширенной изоляции». IEEE Transactions по разработке знаний и данных: 1. arXiv:1811.02141. Дои:10.1109 / TKDE.2019.2947676.
- ^ Дилини Талагала, Приянга; Гайндман, Роб Дж .; Смит-Майлз, Кейт (12 августа 2019 г.). «Обнаружение аномалий в данных большой размерности». arXiv:1908.04000 [stat.ML ].
- ^ Шаффер, Клиффорд А. (2011). Структуры данных и анализ алгоритмов в Java (3-е изд. Dover). Минеола, Нью-Йорк: Dover Publications. ISBN 9780486485812. OCLC 721884651.