Анализ близости цитирования - Co-citation Proximity Analysis
Анализ близости цитирования или же CPA это документ мера сходства который использует анализ цитирования для оценки семантического сходства между документами как на уровне глобального документа, так и на уровне отдельных разделов.[1][2] Мера подобия основана на анализ совместного цитирования подход, но отличается тем, что он использует информацию, подразумеваемую при размещении цитат в полных текстах документов.
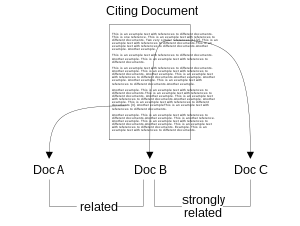
Анализ близости цитирования был разработан Б. Гиппом в 2006 г.[3] а описание меры сходства документов было позже опубликовано Гиппом и Билом в 2009 году.[1] Мера сходства основана на предположении, что в пределах полного текста документа документы, цитируемые в непосредственной близости друг от друга, имеют тенденцию быть более тесно связанными, чем документы, цитируемые дальше друг от друга. Рисунок справа иллюстрирует концепцию. Подход CPA к подобию документов предполагает, что документы B и C более тесно связаны, чем документы B и A, потому что ссылки на B и C происходят в одном предложении, тогда как ссылки на B и A разделены несколькими абзацами.
Преимущество подхода CPA по сравнению с другими подходами к анализу цитирования и совместного цитирования заключается в повышении точности. Другие широко используемые подходы к анализу цитирования, такие как Библиографическая связь, Совместное цитирование или Мера Амслера, не принимают во внимание расположение или близость цитат в документах. Подход CPA позволяет осуществлять более детальную автоматическую классификацию документов, а также может использоваться для идентификации не только связанных документов, но и конкретных разделов в текстах, которые наиболее связаны.
Методика расчета
Мера сходства CPA вычисляет Индекс близости цитирования (ИПЦ) для каждого комплекта документов, на который ссылается проверяемый документ.[1] Цитируемым документам присваивается вес , куда п обозначает количество уровней между цитатами. Начиная с самого низкого уровня, уровни могут быть определены как группы цитирования, предложения, абзацы, главы и, наконец, весь документ или даже журнал.

Есть несколько вариантов алгоритма CPA.
- Базовая цена за конверсию - фундаментальная концепция CPA, как описано выше
- Расширенная цена за конверсию - учитывает древовидную структуру и порядок цитирования в группах цитирования
- Многомерный CPA - использует дополнительную информацию, такую как импакт-фактор
- Гибрид-CPA - объединяет ИПЦ с другими показателями сходства, например текстовыми мерами. Это повышает производительность, особенно для документов с недостаточной информацией о цитировании.
Спектакль
Измерение сходства CPA основано на подходе схожести документов совместного цитирования с отличительным добавлением анализа близости. Следовательно, подход CPA позволяет рассчитывать более детальное разрешение общего сходства документов. Было обнаружено, что CPA превосходит анализ совместного цитирования, особенно когда документы содержат обширную библиографию и в тех случаях, когда документы не часто цитируются вместе (т. Е. Имеют низкий балл совместного цитирования).[1][4] Лю и Чен обнаружили, что совместное цитирование на уровне предложения является потенциально более эффективными маркерами для использования в анализе совместного цитирования по сравнению со слабосвязанным совместным цитированием только на уровне статьи, поскольку совместное цитирование на уровне предложения, как правило, сохраняет основную структуру традиционной сети совместного цитирования, а также составляют гораздо меньшее подмножество всех экземпляров совместного цитирования.[5]
Анализ Schwarzer et al.[4] показали, что показатели на основе цитирования CPA и анализ совместного цитирования, имеют дополнительные преимущества по сравнению с мерами сходства на основе текста. Подходы на основе текстового подобия надежно идентифицировали более узко похожие статьи из тестовой коллекции статей Википедии, например статьи, использующие идентичные термины, в то время как подход CPA превосходит CoCit в определении более общих статей, а также более популярных статей, которые, по утверждениям авторов, также имеют более высокое качество.[4]
Смотрите также
- CITREC, структура оценки для показателей сходства на основе цитирования, таких как Библиографическая связь, Совместное цитирование, Анализ близости цитирования и другие.[6]
Рекомендации
- ^ а б c d Бела Гипп и Джоран Бил, 2009 г. «Citation Proximity Analysis (CPA) - новый подход к выявлению связанных работ на основе анализа совместного цитирования» в Биргере Ларсен и Жаклин Лета, редакторах, Труды 12-й Международной конференции по наукометрии и информетрике (ISSI’09), том 2, страницы 571–575, Рио-де-Жанейро (Бразилия), июль 2009 г.
- ^ Бела Гипп и Джоран Бил. «Метод и система определения сходства документов». Заявка на патент, 27 октября 2011 г. 2011/0264672 A1.
- ^ Бела Гипп, 2006. "Докторантура: (Со) анализ близости цитирования - мера для выявления связанных работ"
- ^ а б c М. Шварцер, М. Шуботц, Н. Меушке, К. Брайтингер, В. Маркл и Б. Гипп, «Оценка рекомендаций для Википедии на основе ссылок» в материалах 16-й совместной конференции ACM / IEEE-CS по электронным библиотекам (JCDL), Нью-Йорк, штат Нью-Йорк, США, 2016 г., стр. 191-200.
- ^ Шэнбо Лю и Чаомей Чен, 2001 г. «Влияние близости совместного цитирования на анализ совместного цитирования», 13-я конференция Международного общества наукометрии и информетрики (ISSI), 4–7 июля 2011 г. Дурбан, Южная Африка.
- ^ Бела Гипп, Норман Меушке и Марио Липински, 2015. "CITREC: Система оценки показателей сходства на основе цитирования на основе геномики TREC и PubMed Central" in Proceedings of the iConference 2015, Newport Beach, California, 2015.
дальнейшее чтение
Бела Гипп и Джоран Бил. Определение сопутствующих документов для рекомендателя исследовательских работ по CPA и COA. В SI Ao, C. Douglas, WS Grundfest и J. Burgstone, редакторы, Proceedings of the world congress on engineering and computer science 2009, volume 1 of Lecture Notes in Engineering and Computer Science, pages 636-639, Berkeley (USA) , октябрь 2009 г. Международная ассоциация инженеров (IAENG), Newswood Limited. Имеется в наличии здесь
Бела Гипп. Измерение родства документов с помощью анализа близости цитирования и анализа порядка цитирования. В: М. Лалмас, Дж. Хосе, А. Раубер, Ф. Себастьяни и И. Фроммхольц, редакторы, Материалы 14-й Европейской конференции по электронным библиотекам (ecdl'10): исследования и передовые технологии для электронных библиотек, том 6273 из Конспект лекций по информатике (LNCS). Springer, сентябрь 2010 г. Доступно здесь