Левая рекурсия - Left recursion
Эта статья может быть слишком техническим для большинства читателей, чтобы понять. Пожалуйста помогите улучшить это к сделать понятным для неспециалистов, не снимая технических деталей. (Ноябрь 2015) (Узнайте, как и когда удалить этот шаблон сообщения) |
в формальная теория языка из Информатика, левая рекурсия это частный случай рекурсия где строка распознается как часть языка по тому факту, что она разлагается на строку того же языка (слева) и суффикс (справа). Например, можно распознать как сумму, потому что она может быть разбита на , также сумма, и , подходящий суффикс.



С точки зрения контекстно-свободная грамматика, а нетерминальный является леворекурсивным, если крайний левый символ в одной из его производств является самим собой (в случае прямой левой рекурсии) или может быть образован некоторой последовательностью подстановок (в случае косвенной левой рекурсии).
Определение
Грамматика леворекурсивна тогда и только тогда, когда существует нетерминальный символ что может происходить от сентенциальная форма с самим собой как крайний левый символ.[1] Символично,

- ,

куда указывает на операцию по выполнению одной или нескольких замен, и - любая последовательность терминальных и нетерминальных символов.


Прямая левая рекурсия
Прямая левая рекурсия возникает, когда определение может быть удовлетворено только одной заменой. Требуется правило формы

куда представляет собой последовательность нетерминалов и терминалов. Например, правило

является непосредственно леворекурсивным. Слева направо парсер рекурсивного спуска это правило может выглядеть как
пустота Выражение() { Выражение(); матч('+'); Срок();}и такой код при выполнении попадет в бесконечную рекурсию.
Косвенная левая рекурсия
Косвенная левая рекурсия возникает, когда определение левой рекурсии выполняется с помощью нескольких замен. Это влечет за собой набор правил по образцу




куда последовательности, каждая из которых может дать пустой строкой, в то время как вообще могут быть любые последовательности оконечных и нетерминальных символов. Обратите внимание, что эти последовательности могут быть пустыми. Вывод



затем дает как крайний левый в окончательной форме предложения.

Удаление левой рекурсии
Левая рекурсия часто создает проблемы для синтаксических анализаторов либо потому, что приводит их к бесконечной рекурсии (как в случае большинства нисходящие парсеры ) или потому, что они ожидают правил в нормальной форме, запрещающей их (как в случае многих восходящие парсеры, в том числе CYK алгоритм ). Поэтому грамматика часто предварительно обрабатывается, чтобы исключить левую рекурсию.
Удаление прямой левой рекурсии
Общий алгоритм удаления прямой левой рекурсии следующий. В этот метод внесено несколько улучшений.[2]Для леворекурсивного нетерминала , отмените все правила формы и рассмотрим оставшиеся:


куда:
- каждый непустая последовательность нетерминалов и терминалов, а
- каждый представляет собой последовательность нетерминалов и терминалов, которая не начинается с .

Замените их двумя наборами продукции, одним набором для :

и еще один набор для свежего нетерминала (часто называют «хвостом» или «остальным»):


Повторяйте этот процесс до тех пор, пока не останется прямой левой рекурсии.
В качестве примера рассмотрим набор правил

Это можно переписать, чтобы избежать левой рекурсии, как


Удаление всей левой рекурсии
Создавая топологический порядок на нетерминалах описанный выше процесс может быть расширен, чтобы также исключить косвенную левую рекурсию[нужна цитата ]:
- Входы Грамматика: набор нетерминалов и их продукция
- Выход Модифицированная грамматика, генерирующая тот же язык, но без левой рекурсии
- Для каждого нетерминала :
- Повторяйте, пока итерация не оставит грамматику неизменной:
- Для каждого правила , являясь последовательностью терминалов и нетерминалов:
- Если начинается с нетерминального и :
- Позволять быть без его руководства .
- Удалить правило .
- Для каждого правила :
- Добавить правило .
- Если начинается с нетерминального и :
- Для каждого правила , являясь последовательностью терминалов и нетерминалов:
- Удалить прямую левую рекурсию для как описано выше.
- Повторяйте, пока итерация не оставит грамматику неизменной:
- Для каждого нетерминала :









Обратите внимание, что этот алгоритм очень чувствителен к нетерминальному порядку; оптимизации часто сосредотачиваются на правильном выборе этого порядка.[требуется разъяснение ]
Ловушки
Хотя приведенные выше преобразования сохраняют язык, созданный грамматикой, они могут изменить разбирать деревья который свидетель распознавание струн. С подходящей бухгалтерией, переписывание дерева может восстановить оригиналы, но если этот шаг пропустить, различия могут изменить семантику синтаксического анализа.
Ассоциативность особенно уязвима; левоассоциативные операторы обычно появляются в правой ассоциативной структуре в новой грамматике. Например, начиная с этой грамматики:



стандартные преобразования для удаления левой рекурсии дают следующее:




Анализ строки "1-2-3" с первой грамматикой в анализаторе LALR (который может обрабатывать леворекурсивные грамматики) привел бы к дереву синтаксического анализа:
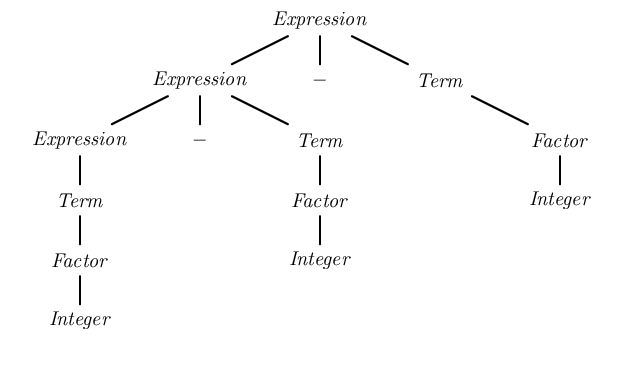
Это дерево синтаксического анализа группирует термины слева, обеспечивая правильную семантику. (1 - 2) - 3.
Парсинг со второй грамматикой дает

что при правильном толковании означает 1 + (-2 + (-3)), также правильный, но менее точный для ввода и его намного сложнее реализовать для некоторых операторов. Обратите внимание на то, как термины справа появляются глубже в дереве, так же как праворекурсивная грамматика упорядочивает их для 1 - (2 - 3).
Учет левой рекурсии при синтаксическом анализе сверху вниз
А формальная грамматика содержащий левую рекурсию не может быть разбирается по LL (k) -парсер или другой наивный парсер рекурсивного спуска если он не преобразован в слабо эквивалентный Праворекурсивная форма. Напротив, левая рекурсия предпочтительна для Парсеры LALR потому что это приводит к меньшему использованию стека, чем правая рекурсия. Однако более сложные нисходящие парсеры могут реализовывать общие контекстно-свободные грамматики за счет сокращения. В 2006 году Фрост и Хафиз описали алгоритм, который учитывает неоднозначные грамматики с прямой леворекурсивной правила производства.[3] Этот алгоритм был расширен до полной разбор алгоритм для размещения косвенной, а также прямой левой рекурсии в многочлен времени, и для создания компактных представлений полиномиального размера потенциально экспоненциального числа деревьев синтаксического анализа для весьма неоднозначных грамматик Фростом, Хафизом и Каллаганом в 2007 году.[4] Затем авторы реализовали алгоритм в виде набора комбинаторы парсеров написано в Haskell язык программирования.[5]
Смотрите также
Рекомендации
- ^ Примечания по теории формального языка и синтаксическому анализу Джеймс Пауэр, факультет компьютерных наук Ирландского национального университета, Мейнут Мейнут, графство Килдэр, Ирландия.JPR02
- ^ Мур, Роберт С. (май 2000 г.). «Удаление левой рекурсии из контекстно-свободных грамматик» (PDF). 6-я конференция по прикладной обработке естественного языка: 249–255.
- ^ Frost, R .; Р. Хафиз (2006). «Новый алгоритм нисходящего синтаксического анализа для устранения неоднозначности и левой рекурсии за полиномиальное время». Уведомления ACM SIGPLAN. 41 (5): 46–54. Дои:10.1145/1149982.1149988., доступно у автора по адресу http://hafiz.myweb.cs.uwindsor.ca/pub/p46-frost.pdf В архиве 2015-01-08 в Wayback Machine
- ^ Frost, R .; Р. Хафиз; П. Каллаган (июнь 2007 г.). «Модульный и эффективный анализ сверху вниз для неоднозначных леворекурсивных грамматик» (PDF). 10-й Международный семинар по технологиям парсинга (IWPT), ACL-SIGPARSE: 109–120. Архивировано из оригинал (PDF) на 2011-05-27.
- ^ Frost, R .; Р. Хафиз; П. Каллаган (январь 2008 г.). Комбинаторы синтаксического анализатора для неоднозначных леворекурсивных грамматик (PDF). 10-й Международный симпозиум по практическим аспектам декларативных языков (PADL), ACM-SIGPLAN. Конспект лекций по информатике. 4902. С. 167–181. Дои:10.1007/978-3-540-77442-6_12. ISBN 978-3-540-77441-9.