Аварийное восстановление - Disaster recovery
Аварийное восстановление включает набор политик, инструментов и процедур, позволяющих восстановить или продолжить жизненно важную технологическую инфраструктуру и системы после естественный или антропогенный стихийное бедствие. Аварийное восстановление сосредоточено на ИТ или технологические системы поддержка важных бизнес-функций,[1] в отличие от Непрерывность бизнеса, что включает в себя поддержание всех основных аспектов функционирования бизнеса, несмотря на серьезные разрушительные события. Таким образом, аварийное восстановление можно рассматривать как часть обеспечения непрерывности бизнеса.[2][3] Аварийное восстановление предполагает, что первичный сайт не подлежит восстановлению (по крайней мере, в течение некоторого времени), и представляет собой процесс восстановления данных и служб на вторичный уцелевший сайт, что противоположно процессу восстановления на исходное место.
Непрерывность ИТ-услуг
Непрерывность ИТ-услуг[4][5] (ITSC) - это подмножество планирование непрерывности бизнеса (BCP)[6] и включает ИТ аварийное восстановление планирование и более широкое планирование устойчивости ИТ. Он также включает в себя элементы ИТ-инфраструктура и услуги, связанные с коммуникацией, такие как (голосовая) телефония и передача данных.
План ITSC отражает Цель точки восстановления (RPO - последние транзакции) и Целевое время восстановления (RTO - временные интервалы).
Принципы резервного копирования сайтов
Планирование включает организацию резервных сайтов, будь то горячие, теплые, холодные или резервные сайты, с необходимым оборудованием для обеспечения непрерывности.
В 2008 г. Британский институт стандартов запустил специальный стандарт, связанный и поддерживающий Стандарт непрерывности бизнеса BS 25999 под названием BS25777 специально для согласования непрерывности работы компьютеров с непрерывностью бизнеса. Он был отозван после публикации в марте 2011 года стандарта ISO / IEC 27031 - Методы безопасности - Руководство по готовности информационных и коммуникационных технологий для обеспечения непрерывности бизнеса.
ITIL определил некоторые из этих терминов.[7]
Целевое время восстановления
В Целевое время восстановления (RTO)[8][9] целевая продолжительность времени и уровень обслуживания, в пределах которого бизнес-процесс должны быть восстановлены после стихийного бедствия (или сбоя), чтобы избежать неприемлемых последствий, связанных с поломкой Непрерывность бизнеса.[10]
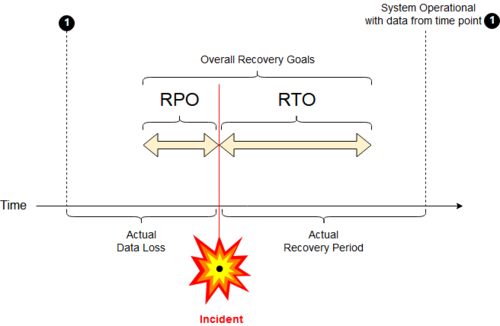
В принятом планирование непрерывности бизнеса методологии, RTO устанавливается во время Анализ влияния на бизнес (BIA) владельцем процесса, включая определение временных рамок вариантов для альтернативных или ручных обходных решений.
В значительной части литературы по этому вопросу RTO рассматривается как дополнение Цель точки восстановления (RPO) с двумя метриками, описывающими пределы приемлемого или «допустимого» ITSC производительность с точки зрения потерянное время (RTO) от нормального функционирования бизнес-процесса и с точки зрения данных, потерянных или не скопированных в течение этого периода времени (RPO) соответственно.[10][11]
Фактическое время восстановления
Обзор Forbes[8] отметил, что это Фактическое время восстановления (RTA), который является «критическим показателем для обеспечения непрерывности бизнеса и аварийного восстановления».
ДТП устанавливается во время учений или реальных мероприятий. Группа по обеспечению непрерывности бизнеса определяет время репетиций (или фактов) и вносит необходимые коррективы.[8][12]
Цель точки восстановления
А Цель точки восстановления (RPO) определяется как планирование непрерывности бизнеса. Это максимальный целевой период, в который данные (транзакции) могут быть потеряны ИТ-службой из-за серьезного инцидента.[10]
Если RPO измеряется в минутах (или даже нескольких часах), то на практике зеркальные резервные копии за пределами сайта должны быть постоянно поддерживается; ежедневного внешнего резервного копирования на ленту будет недостаточно.[13]
Связь с целевым временем восстановления
Восстановление, которое не является мгновенным, будет восстанавливать данные / транзакции в течение определенного периода времени без значительных рисков или значительных потерь.[10]
RPO измеряет максимальный период времени, в течение которого последние данные могли быть безвозвратно потеряны в случае крупного инцидента, и не является прямым показателем количества таких потерь. Например, если план BC - «восстановление до последней доступной резервной копии», то RPO - это максимальный интервал между такими резервными копиями, которые были безопасно сохранены за пределами площадки.
Анализ влияния на бизнес используется для определения RPO для каждой службы, а RPO не определяется существующим режимом резервного копирования. Когда требуется какой-либо уровень подготовки внешних данных, период, в течение которого данные могут быть потеряны, часто начинается примерно с момента начала работы по подготовке резервных копий, а не с момента их создания за пределами площадки.[11]
Точки синхронизации данных
Хотя точка синхронизации данных[14] является моментом времени, необходимо указать время выполнения физического резервного копирования. Один из используемых подходов - остановить обработку очереди обновлений, пока выполняется копирование с диска на диск. Резервная копия[15] отражает более раннее время этой операции копирования, а не когда данные копируются на ленту или передаются в другое место.
Как значения RTO и RPO влияют на проектирование компьютерной системы
RTO и RPO должны быть сбалансированы с учетом бизнес-рисков, а также всех других основных критериев проектирования системы.[16]
RPO привязан к тому времени, когда резервные копии отправляются за пределы площадки. Перенос через синхронные копии на внешнее зеркало создает самые непредвиденные трудности. Использование физического транспорта для лент (или других переносных носителей) с комфортом покрывает некоторые потребности в резервном копировании при относительно низких затратах. Восстановление может быть выполнено в заранее определенном месте. Совместное внешнее пространство и оборудование завершают необходимый пакет.[17]
Для больших объемов данных транзакций с высокой стоимостью оборудование может быть разделено на два или более сайтов; разделение на географические области повышает устойчивость.
История
Планирование аварийного восстановления и информационных технологий (ИТ) разработали в середине - конце 1970-х годов, когда менеджеры компьютерных центров начали осознавать зависимость своих организаций от своих компьютерных систем.
В то время большинство систем были партия ориентированный мэйнфреймы. Другой внешний мэйнфрейм может быть загружен с резервных лент в ожидании восстановления основного сайта; время простоя был относительно менее критичным.
Индустрия аварийного восстановления[18][19] разработан для обеспечения резервного копирования компьютерных центров. Один из первых таких центров был расположен в Шри-Ланке (Sungard Availability Services, 1978).[20][21]
В течение 1980-х и 90-х годов в качестве внутреннего корпоративного разделения времени, онлайн-ввода данных и обработка в реальном времени вырос, больше доступность ИТ-систем.
Регулирующие органы были задействованы еще до быстрого роста Интернет в течение 2000-х; цели в 2, 3, 4 или 5 девяток (99,999%) часто требовались, и высокая доступность решения для горячий сайт искались объекты.[нужна цитата ]
Непрерывность ИТ-услуг важна для многих организаций при внедрении управления непрерывностью бизнеса (BCM) и управления информационной безопасностью (ICM), а также в рамках внедрения и эксплуатации управления информационной безопасностью, а также управления непрерывностью бизнеса, как указано в ISO / IEC 27001 и ISO. 22301 соответственно.
Рост облачных вычислений с 2010 года продолжает эту тенденцию: в настоящее время даже меньше имеет значение, где физически обслуживаются вычислительные услуги, при условии, что сама сеть достаточно надежна (отдельная проблема и не вызывает беспокойства, поскольку современные сети очень устойчивы. по дизайну). «Восстановление как услуга» (RaaS) - одна из функций безопасности или преимуществ облачных вычислений, продвигаемых Cloud Security Alliance.[22]
Классификация бедствий
Бедствия могут быть результатом трех широких категорий угроз и опасностей. Первая категория - это стихийные бедствия, которые включают стихийные бедствия, такие как наводнения, ураганы, торнадо, землетрясения и эпидемии. Вторая категория - это технологические опасности, которые включают аварии или отказы систем и конструкций, такие как взрывы трубопроводов, аварии на транспорте, сбои в работе коммунальных служб, разрушение плотин и аварийные выбросы опасных материалов. Третья категория - это антропогенные угрозы, которые включают умышленные действия, такие как активные нападения, химические или биологические атаки, кибератаки на данные или инфраструктуру и саботаж. Меры по обеспечению готовности ко всем категориям и типам бедствий подразделяются на пять основных задач: предотвращение, защита, смягчение последствий, реагирование и восстановление.[23]
Важность планирования аварийного восстановления
Недавние исследования подтверждают идею о том, что внедрение более целостного подхода к планированию перед стихийными бедствиями более рентабельно в долгосрочной перспективе. Каждый доллар, потраченный на уменьшение опасности (например, План по ликвидации последствий катастрофы ) экономит обществу 4 доллара на ответных работах и затратах на восстановление.[24]
Статистика аварийного восстановления за 2015 год показывает, что простой продолжительностью в один час может стоить
- небольшие компании до 8000 долларов,
- средним организациям 74 000 долл. США, и
- крупные предприятия $ 700 000.[25]
Так как IT системы становятся все более важными для бесперебойной работы компании и, возможно, экономики в целом, важность обеспечения непрерывной работы этих систем и их быстрого восстановления возросла. Например, из компаний, у которых была большая потеря бизнес-данных, 43% никогда не открываются повторно, а 29% закрываются в течение двух лет. В результате к подготовке к продолжению работы или восстановлению систем нужно относиться очень серьезно. Это требует значительных затрат времени и денег с целью обеспечения минимальных потерь в случае сбоя.[26]
Меры борьбы
Меры контроля - это шаги или механизмы, которые могут уменьшить или устранить различные угрозы для организаций. В план аварийного восстановления (DRP) могут быть включены различные типы мер.
Планирование аварийного восстановления - это часть более крупного процесса, известного как планирование непрерывности бизнеса, и включает в себя планирование возобновления работы приложений, данных, оборудования, электронных коммуникаций (например, сетей) и другой ИТ-инфраструктуры. План обеспечения непрерывности бизнеса (BCP) включает в себя планирование аспектов, не связанных с ИТ, таких как ключевой персонал, помещения, кризисное взаимодействие и защита репутации, и должен ссылаться на план аварийного восстановления (DRP) для восстановления / непрерывности ИТ-инфраструктуры.
Меры управления аварийным восстановлением ИТ можно разделить на три типа:
- Профилактические меры - меры, направленные на предотвращение возникновения события.
- Детективные меры - меры, направленные на обнаружение или обнаружение нежелательных событий.
- Корректирующие меры - меры, направленные на исправление или восстановление системы после катастрофы или события.
Хорошие меры плана аварийного восстановления требуют, чтобы эти три типа контроля регистрировались и регулярно выполнялись с использованием так называемых «тестов аварийного восстановления».
Стратегии
Перед тем, как выбрать стратегию аварийного восстановления, планировщик аварийного восстановления сначала обращается к плану обеспечения непрерывности бизнеса своей организации, в котором должны быть указаны ключевые показатели целевой точки восстановления и целевого времени восстановления.[27] Затем показатели бизнес-процессов сопоставляются с их системами и инфраструктурой.[28]
Неспособность правильно спланировать ситуацию может увеличить последствия стихийного бедствия.[29] После того, как метрики нанесены на карту, организация проверяет ИТ-бюджет; Показатели RTO и RPO должны соответствовать доступному бюджету. А анализ выгоды и затрат часто диктует, какие меры аварийного восстановления необходимо применить.
Добавив облачное резервное копирование к преимуществам локального и удаленного ленточного архивирования, Газета "Нью-Йорк Таймс писал: «добавляет слой защиты данных».[30]
Общие стратегии для защита данных включают:
- резервное копирование на магнитную ленту и регулярная отправка за пределы объекта
- резервные копии делаются на диск на месте и автоматически копируются на внешний диск или делаются непосредственно на внешний диск
- репликация данных на удаленное место, что устраняет необходимость восстановления данных (в этом случае необходимо восстанавливать или синхронизировать только системы), часто с использованием сеть хранения данных (SAN) технология
- Решения частного облака, которые реплицируют данные управления (виртуальные машины, шаблоны и диски) в домены хранения, которые являются частью настройки частного облака. Эти данные управления настроены в виде XML-представления, называемого OVF (Open Virtualization Format), и могут быть восстановлены при возникновении аварии.
- Решения гибридного облака, которые реплицируются как в локальных, так и в удаленных центрах обработки данных. Эти решения обеспечивают возможность мгновенного переключения на локальное оборудование на объекте, но в случае физического сбоя серверы также могут быть переведены в облачные центры обработки данных.
- использование систем высокой доступности, которые поддерживают репликацию как данных, так и системы за пределами площадки, обеспечивая непрерывный доступ к системам и данным даже после аварии (часто связанной с облачное хранилище )[31]
Во многих случаях организация может решить использовать стороннего поставщика аварийного восстановления для предоставления резервного сайта и систем, а не использовать свои собственные удаленные объекты, все чаще через облачные вычисления.
Помимо подготовки к необходимости восстановления систем, организации также принимают меры предосторожности с целью предотвращения катастрофы в первую очередь. Они могут включать:
- локальные зеркала систем и / или данных и использование технологий защиты дисков, таких как RAID
- сетевые фильтры - для минимизации воздействия скачков напряжения на чувствительное электронное оборудование
- использование бесперебойный источник питания (ИБП) и / или резервный генератор для поддержания работы систем в случае сбоя питания
- системы предотвращения / уменьшения пожара, такие как сигнализация и огнетушители
- антивирусное ПО и другие меры безопасности
Аварийное восстановление как услуга (DRaaS)
Аварийное восстановление как услуга DRaaS это договоренность с третьей стороной, продавцом.[32] Обычно предлагается поставщиками услуг как часть их портфеля услуг.
Хотя списки поставщиков были опубликованы, аварийное восстановление это не продукт, это услуга, хотя несколько крупных поставщиков оборудования разработали мобильные / модульные предложения, которые можно установить и ввести в эксплуатацию в очень короткие сроки.

- Cisco Systems[33]
- Google (Модульный центр обработки данных Google ) разработал системы, которые можно использовать для этой цели.[34][35]
- Бык (мобуль)[36]
- HP (Центр обработки данных с оптимизацией производительности )[37]
- Huawei (Решение для контейнерного центра обработки данных),[38]
- IBM (Портативный модульный центр обработки данных )
- Schneider Electric (Портативный модульный центр обработки данных )
- Sun Microsystems (Модульный центр обработки данных Sun )[39][40]
- Службы доступности SunGard
- ZTE Corporation
Смотрите также
- Резервный сайт
- Непрерывность бизнеса
- Планирование непрерывности бизнеса
- Непрерывная защита данных
- План по ликвидации последствий катастрофы
- Реакция на бедствие
- Управление в чрезвычайных ситуациях
- Высокая доступность
- План действий в чрезвычайных обстоятельствах информационной системы
- Восстановление в реальном времени
- Цель восстановления согласованности
- Служба удаленного резервного копирования
- Виртуальная ленточная библиотека
- BS 25999
использованная литература
- ^ Непрерывность систем и операций: аварийное восстановление. Джорджтаунский университет. Информационные службы университета. Проверено 3 августа 2012 года.
- ^ Аварийное восстановление и непрерывность бизнеса, версия 2011 г. В архиве 11 января 2013 г. Wayback Machine IBM. Проверено 3 августа 2012 года.
- ^ [1] «Что такое управление непрерывностью бизнеса», DRI International, 2017 г.
- ^ М. Ниемимаа; Стивен Бьюкенен (март 2017 г.). «Процесс непрерывности информационных систем». ACM.com (цифровая библиотека ACM).
- ^ «Справочник непрерывности ИТ-услуг за 2017 год» (PDF). Журнал аварийного восстановления.
- ^ "Защита слоев данных". ForbesMiddleEast.com. 24 декабря 2013 г.
- ^ «Глоссарий и сокращения ITIL».
- ^ а б c «Как и проект НФЛ, часы - враг вашего времени на восстановление». Forbes. 30 апреля 2015 года.
- ^ «Три причины, по которым вы не можете уложиться в сроки восстановления после аварии». Forbes. 10 октября 2013 г.
- ^ а б c d «Понимание RPO и RTO». ДРУВА. 2008 г.. Получено 13 февраля, 2013.
- ^ а б «Как уместить RPO и RTO в планы резервного копирования и восстановления». SearchStorage. Получено 2019-05-20.
- ^ "Часы ... модификации
- ^ Ричард Мэй. «Нахождение RPO и RTO». Архивировано из оригинал на 03.03.2016.
- ^ «Передача данных и синхронизация между мобильными системами». 14 мая 2013 года.
- ^ «Поправка №5 к С-1». SEC.gov.
в реальном времени ... обеспечить резервирование и резервирование до ...
- ^ Питер Х. Грегори (03.03.2011). «Установка максимального допустимого времени простоя - постановка задач восстановления». Планирование аварийного восстановления ИТ для чайников. Вайли. С. 19–22. ISBN 978-1118050637.
- ^ Уильям Каэлли; Денис Лонгли (1989). Информационная безопасность для менеджеров. п. 177. ISBN 1349101370.
- ^ "Катастрофа? Этого здесь не может быть". Нью-Йорк Таймс. 29 января 1995 г.
.. истории болезни
- ^ «Коммерческая недвижимость / Аварийное восстановление». NYTimes.com. 9 октября 1994 г.
... индустрия аварийного восстановления выросла до
- ^ Чарли Тейлор (30 июня 2015 г.). «Американская технологическая компания Sungard объявляет о 50 рабочих местах в Дублине». The Irish Times.
Sungard .. основан в 1978 г.
- ^ Кассандра Маскареньяс (12 ноября 2010 г.). «SunGard будет жизненно важным лицом в банковской сфере». Wijeya Newspapers Ltd.
SunGard ... Будущее Шри-Ланки.
- ^ Категория 9 SecaaS // Руководство по внедрению BCDR CSA, получено 14 июля 2014 г.
- ^ «Идентификация угроз и опасностей и оценка рисков (THIRA) и обзор готовности заинтересованных сторон (SPR): Руководство по комплексной готовности (CPG) 201, 3-е издание» (PDF). Министерство внутренней безопасности США. Май 2018.
- ^ «Форум по планированию восстановления после стихийных бедствий: практическое руководство, подготовленное Партнерством по обеспечению устойчивости к стихийным бедствиям». Центр общественных услуг Университета Орегона, (C) 2007, www.OregonShowcase.org. Получено 29 октября, 2018.
- ^ «Важность аварийного восстановления». Получено 29 октября, 2018.
- ^ «План аварийного восстановления ИТ». FEMA. 25 октября 2012 г.. Получено 11 мая 2013.
- ^ Профессиональные практики управления непрерывностью бизнеса, Международный институт аварийного восстановления (DRI), 2017 г.
- ^ Григорий, Питер. Полное руководство по экзамену сертифицированного аудитора информационных систем CISA, 2009. ISBN 978-0-07-148755-9. Стр. 480.
- ^ «Пять ошибок, которые могут убить план аварийного восстановления». Dell.com. Архивировано из оригинал на 2013-01-16. Получено 2012-06-22.
- ^ Дж. Д. Бирсдорфер (5 апреля 2018 г.). «Мониторинг состояния резервного диска». Нью-Йорк Таймс.
- ^ Брэндон, Джон (23 июня 2011 г.). «Как использовать облако в качестве стратегии аварийного восстановления». Inc. Получено 11 мая 2013.
- ^ «Аварийное восстановление как услуга (DRaaS)».
- ^ «Информация и видео о решении Cisco». Знания о центрах обработки данных. 15 мая 2007 г. Архивировано с оригинал на 2008-05-19. Получено 2008-05-11.
- ^ Кремер, Брайан (11 июня 2008 г.). «Проект IBM Big Green делает второй шаг». ChannelWeb. Архивировано из оригинал на 2008-06-11. Получено 2008-05-11.
- ^ «Руководство по закупкам модульных / контейнерных центров обработки данных: оптимизация для повышения энергоэффективности и быстрого развертывания» (PDF). Архивировано из оригинал (PDF) на 2013-05-31. Получено 2013-08-30.
- ^ Кидгер, Дэниел. "Mobull Plug and Boot Datacenter". Бык. Архивировано из оригинал в 2010-11-19. Получено 2011-05-24.
- ^ «HP Performance Optimized Datacenter (POD) 20c и 40c - Обзор продукта». H18004.www1.hp.com. Архивировано из оригинал на 2015-01-22. Получено 2013-08-30.
- ^ «Решение для контейнерных центров обработки данных Huawei». Huawei. Получено 2014-05-17.
- ^ «Технические характеристики Sun's Blackbox». Архивировано из оригинал на 2008-05-13. Получено 2008-05-11.
- ^ И английская статья в Wiki о Модульный центр обработки данных Sun
дальнейшее чтение
- ISO / IEC 22301: 2012 (замена BS-25999: 2007) Социальная безопасность - Системы управления непрерывностью бизнеса - Требования
- ISO / IEC 27001: 2013 (замена ISO / IEC 27001: 2005 [ранее BS 7799-2: 2002]) Система управления информационной безопасностью
- ISO / IEC 27002: 2013 (замена ISO / IEC 27002: 2005 [перенумерованный ISO17799: 2005]) Управление информационной безопасностью - Свод правил
- ISO / IEC 22399: 2007 Руководство по обеспечению готовности к инцидентам и непрерывности работы
- ISO / IEC 24762: 2008 Руководство по услугам аварийного восстановления информационных и коммуникационных технологий.
- Профессиональные практики управления непрерывностью бизнеса, Международный институт аварийного восстановления (DRI), 2017 г.
- IWA 5: 2006 Готовность к чрезвычайным ситуациям - Британский институт стандартов -
- BS 25999-1: 2006 Управление непрерывностью бизнеса, часть 1: Свод правил
- BS 25999-2: 2007 Управление непрерывностью бизнеса, часть 2: Спецификация
- BS 25777: 2008 Управление непрерывностью информационных и коммуникационных технологий - Свод правил - Прочие -
- "Руководство по планированию непрерывности бизнеса" Джеймса К. Барнса
- «Планирование непрерывности бизнеса», Пошаговое руководство с формами планирования на CDROM Кеннета Л. Фулмера
- «Планирование выживания в случае стихийных бедствий: практическое руководство для бизнеса» Джуди Белл
- Управление данными ICE (в экстренных случаях) стало проще - от MyriadOptima.com
- Харни, Дж. (2004). Непрерывность бизнеса и аварийное восстановление: резервное копирование или завершение работы.
- Журнал AIIM E-Doc, 18 (4), 42–48.
- Диматтия, С. (15 ноября 2001 г.). Планирование непрерывности. Библиотечный журнал, 32–34.
внешние ссылки
- План аварийного восстановления ИТ от Ready.gov
- Профессиональные практики управления непрерывностью бизнеса от Международного института аварийного восстановления (DRI)
- Глоссарий непрерывности бизнеса и технологических терминов
- BS25999 Управление непрерывностью бизнеса
- Что такое RPO (цель точки восстановления) в аварийном восстановлении?