Чередующаяся память - Interleaved memory
Эта статья включает в себя список общих Рекомендации, но он остается в основном непроверенным, потому что ему не хватает соответствующих встроенные цитаты. (Октябрь 2012 г.) (Узнайте, как и когда удалить этот шаблон сообщения) |
В вычисление, перемеженная память это конструкция, которая компенсирует относительно медленное скорость из динамическая память с произвольным доступом (DRAM) или основная память, равномерно распределяя адреса памяти по банки памяти. Таким образом, непрерывные операции чтения и записи в память используют каждый банк памяти по очереди, что приводит к более высокой пропускной способности памяти из-за уменьшения времени ожидания готовности банков памяти к операциям.
Это отличается от многоканальная архитектура памяти, в первую очередь потому, что перемежающаяся память не добавляет каналов между основная память и контроллер памяти. Однако возможно чередование каналов, например, в freescale. i.MX 6 процессоров, которые позволяют выполнять чередование между двумя каналами.[нужна цитата ]
Обзор
При чередовании памяти адреса памяти назначаются каждому банку памяти по очереди. Например, в системе с чередованием с двумя банками памяти (при условии адресный по слову память), если логический адрес 32 принадлежит банку 0, то логический адрес 33 будет принадлежать банку 1, логический адрес 34 будет принадлежать банку 0 и так далее. Перемеженная память называется n-way с чередованием когда есть п банки и расположение памяти я находится в банке я мод.
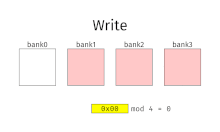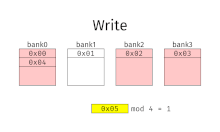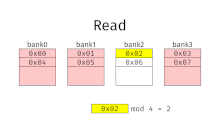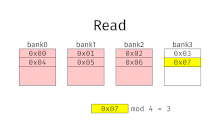
Чередование памяти приводит к непрерывному чтению (которое является обычным как для мультимедиа, так и для выполнения программ) и непрерывной записи (которые часто используются при заполнении буферов хранения или связи), фактически использующих каждый банк памяти по очереди, вместо того, чтобы использовать один и тот же повторно. Это приводит к значительно более высокой пропускной способности памяти, поскольку каждый банк имеет минимальное время ожидания между чтением и записью.
Чередование DRAM
Основная память (оперативная память, RAM) обычно состоит из набора DRAM микросхемы памяти, где несколько микросхем могут быть сгруппированы вместе, чтобы сформировать банк памяти. Затем с помощью контроллера памяти, поддерживающего чередование, можно расположить эти банки памяти так, чтобы банки памяти чередовались.
Данные в DRAM хранятся в единицах страниц. Каждый банк DRAM имеет буфер строк, который служит кешем для доступа к любой странице в банке. Перед тем, как страница в банке DRAM будет прочитана, она сначала загружается в строка-буфер. Если страница немедленно считывается из буфера строки (или попадание в буфер строки), у нее самая короткая задержка доступа к памяти за один цикл памяти. Если это промах в буфере строки, который также называется конфликтом буфера строки, это происходит медленнее, потому что новая страница должна быть загружена в буфер строки, прежде чем она будет прочитана. Промахи буфера строк происходят, когда обслуживаются запросы доступа к разным страницам памяти в одном банке. Конфликт строки и буфера приводит к значительной задержке доступа к памяти. Напротив, доступ к памяти к разным банкам может происходить параллельно с высокой пропускной способностью.
В традиционных (плоских) схемах банкам памяти может быть выделен непрерывный блок адресов памяти, что очень просто для контроллера памяти и дает одинаковую производительность в сценариях полностью произвольного доступа по сравнению с уровнями производительности, достигаемыми за счет чередования. Однако в действительности чтение из памяти редко бывает случайным из-за местонахождение ссылки, и оптимизация для близкого доступа дает гораздо лучшую производительность в чередующихся макетах.
Способ адресации памяти не влияет на время доступа к уже имеющимся ячейкам памяти. кешированный, оказывая влияние только на те участки памяти, которые необходимо извлечь из DRAM.
История
Ранние исследования чередующейся памяти проводились в IBM в 60-х и 70-х годах в связи с IBM 7030 Stretch компьютер[1] но разработка длилась десятилетия, улучшая дизайн, гибкость и производительность для создания современных реализаций.
Смотрите также
- Многоканальная архитектура памяти
- DIMM (двухрядный модуль памяти)
Рекомендации
- ^ Марк Смотерман (июль 2010 г.). «IBM Stretch (7030) - агрессивный однопроцессорный параллелизм». clemson.edu. Получено 2013-12-07.