Ядро более гладкое - Kernel smoother - Wikipedia
А ядро более гладкое это статистический метод оценки реальной стоимости функция как средневзвешенное значение соседних наблюдаемых данных. Вес определяется ядром, поэтому более близким точкам присваиваются более высокие веса. Оцениваемая функция является гладкой, и ее уровень задается одним параметром.

Этот метод наиболее подходит, когда размерность предиктора низкая (п <3), например для визуализации данных.
Определения
Позволять быть ядром, определенным


куда:
- это Евклидова норма
- параметр (радиус ядра)
- D(т) обычно является положительной вещественной функцией, значение которой уменьшается (или не увеличивается) с увеличением расстояния между Икс и Икс0.



Популярный ядра для сглаживания используются параболические (Епанечникова), Tricube и Гауссовский ядра.
Позволять быть непрерывной функцией Икс. Для каждого , средневзвешенное по ядру Надарая-Ватсона (гладкое Y(Икс) оценка) определяется как



куда:
- N это количество наблюдаемых точек
- Y(Икся) - наблюдения на Икся точки.
В следующих разделах мы описываем некоторые частные случаи сглаживания ядра.
Более гладкое ядро Гаусса
В Гауссово ядро является одним из наиболее широко используемых ядер и выражается приведенным ниже уравнением.

Здесь b - масштаб длины для входного пространства.

Ближайший сосед более плавный
Идея ближайший сосед более плавный заключается в следующем. Для каждой точки Икс0, возьмем m ближайших соседей и оценим значение Y(Икс0) путем усреднения значений этих соседей.
Формально, , куда это мth ближайший к Икс0 сосед, и
![h_ {m} (X_ {0}) = left | X_ {0} -X _ {[m]}} right |](https://wikimedia.org/api/rest_v1/media/math/render/svg/e649a2d186d0ff66a1aa6c00792a3f263293049d)
![X _ {{[m]}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c375afa1c3ce963071818546bfa67b2b846585ee)

Пример:

В этом примере Икс одномерно. Для каждого X0, то это среднее значение 16, ближайшее к Икс0 точки (обозначены красным). Результат получился недостаточно плавным.

Ядро в среднем более гладкое
Идея среднего сглаживания ядра заключается в следующем. Для каждой точки данных Икс0, выберите постоянный размер расстояния λ (радиус ядра или ширина окна для п = 1 измерение) и вычислить средневзвешенное значение для всех точек данных, находящихся ближе чем к Икс0 (чем ближе к Икс0 баллы получают больший вес).

Формально, и D(т) - одно из популярных ядер.

Пример:

Для каждого Икс0 ширина окна постоянна, а вес каждой точки в окне схематично обозначен желтой цифрой на графике. Видно, что оценка гладкая, но граничные точки смещены. Причина тому - неравное количество баллов (справа и слева направо). Икс0) в окне, когда Икс0 достаточно близко к границе.
Локальная линейная регрессия
В двух предыдущих разделах мы предполагали, что основная функция Y (X) является локально постоянной, поэтому мы смогли использовать средневзвешенное значение для оценки. Идея локальной линейной регрессии состоит в том, чтобы локально соответствовать прямой линии (или гиперплоскости для более высоких измерений), а не постоянной (горизонтальной линии). После подгонки линии оценка обеспечивается значением этой строки в Икс0 точка. Повторяя эту процедуру для каждого Икс0, можно получить оценочную функцию . Как и в предыдущем разделе, ширина окна постоянна. Формально локальная линейная регрессия вычисляется путем решения взвешенной задачи наименьших квадратов.


Для одного измерения (п = 1):

Решение в закрытой форме определяется следующим образом:

куда:



Пример:
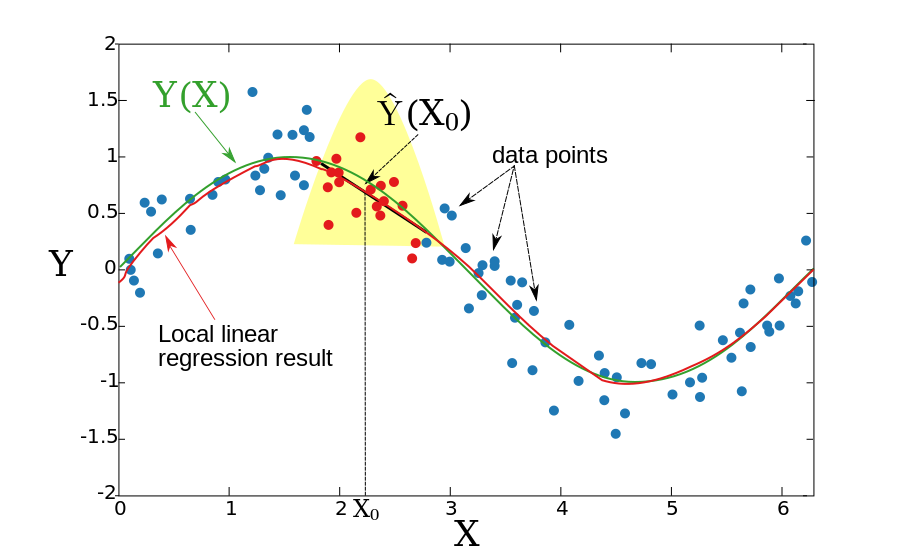
Полученная функция является гладкой, и задача со смещенными граничными точками решена.
Локальная линейная регрессия может быть применена к пространству любого измерения, хотя вопрос о том, что такое локальная окрестность, становится более сложным. Обычно для соответствия локальной линейной регрессии используются k ближайших обучающих точек к контрольной точке. Это может привести к большим отклонениям от установленной функции. Чтобы ограничить дисперсию, набор обучающих точек должен содержать контрольную точку в их выпуклой оболочке (см. Ссылку Гупта и др.).
Локальная полиномиальная регрессия
Вместо подгонки локально линейных функций можно подбирать полиномиальные функции.
При p = 1 следует минимизировать:

с

В общем случае (p> 1) следует минимизировать:

Смотрите также
Рекомендации
- Ли, К. и Дж. Расин. Непараметрическая эконометрика: теория и практика. Издательство Принстонского университета, 2007 г., ISBN 0-691-12161-3.
- Т. Хасти, Р. Тибширани и Дж. Фридман, Элементы статистического обучения, Глава 6, Springer, 2001. ISBN 0-387-95284-5 (сайт-компаньон ).
- М. Гупта, Э. Гарсия и Э. Чин, «Адаптивная локальная линейная регрессия с приложением к управлению цветом принтера», IEEE Trans. Обработка изображений 2008.