Локальная регрессия - Local regression
Эта статья включает в себя список общих Рекомендации, но он остается в основном непроверенным, потому что ему не хватает соответствующих встроенные цитаты. (Июнь 2011 г.) (Узнайте, как и когда удалить этот шаблон сообщения) |
| Часть серии по |
| Регрессивный анализ |
|---|
 |
| Модели |
| Оценка |
| Фон |
|
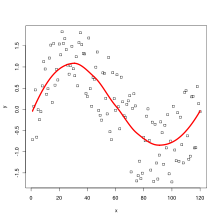
Локальная регрессия или же локальная полиномиальная регрессия[1], также известный как подвижная регрессия,[2] является обобщением скользящая средняя и полиномиальная регрессия.[3]Наиболее распространенные методы, изначально разработанные для сглаживание диаграммы рассеяния, находятся ЛЕСС (сглаживание локально оцененной диаграммы рассеяния) и НИЗКИЙ (локально взвешенное сглаживание диаграммы рассеяния), оба произносятся /ˈлoʊɛs/. Это два тесно связанных непараметрическая регрессия методы, которые объединяют несколько регрессионных моделей в k-ближайший сосед -основанная метамодель. За пределами эконометрики LOESS известна и обычно Фильтр Савицкого – Голея [4][5] (предложено за 15 лет до LOESS).
ЛЕССИЕ и МЕНЬШЕ «классические» методы, такие как линейные и нелинейные регрессия наименьших квадратов. Они касаются ситуаций, в которых классические процедуры не работают или не могут быть эффективно применены без чрезмерного труда. LOESS сочетает в себе большую часть простоты линейной регрессии наименьших квадратов с гибкостью нелинейная регрессия. Это достигается путем подгонки простых моделей к локализованным подмножествам данных для построения функции, описывающей детерминированную часть вариации данных, точка за точкой. Фактически, одна из главных достопримечательностей этого метода заключается в том, что от аналитика данных не требуется указывать глобальную функцию любой формы для соответствия модели данным, а только для соответствия сегментам данных.
Компромисс для этих функций - увеличенные вычисления. Поскольку метод LOESS требует больших вычислительных ресурсов, его было бы практически невозможно использовать в эпоху, когда развивалась регрессия наименьших квадратов. Большинство других современных методов моделирования процессов в этом отношении аналогичны LOESS. Эти методы были сознательно разработаны, чтобы использовать наши текущие вычислительные возможности в максимально возможной степени для достижения целей, которые трудно достичь с помощью традиционных подходов.
Гладкая кривая через набор точек данных, полученных с помощью этого статистического метода, называется кривая лесса, особенно когда каждое сглаженное значение дается регрессией взвешенных квадратичных наименьших квадратов по диапазону значений у-ось диаграмма рассеяния критериальная переменная. Когда каждое сглаженное значение задается взвешенной линейной регрессией наименьших квадратов по диапазону, это называется кривая занижения; однако некоторые органы рассматривают низость и лёсс как синонимы[нужна цитата ].
Определение модели
В 1964 году Савицкий и Голай предложили метод, эквивалентный LOESS, который обычно называют Фильтр Савицкого – Голея.Уильям С. Кливленд заново открыл этот метод в 1979 году и дал ему отличное название. Дальнейшее развитие метод получил Кливленд и Сьюзан Дж. Девлин (1988). LOWESS также известен как локально взвешенная полиномиальная регрессия.
В каждой точке диапазона набор данных низкая степень многочлен соответствует подмножеству данных, с объясняющая переменная значения около точки, отклик оценивается. Полином аппроксимируется с помощью взвешенный метод наименьших квадратов, придавая больший вес точкам рядом с точкой, ответ которой оценивается, и меньший вес точкам дальше. Затем значение функции регрессии для точки получается путем оценки локального полинома с использованием значений объясняющих переменных для этой точки данных. Подбор LOESS завершается после того, как значения функции регрессии были вычислены для каждого из точки данных. Многие детали этого метода, такие как степень полиномиальной модели и веса, являются гибкими. Далее вкратце обсуждаются диапазон вариантов для каждой части метода и типичные значения по умолчанию.

Локализованные подмножества данных
В подмножества данных, используемых для каждой взвешенной аппроксимации методом наименьших квадратов в LOESS, определяется алгоритмом ближайших соседей. Указанный пользователем ввод в процедуру, называемый «пропускная способность» или «параметр сглаживания», определяет, какая часть данных используется для соответствия каждому локальному полиному. Параметр сглаживания, , - доля от общего числа п точек данных, которые используются при каждой локальной подгонке. Таким образом, подмножество данных, используемых при каждой аппроксимации методом наименьших квадратов, включает точки (округленные до следующего по величине целого числа), значения независимых переменных которых наиболее близки к точке, в которой оценивается ответ.[6]


Поскольку многочлен степени k требует, по крайней мере (k+1) баллов за подгонку, параметр сглаживания должно быть между и 1, с обозначающая степень локального многочлена.


называется параметром сглаживания, потому что он контролирует гибкость функции регрессии LOESS. Большие значения производят наиболее плавные функции, которые меньше всего колеблются в ответ на колебания данных. Меньший есть, тем ближе функция регрессии будет соответствовать данным. Однако использование слишком малого значения параметра сглаживания нежелательно, поскольку функция регрессии в конечном итоге начнет фиксировать случайную ошибку в данных.
Степень локальных многочленов
Локальные полиномы, подходящие для каждого подмножества данных, почти всегда имеют первую или вторую степень; то есть либо локально линейным (в смысле прямой), либо локально квадратичным. Использование полинома нулевой степени превращает LOESS в взвешенную скользящая средняя. Полиномы более высокой степени будут работать в теории, но дают модели, которые на самом деле не соответствуют духу LOESS. LOESS основан на идеях о том, что любую функцию можно хорошо аппроксимировать в небольшой окрестности полиномом низкого порядка и что простые модели могут быть легко подобраны к данным. Полиномы с высокой степенью будут иметь тенденцию превосходить данные в каждом подмножестве и будут численно нестабильны, что затрудняет точные вычисления.
Весовая функция
Как упоминалось выше, весовая функция дает наибольший вес точкам данных, ближайшим к точке оценки, и наименьший вес - точкам данных, которые находятся дальше всего. Использование весов основано на идее, что точки, расположенные рядом друг с другом в пространстве объясняющих переменных, с большей вероятностью будут связаны друг с другом простым способом, чем точки, которые находятся дальше друг от друга. Следуя этой логике, точки, которые, вероятно, будут соответствовать локальной модели, больше всего влияют на оценки параметров локальной модели. Точки, которые с меньшей вероятностью соответствуют локальной модели, имеют меньшее влияние на локальную модель. параметр оценки.
Традиционной функцией веса, используемой для LOESS, является весовая функция трех кубов,

куда d - это расстояние заданной точки данных от точки аппроксимируемой кривой, масштабируемое так, чтобы лежать в диапазоне от 0 до 1.[6]
Однако можно использовать любую другую весовую функцию, которая удовлетворяет свойствам, перечисленным в Cleveland (1979). Вес для конкретной точки в любом локализованном подмножестве данных получается путем оценки весовой функции на расстоянии между этой точкой и точкой оценки после масштабирования расстояния таким образом, чтобы максимальное абсолютное расстояние по всем точкам в подмножестве данные ровно один.
Рассмотрим следующее обобщение модели линейной регрессии с метрикой на целевом пространстве что зависит от двух параметров, . Предположим, что линейная гипотеза основана на входные параметры и что, как обычно в этих случаях, мы встраиваем входное пространство в в качестве , и рассмотрим следующие функция потерь







Здесь, является вещественная матрица коэффициентов, и нижний индекс я перечисляет входные и выходные векторы из обучающего набора. С является метрикой, это симметричная положительно определенная матрица и, как таковая, существует еще одна симметричная матрица такой, что . Вышеупомянутую функцию потерь можно преобразовать в след, заметив, что . Расположив векторы и в столбцы матрица и матрица соответственно, указанная выше функция потерь может быть записана как














куда это квадратная диагональ матрица, элементами которой являются с. Дифференцируя по и установив результат равным 0, находим экстремальное матричное уравнение




Предполагая далее, что квадратная матрица неособая функция потерь достигает минимума в



Типичный выбор для это Гауссов вес

Преимущества
Как обсуждалось выше, самым большим преимуществом LOESS по сравнению со многими другими методами является то, что процесс подгонки модели к выборочным данным не начинается со спецификации функции. Вместо этого аналитик должен предоставить только значение параметра сглаживания и степень локального полинома. Кроме того, LOESS очень гибок, что делает его идеальным для моделирования сложных процессов, для которых не существует теоретических моделей. Эти два преимущества в сочетании с простотой метода делают LOESS одним из наиболее привлекательных из современных методов регрессии для приложений, которые соответствуют общей структуре регрессии по методу наименьших квадратов, но имеют сложную детерминированную структуру.
Хотя это менее очевидно, чем для некоторых других методов, связанных с линейной регрессией наименьших квадратов, LOESS также дает большую часть преимуществ, которые обычно присущи этим процедурам. Наиболее важным из них является теория вычисления неопределенностей для прогнозирования и калибровки. Многие другие тесты и процедуры, используемые для проверки моделей наименьших квадратов, также могут быть распространены на модели LOESS.[нужна цитата ].
Недостатки
LOESS менее эффективно использует данные, чем другие методы наименьших квадратов. Для создания хороших моделей требуются довольно большие наборы данных с плотной выборкой. Это потому, что LOESS полагается на локальную структуру данных при выполнении локальной подгонки. Таким образом, LOESS обеспечивает менее сложный анализ данных в обмен на более высокие экспериментальные затраты.[6].
Еще одним недостатком LOESS является то, что он не создает функцию регрессии, которую легко представить математической формулой. Это может затруднить передачу результатов анализа другим людям. Чтобы передать функцию регрессии другому человеку, ему потребуется набор данных и программное обеспечение для вычислений LOESS. В нелинейная регрессия, с другой стороны, необходимо только записать функциональную форму, чтобы предоставить оценки неизвестных параметров и оцененную неопределенность. В зависимости от приложения это может быть серьезным или незначительным недостатком использования LOESS. В частности, простая форма LOESS не может использоваться для механистического моделирования, когда подобранные параметры определяют конкретные физические свойства системы.
Наконец, как обсуждалось выше, LOESS - это вычислительно-интенсивный метод (за исключением равномерно распределенных данных, где регрессию затем можно сформулировать как непричинную). конечная импульсная характеристика фильтр). LOESS также подвержен эффектам выбросов в наборе данных, как и другие методы наименьших квадратов. Есть итеративная, крепкий версия LOESS [Cleveland (1979)], которая может использоваться для снижения чувствительности LOESS к выбросы, но слишком много экстремальных выбросов все же может преодолеть даже надежный метод.
Смотрите также
- Степени свободы (статистика) # В нестандартной регрессии
- Регрессия ядра
- Перемещение наименьших квадратов
- Скользящее среднее
- Многомерные сплайны адаптивной регрессии
- Непараметрическая статистика
- Фильтр Савицкого – Голея
- Сегментированная регрессия
Рекомендации
Цитаты
- ^ Фокс и Вайсберг 2018, Приложение.
- ^ Харрелл 2015, п. 29.
- ^ Гаримелла 2017.
- ^ «Фильтрация Савицкого-Голая - MATLAB сголайфильт». Mathworks.com.
- ^ "scipy.signal.savgol_filter - Справочное руководство SciPy v0.16.1". Docs.scipy.org.
- ^ а б c NIST, "МЕНЬШЕ (или МЕНЬШЕ)", раздел 4.1.4.4, Электронный справочник статистических методов NIST / SEMATECH, (по состоянию на 14 апреля 2017 г.)
Источники
- Кливленд, Уильям С. (1979). «Надежная локально взвешенная регрессия и сглаживающие диаграммы рассеяния». Журнал Американской статистической ассоциации. 74 (368): 829–836. Дои:10.2307/2286407. JSTOR 2286407. МИСТЕР 0556476.
- Кливленд, Уильям С. (1981). «LOWESS: программа для сглаживания диаграмм рассеяния с помощью надежной локально взвешенной регрессии». Американский статистик. 35 (1): 54. Дои:10.2307/2683591. JSTOR 2683591.
- Кливленд, Уильям С.; Девлин, Сьюзан Дж. (1988). «Локально-взвешенная регрессия: подход к регрессионному анализу с помощью локальной подгонки». Журнал Американской статистической ассоциации. 83 (403): 596–610. Дои:10.2307/2289282. JSTOR 2289282.
- Фокс, Джон; Вайсберг, Сэнфорд (2018). «Приложение: непараметрическая регрессия в R» (PDF). Компаньон R для прикладной регрессии (3-е изд.). МУДРЕЦ. ISBN 978-1-5443-3645-9.CS1 maint: ref = harv (связь)
- Фридман, Джером Х. (1984). «Сглаживание с переменным диапазоном» (PDF). Лаборатория вычислительной статистики. Технический отчет LCS 5, SLAC PUB-3466. Стэндфордский Университет. Цитировать журнал требует
| журнал =(помощь) - Гаримелла, Рао Вирабхадра (22 июня 2017 г.). «Простое введение в метод метода наименьших квадратов и оценки локальной регрессии». Дои:10.2172/1367799. OSTI 1367799. Цитировать журнал требует
| журнал =(помощь)CS1 maint: ref = harv (связь) - Харрелл, Фрэнк Э., младший (2015). Стратегии регрессионного моделирования: с приложениями к линейным моделям, логистической и порядковой регрессии и анализу выживаемости. Springer. ISBN 978-3-319-19425-7.CS1 maint: ref = harv (связь)
внешняя ссылка
- Локальная регрессия и моделирование выборов
- Сглаживание локальной регрессией: принципы и методы (документ PostScript)
- Раздел Справочника по технической статистике NIST по LOESS
- Программное обеспечение для местной настройки
- Сглаживание точечной диаграммы
- R: аппроксимация локальной полиномиальной регрессии Функция Лесса в р
- R: Сглаживание точечной диаграммы Функция Лоуэса в р
- Функция supsmu (SuperSmoother Фридмана) в R
- Квантиль LOESS - Метод выполнения локальной регрессии на Квантиль движущееся окно (с кодом R)
- Нейт Сильвер, Как меняется мнение об однополых браках и что это значит - выборка LOESS по сравнению с линейной регрессией
Реализации
- Реализация Fortran
- Реализация на C (из проекта R)
- Реализация Lowess в Cython к Карл Фогель
- Реализация Python (в Statsmodels)
- Сглаживание LOESS в Excel
- Реализация LOESS в чистом виде Julia
- Реализация JavaScript
![]() Эта статья включаетматериалы общественного достояния от Национальный институт стандартов и технологий интернет сайт https://www.nist.gov.
Эта статья включаетматериалы общественного достояния от Национальный институт стандартов и технологий интернет сайт https://www.nist.gov.