Простая линейная регрессия - Simple linear regression
| Часть серии по |
| Регрессивный анализ |
|---|
 |
| Модели |
| Оценка |
| Фон |
|

В статистика, простая линейная регрессия это линейная регрессия модель с одиночным объясняющая переменная.[1][2][3][4][5] То есть это касается двумерных точек выборки с одна независимая переменная и одна зависимая переменная (условно Икс и у координаты в Декартова система координат ) и находит линейную функцию (невертикальную прямая линия ), который максимально точно предсказывает значения зависимой переменной как функцию независимой переменной. просто относится к тому факту, что переменная результата связана с одним предиктором.
Обычно делается дополнительное условие, что обыкновенный метод наименьших квадратов (OLS) метод: точность каждого предсказанного значения измеряется его квадратом остаточный (расстояние по вертикали между точкой набора данных и подобранной линией), и цель состоит в том, чтобы как можно меньше сумма этих квадратов отклонений. Другие методы регрессии, которые можно использовать вместо обычных наименьших квадратов, включают наименьшие абсолютные отклонения (минимизируя сумму абсолютных значений остатков) и Оценка Тейла – Сена (который выбирает строку, склон это медиана уклонов, определяемых парами точек выборки). Регрессия Деминга (метод наименьших квадратов) также находит линию, которая соответствует набору двумерных выборочных точек, но (в отличие от обычных наименьших квадратов, наименьших абсолютных отклонений и регрессии среднего наклона) на самом деле это не пример простой линейной регрессии, потому что она не разделять координаты на одну зависимую и одну независимую переменные и потенциально может возвращать вертикальную линию как подходящую.
Остальная часть статьи предполагает обычную регрессию наименьших квадратов. В этом случае наклон подобранной линии равен корреляция между у и Икс корректируется соотношением стандартных отклонений этих переменных. Пересечение подобранной линии таково, что линия проходит через центр масс. (Икс, у) точек данных.
Подгонка линии регрессии
Рассмотрим модель функция

который описывает линию с наклоном β и у-перехват α. В общем, такая взаимосвязь может не соблюдаться в точности для ненаблюдаемой совокупности значений независимых и зависимых переменных; мы называем ненаблюдаемые отклонения от приведенного выше уравнения ошибки. Предположим, мы наблюдаем п пары данных и называть их {(Икся, уя), я = 1, ..., п}. Мы можем описать лежащие в основе отношения между уя и Икся с этим термином ошибки εя к

Эта связь между истинными (но ненаблюдаемыми) базовыми параметрами α и β а точки данных называются моделью линейной регрессии.
Цель - найти оценочные значения и для параметров α и β что в некотором смысле обеспечило бы "наилучшее" соответствие точкам данных. Как упоминалось во введении, в этой статье "наилучшее" соответствие будет пониматься как в наименьших квадратов подход: линия, которая минимизирует сумму квадратов остатки (разница между фактическими и прогнозируемыми значениями зависимой переменной у), каждый из которых задается для любых возможных значений параметров и ,






Другими словами, и решить следующую задачу минимизации:

Расширяя, чтобы получить квадратное выражение в и мы можем получить значения и которые минимизируют целевую функцию Q (эти минимизирующие значения обозначены и ):[6]

![{ displaystyle { begin {align} { widehat { alpha}} & = { bar {y}} - { widehat { beta}} , { bar {x}}, [5pt] { widehat { beta}} & = { frac { sum _ {i = 1} ^ {n} (x_ {i} - { bar {x}}) (y_ {i} - { bar { y}})} { sum _ {i = 1} ^ {n} (x_ {i} - { bar {x}}) ^ {2}}} [6pt] & = { frac {s_ {x, y}} {s_ {x} ^ {2}}} [5pt] & = r_ {xy} { frac {s_ {y}} {s_ {x}}}. [6pt] конец {выровнено}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/944e96221f03e99dbd57290c328b205b0f04c803)
Здесь мы ввели
- и как среднее значение Икся и уя, соответственно
- рху как коэффициент корреляции выборки между Икс и у
- sИкс и sу как нескорректированные стандартные отклонения выборки из Икс и у
- и как выборочная дисперсия и выборочная ковариация, соответственно




Подставляя приведенные выше выражения для и в

дает

Это показывает, что рху - наклон линии регрессии стандартизированный точки данных (и что эта линия проходит через начало координат).
Обобщая обозначение, мы можем написать горизонтальную полосу над выражением, чтобы указать среднее значение этого выражения по набору образцов. Например:

Это обозначение позволяет нам составить краткую формулу для рху:

В коэффициент детерминации («R в квадрате») равно когда модель линейна с единственной независимой переменной. Видеть коэффициент корреляции выборки для получения дополнительных сведений.

Интуитивное объяснение
Умножив все элементы суммирования в числителе на: (тем самым не меняя его):

![{ displaystyle { begin {align} { widehat { beta}} & = { frac { sum _ {i = 1} ^ {n} (x_ {i} - { bar {x}}) ( y_ {i} - { bar {y}})} { sum _ {i = 1} ^ {n} (x_ {i} - { bar {x}}) ^ {2}}} = { frac { sum _ {i = 1} ^ {n} (x_ {i} - { bar {x}}) ^ {2} * { frac {(y_ {i} - { bar {y}}) )} {(x_ {i} - { bar {x}})}}} { sum _ {i = 1} ^ {n} (x_ {i} - { bar {x}}) ^ {2 }}} [6pt] end {выровнено}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/e1ac1b7ef40d1c91a192327f20ae7ca88f4c4d37)
Мы можем видеть, что наклон (тангенс угла) линии регрессии является средневзвешенным значением то есть наклон (тангенс угла) линии, соединяющей i-ю точку со средним значением всех точек, взвешенный как потому что чем дальше точка, тем она «важнее», поскольку небольшие ошибки в ее положении меньше влияют на уклон, соединяющий ее с центральной точкой.


![{ displaystyle { begin {align} { widehat { alpha}} & = { bar {y}} - { widehat { beta}} , { bar {x}}, [5pt] конец {выровнено}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/e5ec3259ace40cc2734621fc00464bc5b87bc3fc)
Данный с угол, который линия составляет с положительной осью x, мы имеем



Простая линейная регрессия без члена пересечения (одиночный регрессор)
Иногда уместно заставить линию регрессии проходить через начало координат, потому что Икс и у считаются пропорциональными. Для модели без члена пересечения у = βx, оценка МНК для β упрощается до

Подстановка (Икс − час, у − k) на месте (Икс, у) дает регресс через (час, k):
![{ displaystyle { begin {align} { widehat { beta}} & = { frac { overline {(xh) (yk)}} { overline {(xh) ^ {2}}}} [6pt] & = { frac {{ overline {xy}} - k { bar {x}} - h { bar {y}} + hk} {{ overline {x ^ {2}}} - 2h { bar {x}} + h ^ {2}}} [6pt] & = { frac {{ overline {xy}} - { bar {x}} { bar {y}} + ({ bar {x}} - h) ({ bar {y}} - k)} {{ overline {x ^ {2}}} - { bar {x}} ^ {2} + ({ bar {x}} - h) ^ {2}}} [6pt] & = { frac { operatorname {Cov} (x, y) + ({ bar {x}} - h) ({ bar {y}} - k)} { operatorname {Var} (x) + ({ bar {x}} - h) ^ {2}}}, end {align}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/79ac025da33096bef180900c9a0bf37ab356900b)
где Cov и Var относятся к ковариации и дисперсии выборочных данных (без поправки на смещение).
Последняя форма выше демонстрирует, как перемещение линии от центра масс точек данных влияет на наклон.
Числовые свойства
- Линия регрессии проходит через центр массы точка, , если модель включает член перехвата (т. е. не проходит через начало координат).
- Сумма остатков равна нулю, если модель включает член пересечения:
- Остатки и Икс значения не коррелированы (независимо от того, есть ли в модели перехватывающий член), что означает:



Свойства на основе модели
Описание статистических свойств оценок на основе оценок простой линейной регрессии требует использования статистическая модель. Следующее основано на предположении о применимости модели, при которой оценки являются оптимальными. Также возможно оценить свойства при других предположениях, таких как неоднородность, но это обсуждается в другом месте.[требуется разъяснение ]
Непредвзятость
Оценщики и находятся беспристрастный.
Чтобы формализовать это утверждение, мы должны определить структуру, в которой эти оценки являются случайными величинами. Рассмотрим остатки εя как случайные величины, полученные независимо от некоторого распределения с нулевым средним. Другими словами, для каждого значения Икс, соответствующее значение у генерируется как средний ответ α + βx плюс дополнительная случайная величина ε называется срок ошибки, в среднем равняется нулю. При такой интерпретации оценки методом наименьших квадратов и сами будут случайными величинами, средние значения которых будут равны "истинным значениям" α и β. Это определение беспристрастной оценки.
Доверительные интервалы
Формулы, приведенные в предыдущем разделе, позволяют рассчитать точечные оценки из α и β - то есть коэффициенты линии регрессии для данного набора данных. Однако эти формулы не говорят нам, насколько точны оценки, то есть насколько они и варьироваться от образца к образцу для указанного размера выборки. Доверительные интервалы были разработаны, чтобы дать правдоподобный набор значений для оценок, которые можно было бы получить, если повторить эксперимент очень большое количество раз.
Стандартный метод построения доверительных интервалов для коэффициентов линейной регрессии основан на предположении нормальности, которое оправдано, если:
- ошибки в регрессии нормально распределенный (так называемой классическая регрессия предположение), или
- количество наблюдений п достаточно велика, и в этом случае оценка приблизительно нормально распределена.
Последний случай оправдан Центральная предельная теорема.
Предположение о нормальности
При первом предположении, приведенном выше, о нормальности членов ошибки, оценка коэффициента наклона сама будет нормально распределена со средним значением β и дисперсия куда σ2 - это дисперсия членов ошибки (см. Доказательства с использованием обыкновенных наименьших квадратов ). При этом сумма квадратов остатков Q распределяется пропорционально χ2 с п − 2 степеней свободы и независимо от . Это позволяет нам построить т-ценить


куда

это стандартная ошибка оценщика .
Этот т-значение имеет Студенты т -распространение с п − 2 степени свободы. Используя его, мы можем построить доверительный интервал для β:
![{ displaystyle beta in left [{ widehat { beta}} - s _ { widehat { beta}} t_ {n-2} ^ {*}, { widehat { beta}} + s_ { widehat { beta}} t_ {n-2} ^ {*} right],}](https://wikimedia.org/api/rest_v1/media/math/render/svg/98a15da255d6643725a6bd9b50d02b3f6c2c497f)
на уровне уверенности (1 − γ), куда это квантиль тп−2 распределение. Например, если γ = 0.05 тогда уровень достоверности 95%.


Аналогично доверительный интервал для коэффициента пересечения α дан кем-то
![{ displaystyle alpha in left [{ widehat { alpha}} - s _ { widehat { alpha}} t_ {n-2} ^ {*}, { widehat { alpha}} + s_ { widehat { alpha}} t_ {n-2} ^ {*} right],}](https://wikimedia.org/api/rest_v1/media/math/render/svg/6085d0ecef794ef2f78a3d3e0f9802acb9a4aada)
на уровне уверенности (1 - γ), куда

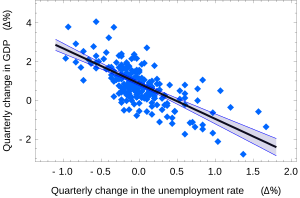
Доверительные интервалы для α и β дают нам общее представление о том, где эти коэффициенты регрессии, скорее всего, будут находиться. Например, в Закон Окуня показана здесь регрессия, точечные оценки

95% доверительные интервалы для этих оценок:
![{ displaystyle alpha in left [, 0,76,0.96 right], qquad beta in left [-2,06, -1,58 , right].}](https://wikimedia.org/api/rest_v1/media/math/render/svg/aca739a7d1ecc8fdddffbdea549b9acba00b464d)
Чтобы представить эту информацию графически в виде доверительных полос вокруг линии регрессии, нужно действовать осторожно и учитывать совместное распределение оценок. Это можно показать[7] что на уровне уверенности (1 -γ) доверительный интервал имеет гиперболический вид, задаваемый уравнением
![{ Displaystyle ( альфа + бета xi) in left [, { widehat { alpha}} + { widehat { beta}} xi pm t_ {n-2} ^ {*} { sqrt { left ({ frac {1} {n-2}} sum { widehat { varepsilon}} _ {i} ^ {, 2} right) cdot left ({ frac {1} {n}} + { frac {( xi - { bar {x}}) ^ {2}} { sum (x_ {i} - { bar {x}}) ^ {2} }}верно-верно].}](https://wikimedia.org/api/rest_v1/media/math/render/svg/7007e876b527e8f59c394898488fd150df4b9f61)
Асимптотическое предположение
Альтернативное второе предположение гласит, что когда количество точек в наборе данных «достаточно велико», закон больших чисел и Центральная предельная теорема становятся применимыми, и тогда распределение оценок приближается к нормальному. При этом предположении все формулы, полученные в предыдущем разделе, остаются в силе, за исключением того, что квантиль т *п−2 из Студенты т распределение заменяется квантилем д * из стандартное нормальное распределение. Иногда фракция 1/п−2 заменяется на 1/п. Когда п такое изменение существенно не меняет результатов.
Числовой пример
Этот набор данных дает среднюю массу тела женщин в зависимости от их роста в выборке американских женщин в возрасте 30–39 лет. Хотя OLS В статье утверждается, что для этих данных было бы более подходящим запустить квадратичную регрессию, вместо этого здесь применяется простая модель линейной регрессии.
Высота (м), Икся 1.47 1.50 1.52 1.55 1.57 1.60 1.63 1.65 1.68 1.70 1.73 1.75 1.78 1.80 1.83 Масса (кг), уя 52.21 53.12 54.48 55.84 57.20 58.57 59.93 61.29 63.11 64.47 66.28 68.10 69.92 72.19 74.46
| 1 | 1.47 | 52.21 | 2.1609 | 76.7487 | 2725.8841 |
| 2 | 1.50 | 53.12 | 2.2500 | 79.6800 | 2821.7344 |
| 3 | 1.52 | 54.48 | 2.3104 | 82.8096 | 2968.0704 |
| 4 | 1.55 | 55.84 | 2.4025 | 86.5520 | 3118.1056 |
| 5 | 1.57 | 57.20 | 2.4649 | 89.8040 | 3271.8400 |
| 6 | 1.60 | 58.57 | 2.5600 | 93.7120 | 3430.4449 |
| 7 | 1.63 | 59.93 | 2.6569 | 97.6859 | 3591.6049 |
| 8 | 1.65 | 61.29 | 2.7225 | 101.1285 | 3756.4641 |
| 9 | 1.68 | 63.11 | 2.8224 | 106.0248 | 3982.8721 |
| 10 | 1.70 | 64.47 | 2.8900 | 109.5990 | 4156.3809 |
| 11 | 1.73 | 66.28 | 2.9929 | 114.6644 | 4393.0384 |
| 12 | 1.75 | 68.10 | 3.0625 | 119.1750 | 4637.6100 |
| 13 | 1.78 | 69.92 | 3.1684 | 124.4576 | 4888.8064 |
| 14 | 1.80 | 72.19 | 3.2400 | 129.9420 | 5211.3961 |
| 15 | 1.83 | 74.46 | 3.3489 | 136.2618 | 5544.2916 |
| 24.76 | 931.17 | 41.0532 | 1548.2453 | 58498.5439 |







Есть п = 15 точек в этом наборе данных. Расчеты вручную начинаются с нахождения следующих пяти сумм:
![{ displaystyle { begin {align} S_ {x} & = sum x_ {i} , = 24,76, qquad S_ {y} = sum y_ {i} , = 931,17, [5pt] S_ {xx} & = sum x_ {i} ^ {2} = 41,0532, ; ; , S_ {yy} = sum y_ {i} ^ {2} = 58498,5439, [5pt] S_ {xy } & = sum x_ {i} y_ {i} = 1548.2453 end {выровнено}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a239d81a6a9897b666146526c8252a18d2603adf)
Эти величины будут использоваться для расчета оценок коэффициентов регрессии и их стандартных ошибок.
![{ displaystyle { begin {align} { widehat { beta}} & = { frac {nS_ {xy} -S_ {x} S_ {y}} {nS_ {xx} -S_ {x} ^ {2 }}} = 61,272 [8pt] { widehat { alpha}} & = { frac {1} {n}} S_ {y} - { widehat { beta}} { frac {1} { n}} S_ {x} = - 39,062 [8pt] s _ { varepsilon} ^ {2} & = { frac {1} {n (n-2)}} left [nS_ {yy} -S_ {y} ^ {2} - { widehat { beta}} ^ {2} (nS_ {xx} -S_ {x} ^ {2}) right] = 0,5762 [8pt] s _ { widehat { beta}} ^ {2} & = { frac {ns _ { varepsilon} ^ {2}} {nS_ {xx} -S_ {x} ^ {2}}} = 3,1539 [8pt] s _ { widehat { alpha}} ^ {2} & = s _ { widehat { beta}} ^ {2} { frac {1} {n}} S_ {xx} = 8,63185 end {выровнено}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/1c171ecde06fcbcb38ea0c3e080b7c14efcfdd96)
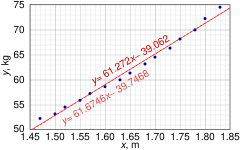
Квантиль Стьюдента 0,975 т-распределение с 13 степенями свободы т*13 = 2.1604, и, следовательно, 95% доверительные интервалы для α и β находятся
![{ displaystyle { begin {align} & alpha in [, { widehat { alpha}} mp t_ {13} ^ {*} s _ { alpha} ,] = [, {- 45,4 }, {-32.7} ,] [5pt] & beta in [, { widehat { beta}} mp t_ {13} ^ {*} s _ { beta} ,] = [, 57.4, 65.1 ,] end {выровнены}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f1e96281c93edfc8cb8e830744328f62081c8010)
В коэффициент корреляции продукт-момент также можно рассчитать:

Этот пример также демонстрирует, что сложные вычисления не преодолеют использование плохо подготовленных данных. Первоначально высота была дана в дюймах и была преобразована в ближайший сантиметр. Поскольку преобразование привело к ошибке округления, это нет точное преобразование. Исходные дюймы могут быть восстановлены округлением (x / 0,0254), а затем преобразованы в метрическую систему без округления: если это будет сделано, результаты станут

Таким образом, кажущиеся небольшими отклонения в данных имеют реальный эффект.
Смотрите также
- Матрица дизайна # Простая линейная регрессия
- Линия фитинга
- Оценка линейного тренда
- Линейная сегментированная регрессия
- Доказательства с использованием обыкновенных наименьших квадратов - вывод всех формул, используемых в статье, в общем многомерном случае
Рекомендации
- ^ Селтман, Ховард Дж. (2008-09-08). Экспериментальный дизайн и анализ (PDF). п. 227.
- ^ «Статистическая выборка и регрессия: простая линейная регрессия». Колумбийский университет. Получено 2016-10-17.
Когда в регрессии используется одна независимая переменная, это называется простой регрессией; (...)
- ^ Лейн, Дэвид М. Введение в статистику (PDF). п. 462.
- ^ Zou KH; Tuncali K; Сильверман С.Г. (2003). «Корреляция и простая линейная регрессия». Радиология. 227 (3): 617–22. Дои:10.1148 / радиол.2273011499. ISSN 0033-8419. OCLC 110941167. PMID 12773666.
- ^ Альтман, Наоми; Кшивинский, Мартин (2015). «Простая линейная регрессия». Методы природы. 12 (11): 999–1000. Дои:10.1038 / nmeth.3627. ISSN 1548-7091. OCLC 5912005539. PMID 26824102.
- ^ Кенни, Дж. Ф. и Кепинг, Э. С. (1962) "Линейная регрессия и корреляция". Гл. 15 дюйм Математика статистики, Pt. 1, 3-е изд. Принстон, Нью-Джерси: Ван Ностранд, стр. 252–285.
- ^ Казелла, Г. и Бергер, Р. Л. (2002), «Статистический вывод» (2-е издание), Cengage, ISBN 978-0-534-24312-8С. 558–559.
внешняя ссылка
- Объяснение Wolfram MathWorld аппроксимации методом наименьших квадратов и того, как его вычислить
- Математика простой регрессии (Роберт Нау, Университет Дьюка)