Студенты т-распределение - Students t-distribution - Wikipedia
Функция плотности вероятности 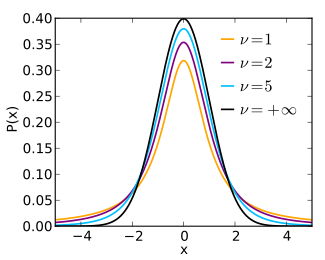 | |||
Кумулятивная функция распределения 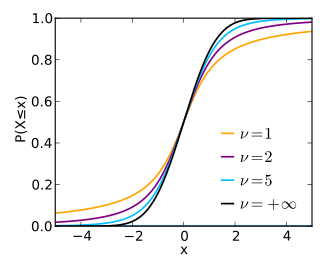 | |||
| Параметры | степени свободы (настоящий ) | ||
|---|---|---|---|
| Поддерживать | |||
| CDF | |||
| Иметь в виду | 0 для , иначе неопределенный | ||
| Медиана | 0 | ||
| Режим | 0 | ||
| Дисперсия | за , ∞ для , иначе неопределенный | ||
| Асимметрия | 0 для , иначе неопределенный | ||
| Бывший. эксцесс | за , ∞ для , иначе неопределенный | ||
| Энтропия |
| ||
| MGF | неопределенный | ||
| CF | за | ||



![begin {matrix}
frac {1} {2} + x Gamma left ( frac { nu + 1} {2} right) times [0.5em]
frac {, _ 2F_1 left ( frac {1} {2}, frac { nu + 1} {2}; frac {3} {2};
- frac {x ^ 2} { nu} right)}
{ sqrt { pi nu} , Gamma left ( frac { nu} {2} right)}
end {матрица}](https://wikimedia.org/api/rest_v1/media/math/render/svg/7c3c84e8f1257dce799724d08e3b08389944045d)








![{ displaystyle { begin {matrix} { frac { nu +1} {2}} left [ psi left ({ frac {1+ nu} {2}} right) - psi left ({ frac { nu} {2}} right) right] [0.5em] + ln { left [{ sqrt { nu}} B left ({ frac { nu } {2}}, { frac {1} {2}} right) right]} , { scriptstyle { text {(nats)}}} end {matrix}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/8e64e6a7fd1bb08a7129701a00f10b4dc673c589)


В вероятность и статистика, Студенты т-распределение (или просто т-распределение) - любой член семейства непрерывных распределения вероятностей которые возникают при оценке иметь в виду из обычно -распределенный численность населения в ситуациях, когда размер образца мало, а население стандартное отклонение неизвестно. Его разработал английский статистик. Уильям Сили Госсет под псевдонимом «Студент».
В т-распределение играет роль в ряде широко используемых статистических анализов, включая Студенты т-тест для оценки Статистическая значимость разницы между двумя выборочными средними, построение доверительные интервалы для разницы между двумя средними значениями совокупности и линейным регрессивный анализ. Студенты т-распределение также возникает в Байесовский анализ данных из нормальной семьи.
Если взять образец наблюдения от нормальное распределение, то т-распространение с степени свободы может быть определено как распределение местоположения выборочного среднего относительно истинного среднего, деленное на стандартное отклонение выборки, после умножения на стандартизирующий член. . Таким образом, т-распределение может быть использовано для построения доверительный интервал для истинного среднего.



В т-распределение симметричное и колоколообразное, как у нормальное распределение, но имеет более тяжелые хвосты, а это означает, что он более склонен к получению значений, далеко выходящих за пределы его среднего. Это делает его полезным для понимания статистического поведения определенных типов соотношений случайных величин, в которых вариация знаменателя усиливается и может давать выпадающие значения, когда знаменатель отношения приближается к нулю. Студенты т-распределение - частный случай обобщенное гиперболическое распределение.
Содержание
- 1 История и этимология
- 2 Как распределение Стьюдента возникает из выборки
- 3 Определение
- 4 Как т-распространение возникает
- 5 Характеристика
- 6 Характеристики
- 7 Обобщенная студенческая т-распределение
- 8 Связанные дистрибутивы
- 9 Использует
- 10 Студенческий t-процесс
- 11 Таблица выбранных значений
- 12 Смотрите также
- 13 Примечания
- 14 Рекомендации
- 15 внешняя ссылка


История и этимология

В статистике т-распределение было впервые получено как апостериорное распределение в 1876 г. Helmert[2][3][4] и Люрот.[5][6][7] В т-распределение также появилось в более общем виде как Пирсон Тип IV распространение в Карл Пирсон Бумага 1895 года.[8]
В англоязычной литературе дистрибутив получил свое название от Уильям Сили Госсет газета 1908 года в Биометрика под псевдонимом «Студент».[9] Госсет работал в Пивоварня Guinness в Дублин, Ирландия, и интересовался проблемами малых образцов - например, химическими свойствами ячменя, где размер выборки может составлять всего 3. Одна версия происхождения псевдонима состоит в том, что работодатель Госсета предпочитал персоналу использовать псевдонимы при публикации научных документы вместо своего настоящего имени, поэтому он использовал имя «Студент», чтобы скрыть свою личность. Другая версия заключается в том, что Guinness не хотел, чтобы их конкуренты знали, что они используют т-тест на определение качества сырья.[10][11]
В статье Госсета это распределение называется «частотным распределением стандартных отклонений выборок, взятых из нормальной совокупности». Это стало хорошо известно благодаря работе Рональд Фишер, который назвал распределение "Распределение Стьюдента" и представил тестовое значение буквой т.[12][13]
Как распределение Стьюдента возникает из выборки
Позволять быть независимо и идентично взятым из распределения , т.е. это образец размером из нормально распределенной популяции с ожидаемым средним значением и дисперсия .




Позволять

быть выборочным средним и пусть

быть (С поправкой на Бесселя ) выборочная дисперсия. Тогда случайная величина

имеет стандартное нормальное распределение (то есть нормальное с ожидаемым средним 0 и дисперсией 1), а случайная величина

куда был заменен на , имеет студенческую т-распространение с степени свободы. Числитель и знаменатель в предыдущем выражении являются независимыми случайными величинами, несмотря на то, что они основаны на одной и той же выборке. .



Определение
Функция плотности вероятности
Студенты т-распределение имеет функция плотности вероятности данный

куда это количество степени свободы и это гамма-функция. Это также можно записать как



где B - Бета-функция. В частности, для целочисленных степеней свободы у нас есть:
За четное,

За странный,

Функция плотности вероятности: симметричный, а его общая форма напоминает форму колокола нормально распределенный переменная со средним 0 и дисперсией 1, за исключением того, что она немного ниже и шире. С ростом числа степеней свободы т-распределение приближается к нормальному со средним 0 и дисперсией 1. По этой причине также известен как параметр нормальности.[14]

На следующих изображениях показана плотность т-распределение для увеличения значений . Нормальное распределение показано синей линией для сравнения. Обратите внимание, что т-распределение (красная линия) становится ближе к нормальному распределению, поскольку увеличивается.
 1 степень свободы |  2 степени свободы | 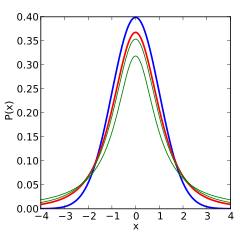 3 степени свободы |
 5 степеней свободы |  10 степеней свободы |  30 степеней свободы |
Кумулятивная функция распределения
В кумулятивная функция распределения можно записать в терминах я, регуляризованныйнеполная бета-функция. За т > 0,[15]

куда

Другие значения были бы получены симметрией. Альтернативная формула, действующая для , является[15]


куда 2F1 частный случай гипергеометрическая функция.
Для получения информации о его обратной кумулятивной функции распределения см. функция квантили § t-распределение Стьюдента.
Особые случаи
Определенные значения придать особенно простую форму.

- Функция распределения:

- Функция плотности:

- Видеть Распределение Коши

- Функция распределения:

- Функция плотности:


- Функция распределения:
![{ displaystyle F (t) = { frac {1} {2}} + { frac {1} { pi}} { left [{ frac {1} { sqrt {3}}} { frac {t} {1 + { frac {t ^ {2}} {3}}}} + arctan left ({ frac {t} { sqrt {3}}} right) right]} .}](https://wikimedia.org/api/rest_v1/media/math/render/svg/3ba20351b7638249b53af24f47925116fb7b06cd)
- Функция плотности:


- Функция распределения:
![{ Displaystyle F (t) = { tfrac {1} {2}} + { frac {3} {8}} { frac {t} { sqrt {1 + { frac {t ^ {2}) } {4}}}}} { left [1 - { frac {1} {12}} { frac {t ^ {2}} {1 + { frac {t ^ {2}} {4}} }}}верно]}.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/802a71e7cdbabfdb35417e6c82320efafccf7bb0)
- Функция плотности:


- Функция распределения:
![{ displaystyle F (t) = { tfrac {1} {2}} + { frac {1} { pi}} { left [{ frac {t} {{ sqrt {5}} left (1 + { frac {t ^ {2}} {5}} right)}} left (1 + { frac {2} {3 left (1 + { frac {t ^ {2}}) {5}} right)}} right) + arctan left ({ frac {t} { sqrt {5}}} right) right]}.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/982c7d491a56bbe056a83f859a77e0e76d6a3a00)
- Функция плотности:


- Функция распределения:
![{ displaystyle F (t) = { frac {1} {2}} { left [1+ operatorname {erf} left ({ frac {t} { sqrt {2}}} right) верно]}.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/2f55580970d8f11e5f6859c932ca13cce474b19a)
- Видеть Функция ошибки
- Функция плотности:

- Видеть Нормальное распределение
Как т-распространение возникает
Выборочное распределение
Позволять быть числами, наблюдаемыми в выборке из непрерывно распределенной совокупности с ожидаемым значением . Среднее значение выборки и выборочная дисперсия даны:


Результирующий t-значение является

В т-распространение с степени свободы выборочное распределение из т-значение, когда образцы состоят из независимые одинаково распределенные наблюдения от нормально распределенный численность населения. Таким образом, для целей вывода т полезный "основное количество "в случае, когда среднее значение и дисперсия - неизвестные параметры популяции в том смысле, что т-значение имеет распределение вероятностей, которое не зависит ни от ни .

Байесовский вывод
В байесовской статистике a (масштабированный, сдвинутый) т-распределение возникает как предельное распределение неизвестного среднего нормального распределения, когда зависимость от неизвестной дисперсии исключена:[16]

куда обозначает данные , и представляет любую другую информацию, которая могла быть использована для создания модели. Таким образом, распределение компаундирование условного распределения учитывая данные и с маргинальным распределением учитывая данные.



С точки данных, если малоинформативный, или квартира, расположение и масштаб приоры и в качестве μ и σ2, тогда Теорема Байеса дает



нормальное распределение и масштабированное обратное распределение хи-квадрат соответственно, где и

Таким образом, интеграл маргинализации становится

Это можно оценить, подставив , куда , давая



так

Но z интеграл теперь является стандартом Гамма-интеграл, который оценивается как константа, оставляя

Это форма т-распределение с явным масштабированием и сдвигом, которое будет рассмотрено более подробно в следующем разделе ниже. Его можно отнести к стандартизированным т-распределение заменой

Приведенный выше вывод был представлен для случая неинформативных априорных значений для и ; но будет очевидно, что любые априорные значения, которые приводят к нормальному распределению, объединенному с масштабированным обратным распределением хи-квадрат, приведут к т-распределение с масштабированием и сдвигом для , хотя параметр масштабирования, соответствующий выше будет зависеть как предварительная информация, так и данные, а не только данные, как указано выше.


Характеристика
Как распределение тестовой статистики
Студенты т-распространение с степеней свободы можно определить как распределение случайная переменная Т с[15][17]

куда
- Z стандартный нормальный с ожидаемое значение 0 и дисперсия 1;
- V имеет распределение хи-квадрат с степени свободы;
- Z и V находятся независимый;
Другое распределение определяется как распределение случайной величины, определенной для данной постоянной μ формулой

Эта случайная величина имеет нецентральный т-распределение с параметр нецентральности μ. Это распределение важно при изучении мощность из студентов т-тест.
Вывод
Предполагать Икс1, ..., Иксп находятся независимый реализации нормально распределенной случайной величины Икс, который имеет математическое ожидание μ и отклонение σ2. Позволять

быть выборочным средним, и

быть беспристрастной оценкой отклонения от выборки. Можно показать, что случайная величина

имеет распределение хи-квадрат с степени свободы (по Теорема Кохрана ).[18] Нетрудно показать, что величина

нормально распределяется со средним 0 и дисперсией 1, поскольку выборочное среднее нормально распределен со средним μ и дисперсией σ2/п. Более того, можно показать, что эти две случайные величины (нормально распределенная Z и хи-квадрат с распределением V) независимы. как следствие[требуется разъяснение ] то основное количество


который отличается от Z в том, что точное стандартное отклонение σ заменяется случайной величиной Sп, имеет студенческую т-распределение, как определено выше. Обратите внимание, что неизвестная дисперсия совокупности σ2 не появляется в Т, так как он был и в числителе, и в знаменателе, поэтому он был отменен. Госсет интуитивно получил функция плотности вероятности указано выше, с равно п - 1, и Фишер доказал это в 1925 году.[12]
Распределение тестовой статистики Т зависит от , но не μ или σ; отсутствие зависимости от μ и σ - вот что делает т-распределение важно как в теории, так и на практике.
Как максимальное распределение энтропии
Студенты т-распределение распределение вероятностей максимальной энтропии для случайной вариации Икс для которого фиксированный.[19][требуется разъяснение ][нужен лучший источник ]

Характеристики
Моменты
За , то сырые моменты из т-распределение
![{ displaystyle operatorname {E} (T ^ {k}) = { begin {cases} 0 & k { text {odd}}, quad 0 <k < nu { frac {1} {{ sqrt { pi}} Gamma left ({ frac { nu} {2}} right)}} left [ Gamma left ({ frac {k + 1} {2}} right) Gamma left ({ frac { nu -k} {2}} right) nu ^ { frac {k} {2}} right] & k { text {even}}, quad 0 < k < nu. конец {случаи}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/876ddf907881d570498829eb97d785812295cf58)
Моменты порядка или выше не существует.[20]
Срок для , k даже, можно упростить, используя свойства гамма-функция к


Для т-распространение с степени свободы, ожидаемое значение равно 0, если , и это отклонение является если . В перекос равно 0, если и избыточный эксцесс является если .


Отбор проб Монте-Карло
Существуют различные подходы к построению случайных выборок из критериев Стьюдента. т-распределение. Вопрос зависит от того, требуются ли образцы на автономной основе или они должны быть построены с применением квантильная функция к униформа образцы; например, в многомерных приложениях на основе связочная зависимость.[нужна цитата ] В случае автономного отбора проб расширение Метод Бокса – Мюллера и это полярная форма легко развертывается.[21] Его достоинство заключается в том, что он одинаково хорошо применим ко всем действительно положительным степени свободы, ν, в то время как многие другие методы-кандидаты терпят неудачу, если ν близко к нулю.[21]
Интеграл функции плотности вероятности Стьюдента и п-ценить
Функция А(т | ν) - интеграл от функции плотности вероятности Стьюдента, ж(т) между -т и т, за т ≥ 0. Это дает вероятность того, что значение т меньше, чем рассчитанное на основе данных наблюдений, может произойти случайно. Следовательно, функция А(т | ν) может использоваться при проверке того, является ли разница между средними значениями двух наборов данных статистически значимой, путем вычисления соответствующего значения т и вероятность его появления, если два набора данных были взяты из одной и той же совокупности. Это используется в различных ситуациях, особенно в т-тесты. Для статистики т, с ν степени свободы, А(т | ν) - вероятность того, что т было бы меньше наблюдаемого значения, если бы два средних значения были одинаковыми (при условии, что меньшее среднее вычитается из большего, так что т ≥ 0). Его легко вычислить из кумулятивная функция распределения Fν(т) из т-распределение:

куда яИкс регуляризованный неполная бета-функция (а, б).
Для проверки статистических гипотез эта функция используется для построения п-ценить.
Обобщенная студенческая т-распределение
По параметру масштабирования или же
Распределение Стьюдента можно обобщить до трех параметров семья в масштабе местности, представляя параметр местоположения и масштабный параметр , через отношение


или же

Это означает, что имеет классическое распределение Стьюдента с степени свободы.

Результирующий нестандартизированный студенческий т-распределение имеет плотность, определяемую:[22]

Здесь, делает нет соответствуют стандартное отклонение: это не стандартное отклонение масштабированного т распространение, которое может даже не существовать; и это не стандартное отклонение базового нормальное распределение, что неизвестно. просто устанавливает общее масштабирование распределения. В байесовском выводе маргинального распределения неизвестного нормального среднего над, здесь соответствует количеству , куда

- .

Эквивалентно, распределение можно записать в терминах , квадрат этого масштабного параметра:

Другие свойства этой версии дистрибутива:[22]

Это распределение является результатом компаундирование а Гауссово распределение (нормальное распределение ) с иметь в виду и неизвестно отклонение, с обратное гамма-распределение размещены над дисперсией с параметрами и . Другими словами, случайная переменная Икс предполагается, что имеет гауссово распределение с неизвестной дисперсией, распределенной как обратная гамма, и тогда дисперсия равна маргинализованный (интегрировано). Причина полезности этой характеристики заключается в том, что обратное гамма-распределение является сопряженный предшествующий распределение дисперсии гауссова распределения. В результате нестандартизированные Студенческие т-распределение естественно возникает во многих задачах байесовского вывода. Смотри ниже.


Эквивалентно, это распределение является результатом сложения гауссова распределения с масштабированное обратное распределение хи-квадрат с параметрами и . Распределение масштабированного обратного хи-квадрат точно такое же, как и обратное гамма-распределение, но с другой параметризацией, т. Е. .

С точки зрения параметра обратного масштабирования λ
Альтернатива параметризация в терминах параметра обратного масштабирования (аналогично способу точность - величина, обратная дисперсии), определяемая соотношением . Тогда плотность определяется как:[23]



Другие свойства этой версии дистрибутива:[23]
![{ displaystyle { begin {align} operatorname {E} (X) & = { hat { mu}} && { text {for}} nu> 1 [5pt] operatorname {var} ( X) & = { frac {1} { lambda}} { frac { nu} { nu -2}} && { text {for}} nu> 2 [5pt] operatorname {mode } (X) & = { hat { mu}} end {align}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/5d718430b8350f0ada28d216c96d8944e72d7e2a)
Это распределение является результатом компаундирование а Гауссово распределение с иметь в виду и неизвестно точность (обратная отклонение ), с гамма-распределение над точностью с параметрами и . Другими словами, случайная величина Икс предполагается, что имеет нормальное распределение с неизвестной точностью, распределяемой как гамма, а затем это маргинализируется по гамма-распределению.

Связанные дистрибутивы
- Если имеет студенческий т-распределение со степенью свободы тогда Икс2 имеет F-распределение:
- В нецентральный т-распределение обобщает т-distribution для включения параметра местоположения. В отличие от нестандартных т-распределения, нецентральные распределения не симметричны (медиана не совпадает с режимом).
- В дискретный студенческий т-распределение определяется его функция массы вероятности в р пропорционально:[24]


- Здесь а, б, и k параметры. Это распределение возникает в результате построения системы дискретных распределений, аналогичных распределению Распределения Пирсона для непрерывных распределений.[25]

- Можно сгенерировать выборки Стьюдента, взяв отношение переменных из нормальное распределение и квадратный корень из χ2-распределение. Если использовать вместо нормального распределения, например, Распределение Ирвина – Холла, мы получаем в целом симметричное 4-параметрическое распределение, которое включает нормаль, униформа, то треугольный, Студент-т и Распределение Коши. Это также более гибко, чем некоторые другие симметричные обобщения нормального распределения.
- т-дистрибутив является экземпляром соотношения распределения
Использует
В частотном статистическом выводе
Студенты т-распределение возникает в различных задачах статистической оценки, где целью является оценка неизвестного параметра, такого как среднее значение, в условиях, когда данные наблюдаются с добавлением ошибки. Если (как почти во всех практических статистических работах) население стандартное отклонение этих ошибок неизвестно и должно быть оценено на основе данных, т-распределение часто используется для учета дополнительной неопределенности, возникающей в результате этой оценки. В большинстве таких задач, если было известно стандартное отклонение ошибок, нормальное распределение будет использоваться вместо т-распределение.
Доверительные интервалы и проверка гипотез две статистические процедуры, в которых квантили выборочного распределения конкретной статистики (например, стандартная оценка ) необходимы. В любой ситуации, когда эта статистика линейная функция из данные, разделенное на обычную оценку стандартного отклонения, полученная величина может быть изменена и центрирована в соответствии с оценкой Стьюдента. т-распределение. Статистический анализ, включающий средние, взвешенные средние и коэффициенты регрессии, все приводит к статистике, имеющей такую форму.
Довольно часто в задачах из учебников стандартное отклонение совокупности рассматривается так, как если бы оно было известно, и тем самым избегает необходимости использовать т-распределение. Эти проблемы обычно бывают двух видов: (1) те, в которых размер выборки настолько велик, что можно рассматривать основанную на данных оценку отклонение как если бы это было достоверно, и (2) те, которые иллюстрируют математические рассуждения, в которых проблема оценки стандартного отклонения временно игнорируется, потому что это не тот момент, который затем объясняет автор или преподаватель.
Проверка гипотезы
Можно показать, что ряд статистических т-распределения для выборок среднего размера под нулевые гипотезы которые представляют интерес, так что т-распределение формирует основу для тестов значимости. Например, распределение Коэффициент ранговой корреляции Спирмена ρ, в нулевом случае (нулевая корреляция) хорошо аппроксимируется т распределение для размеров выборки более 20.[нужна цитата ]
Доверительные интервалы
Предположим, что число А так выбрано, что

когда Т имеет т-распространение с п - 1 степень свободы. По симметрии это то же самое, что сказать, что А удовлетворяет

так А это "95-й процентиль" этого распределения вероятностей, или . потом


и это эквивалентно

Следовательно, интервал, конечные точки которого

составляет 90% доверительный интервал для μ. Следовательно, если мы найдем среднее значение набора наблюдений, которое, как мы можем разумно ожидать, будет иметь нормальное распределение, мы можем использовать т-распределение для проверки того, включают ли доверительные границы этого среднего значения теоретически предсказанное значение, такое как значение, предсказанное на нулевая гипотеза.
Именно этот результат используется в Студенты т-тесты: поскольку разница между средними значениями выборок из двух нормальных распределений сама по себе распределяется нормально, т-распределение можно использовать, чтобы проверить, можно ли обоснованно предположить, что эта разница равна нулю.
Если данные распределены нормально, односторонний (1 - α) -Верхний доверительный предел (ВПД) среднего, можно рассчитать с помощью следующего уравнения:

Результирующий UCL будет наибольшим средним значением, которое будет иметь место для данного доверительного интервала и размера популяции. Другими словами, будучи средним значением набора наблюдений, вероятность того, что среднее значение распределения уступает UCL1−α равно доверительной вероятности 1 - α.
Интервалы прогноза
В т-распределение может быть использовано для построения интервал прогноза для ненаблюдаемой выборки из нормального распределения с неизвестным средним значением и дисперсией.
В байесовской статистике
Студенты т-распределение, особенно в его трехпараметрической версии (шкала местоположения), часто возникает в Байесовская статистика в результате его связи с нормальное распределение. Когда бы отклонение нормально распределенного случайная переменная неизвестно и сопряженный предшествующий помещенный над ним, который следует обратное гамма-распределение, результирующий предельное распределение переменной будет следовать за студентом т-распределение. Эквивалентные конструкции с одинаковыми результатами включают сопряженное масштабированное обратное распределение хи-квадрат над дисперсией или сопряженным гамма-распределение над точность. Если неподходящий предварительный пропорционально σ−2 помещается над дисперсией, т-распространение тоже возникает. Это имеет место независимо от того, известно ли среднее значение нормально распределенной переменной, неизвестно ли распределено в соответствии с сопрягать нормально распределенный предшествующий или неизвестный распределенный согласно неправильному постоянному предшествующему.
Связанные ситуации, которые также вызывают т-распространение бывают:
- В маргинальный апостериорное распределение неизвестного среднего значения нормально распределенной переменной с неизвестным априорным средним и дисперсией в соответствии с описанной выше моделью.
- В предварительное прогнозное распределение и апостериорное прогнозирующее распределение новой нормально распределенной точки данных, когда серия независимые одинаково распределенные наблюдались нормально распределенные точки данных с предварительным средним значением и дисперсией, как в приведенной выше модели.
Надежное параметрическое моделирование
В т-распределение часто используется как альтернатива нормальному распределению в качестве модели данных, которая часто имеет более тяжелые хвосты, чем допускает нормальное распределение; см. например Lange et al.[26] Классический подход заключался в выявлении выбросы (например, используя Тест Граббса ) и каким-либо образом исключить или уменьшить их вес. Однако не всегда легко выявить выбросы (особенно в высокие размеры ), а т-распределение является естественным выбором модели для таких данных и обеспечивает параметрический подход к надежная статистика.
Байесовское описание можно найти в работе Gelman et al.[27] Параметр степеней свободы контролирует эксцесс распределения и коррелирует с параметром масштаба. Вероятность может иметь несколько локальных максимумов, и поэтому часто необходимо фиксировать степени свободы на довольно низком значении и оценивать другие параметры, принимая это как заданное. Некоторые авторы[нужна цитата ] Сообщите, что значения от 3 до 9 часто являются хорошим выбором. Венейблс и Рипли[нужна цитата ] предполагают, что значение 5 часто является хорошим выбором.
Студенческий t-процесс
Для практических регресс и прогноз потребностей, были введены t-процессы Стьюдента, которые являются обобщениями t-распределений Стьюдента для функций. T-процесс Стьюдента строится из t-распределений Стьюдента как Гауссовский процесс построен из Гауссовы распределения. Для Гауссовский процесс, все наборы значений имеют многомерное распределение Гаусса. Аналогично, является t-процессом Стьюдента на интервале если соответствующие значения процесса () иметь совместный многомерное t-распределение Стьюдента.[28] Эти процессы используются для регрессии, прогнозирования, байесовской оптимизации и связанных с ними задач. Для многомерной регрессии и прогнозирования с несколькими выходами вводятся и используются многомерные t-процессы Стьюдента.[29]

![I = [a, b]](https://wikimedia.org/api/rest_v1/media/math/render/svg/6d6214bb3ce7f00e496c0706edd1464ac60b73b5)


Таблица выбранных значений
В следующей таблице перечислены значения для т-распределения с ν степенями свободы для диапазона односторонний или же двусторонний критические регионы. Первый столбец - это ν, проценты вверху - это уровни достоверности, а числа в теле таблицы - это факторы, описанные в разделе о доверительные интервалы.

Примечание что последняя строка с бесконечным ν дает критические точки для нормального распределения, поскольку т-распределение с бесконечным числом степеней свободы - нормальное распределение. (Видеть Связанные дистрибутивы над).
| Односторонний | 75% | 80% | 85% | 90% | 95% | 97.5% | 99% | 99.5% | 99.75% | 99.9% | 99.95% |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Двусторонний | 50% | 60% | 70% | 80% | 90% | 95% | 98% | 99% | 99.5% | 99.8% | 99.9% |
| 1 | 1.000 | 1.376 | 1.963 | 3.078 | 6.314 | 12.71 | 31.82 | 63.66 | 127.3 | 318.3 | 636.6 |
| 2 | 0.816 | 1.080 | 1.386 | 1.886 | 2.920 | 4.303 | 6.965 | 9.925 | 14.09 | 22.33 | 31.60 |
| 3 | 0.765 | 0.978 | 1.250 | 1.638 | 2.353 | 3.182 | 4.541 | 5.841 | 7.453 | 10.21 | 12.92 |
| 4 | 0.741 | 0.941 | 1.190 | 1.533 | 2.132 | 2.776 | 3.747 | 4.604 | 5.598 | 7.173 | 8.610 |
| 5 | 0.727 | 0.920 | 1.156 | 1.476 | 2.015 | 2.571 | 3.365 | 4.032 | 4.773 | 5.893 | 6.869 |
| 6 | 0.718 | 0.906 | 1.134 | 1.440 | 1.943 | 2.447 | 3.143 | 3.707 | 4.317 | 5.208 | 5.959 |
| 7 | 0.711 | 0.896 | 1.119 | 1.415 | 1.895 | 2.365 | 2.998 | 3.499 | 4.029 | 4.785 | 5.408 |
| 8 | 0.706 | 0.889 | 1.108 | 1.397 | 1.860 | 2.306 | 2.896 | 3.355 | 3.833 | 4.501 | 5.041 |
| 9 | 0.703 | 0.883 | 1.100 | 1.383 | 1.833 | 2.262 | 2.821 | 3.250 | 3.690 | 4.297 | 4.781 |
| 10 | 0.700 | 0.879 | 1.093 | 1.372 | 1.812 | 2.228 | 2.764 | 3.169 | 3.581 | 4.144 | 4.587 |
| 11 | 0.697 | 0.876 | 1.088 | 1.363 | 1.796 | 2.201 | 2.718 | 3.106 | 3.497 | 4.025 | 4.437 |
| 12 | 0.695 | 0.873 | 1.083 | 1.356 | 1.782 | 2.179 | 2.681 | 3.055 | 3.428 | 3.930 | 4.318 |
| 13 | 0.694 | 0.870 | 1.079 | 1.350 | 1.771 | 2.160 | 2.650 | 3.012 | 3.372 | 3.852 | 4.221 |
| 14 | 0.692 | 0.868 | 1.076 | 1.345 | 1.761 | 2.145 | 2.624 | 2.977 | 3.326 | 3.787 | 4.140 |
| 15 | 0.691 | 0.866 | 1.074 | 1.341 | 1.753 | 2.131 | 2.602 | 2.947 | 3.286 | 3.733 | 4.073 |
| 16 | 0.690 | 0.865 | 1.071 | 1.337 | 1.746 | 2.120 | 2.583 | 2.921 | 3.252 | 3.686 | 4.015 |
| 17 | 0.689 | 0.863 | 1.069 | 1.333 | 1.740 | 2.110 | 2.567 | 2.898 | 3.222 | 3.646 | 3.965 |
| 18 | 0.688 | 0.862 | 1.067 | 1.330 | 1.734 | 2.101 | 2.552 | 2.878 | 3.197 | 3.610 | 3.922 |
| 19 | 0.688 | 0.861 | 1.066 | 1.328 | 1.729 | 2.093 | 2.539 | 2.861 | 3.174 | 3.579 | 3.883 |
| 20 | 0.687 | 0.860 | 1.064 | 1.325 | 1.725 | 2.086 | 2.528 | 2.845 | 3.153 | 3.552 | 3.850 |
| 21 | 0.686 | 0.859 | 1.063 | 1.323 | 1.721 | 2.080 | 2.518 | 2.831 | 3.135 | 3.527 | 3.819 |
| 22 | 0.686 | 0.858 | 1.061 | 1.321 | 1.717 | 2.074 | 2.508 | 2.819 | 3.119 | 3.505 | 3.792 |
| 23 | 0.685 | 0.858 | 1.060 | 1.319 | 1.714 | 2.069 | 2.500 | 2.807 | 3.104 | 3.485 | 3.767 |
| 24 | 0.685 | 0.857 | 1.059 | 1.318 | 1.711 | 2.064 | 2.492 | 2.797 | 3.091 | 3.467 | 3.745 |
| 25 | 0.684 | 0.856 | 1.058 | 1.316 | 1.708 | 2.060 | 2.485 | 2.787 | 3.078 | 3.450 | 3.725 |
| 26 | 0.684 | 0.856 | 1.058 | 1.315 | 1.706 | 2.056 | 2.479 | 2.779 | 3.067 | 3.435 | 3.707 |
| 27 | 0.684 | 0.855 | 1.057 | 1.314 | 1.703 | 2.052 | 2.473 | 2.771 | 3.057 | 3.421 | 3.690 |
| 28 | 0.683 | 0.855 | 1.056 | 1.313 | 1.701 | 2.048 | 2.467 | 2.763 | 3.047 | 3.408 | 3.674 |
| 29 | 0.683 | 0.854 | 1.055 | 1.311 | 1.699 | 2.045 | 2.462 | 2.756 | 3.038 | 3.396 | 3.659 |
| 30 | 0.683 | 0.854 | 1.055 | 1.310 | 1.697 | 2.042 | 2.457 | 2.750 | 3.030 | 3.385 | 3.646 |
| 40 | 0.681 | 0.851 | 1.050 | 1.303 | 1.684 | 2.021 | 2.423 | 2.704 | 2.971 | 3.307 | 3.551 |
| 50 | 0.679 | 0.849 | 1.047 | 1.299 | 1.676 | 2.009 | 2.403 | 2.678 | 2.937 | 3.261 | 3.496 |
| 60 | 0.679 | 0.848 | 1.045 | 1.296 | 1.671 | 2.000 | 2.390 | 2.660 | 2.915 | 3.232 | 3.460 |
| 80 | 0.678 | 0.846 | 1.043 | 1.292 | 1.664 | 1.990 | 2.374 | 2.639 | 2.887 | 3.195 | 3.416 |
| 100 | 0.677 | 0.845 | 1.042 | 1.290 | 1.660 | 1.984 | 2.364 | 2.626 | 2.871 | 3.174 | 3.390 |
| 120 | 0.677 | 0.845 | 1.041 | 1.289 | 1.658 | 1.980 | 2.358 | 2.617 | 2.860 | 3.160 | 3.373 |
| ∞ | 0.674 | 0.842 | 1.036 | 1.282 | 1.645 | 1.960 | 2.326 | 2.576 | 2.807 | 3.090 | 3.291 |
| Односторонний | 75% | 80% | 85% | 90% | 95% | 97.5% | 99% | 99.5% | 99.75% | 99.9% | 99.95% |
| Двусторонний | 50% | 60% | 70% | 80% | 90% | 95% | 98% | 99% | 99.5% | 99.8% | 99.9% |
Расчет доверительного интервала
Скажем, у нас есть выборка с размером 11, выборочным средним 10 и выборочной дисперсией 2. Для 90% достоверности с 10 степенями свободы одностороннее t-значение из таблицы составляет 1,372. Тогда с доверительным интервалом, рассчитанным из

мы определяем, что с вероятностью 90% истинное среднее значение находится ниже

Другими словами, в 90% случаев, когда верхний порог вычисляется этим методом на основе конкретных выборок, этот верхний порог превышает истинное среднее значение.
И с вероятностью 90% у нас есть истинное среднее значение, лежащее выше

Другими словами, в 90% случаев, когда нижний порог вычисляется этим методом на основе конкретных выборок, этот нижний порог находится ниже истинного среднего значения.
Таким образом, при 80% достоверности (рассчитанной из 100% - 2 × (1 - 90%) = 80%) у нас есть истинное среднее значение, лежащее в интервале

Сказать, что в 80% случаев, когда верхний и нижний пороги вычисляются этим методом на основе данной выборки, истинное среднее значение оказывается как ниже верхнего, так и выше нижнего порога, не то же самое, что утверждать, что существует 80% -ная вероятность того, что истинное среднее значение находится между конкретной парой верхнего и нижнего пороговых значений, рассчитанных этим методом; видеть доверительный интервал и ошибка прокурора.
В настоящее время статистическое программное обеспечение, такое как Язык программирования R, и функции, доступные во многих электронные таблицы вычислить значения т-распределение и его обратное без таблиц.
Смотрите также
- Z-распределительная таблица
- Распределение хи-квадрат
- F-распределение
- Гамма-распределение
- Сложенныйт и наполовинут распределения
- Хотеллинга Т-квадратное распределение
- Многомерное распределение студентов
- т-статистический
- Тау-распределение, за внутренне студентизированные остатки
- Лямбда-распределение Уилкса
- Распределение Уишарта
Примечания
- ^ Херст, Саймон. Характеристическая функция распределения Стьюдента, Отчет об исследовании финансовой математики № FMRR006-95, Отчет о статистическом исследовании № SRR044-95 В архиве 18 февраля 2010 г. Wayback Machine
- ^ Гельмерт FR (1875). "Über die Berechnung des wahrscheinlichen Fehlers aus einer endlichen Anzahl wahrer Beobachtungsfehler". Z. Math. U. Physik. 20: 300–3.
- ^ Гельмерт FR (1876 г.). "Uber die Wahrscheinlichkeit der Potenzsummen der Beobachtungsfehler und uber einige damit в Zusammenhang stehende Fragen". Z. Math. Phys. 21: 192–218.
- ^ Гельмерт FR (1876 г.). "Die Genauigkeit der Formel von Peters zur Berechnung des wahrscheinlichen Beobachtungsfehlers directer Beobachtungen gleicher Genauigkeit" [Точность формулы Петерса для расчета вероятной ошибки наблюдения прямых наблюдений такой же точности] (PDF). Astron. Nachr. (на немецком). 88 (8–9): 113–132. Bibcode:1876AN ..... 88..113H. Дои:10.1002 / asna.18760880802.
- ^ Люрот Дж (1876 г.). "Vergleichung von zwei Werten des wahrscheinlichen Fehlers". Astron. Nachr. 87 (14): 209–20. Bibcode:1876AN ..... 87..209L. Дои:10.1002 / asna.18760871402.
- ^ Пфанзагл Дж, Шейнин О (1996). «Исследования по истории вероятности и статистики. XLIV. Предшественник t-распределения». Биометрика. 83 (4): 891–898. Дои:10.1093 / biomet / 83.4.891. МИСТЕР 1766040.
- ^ Шейнин О. (1995). «Работа Гельмерта по теории ошибок». Arch. Hist. Exact Sci. 49 (1): 73–104. Дои:10.1007 / BF00374700.
- ^ Пирсон, К. (1895-01-01). "Вклад в математическую теорию эволюции. II. Косые вариации в однородном материале". Философские труды Королевского общества A: математические, физические и инженерные науки. 186: 343–414 (374). Дои:10.1098 / рста.1895.0010. ISSN 1364-503X.
- ^ "Ученик" [Уильям Сили Госсет ] (1908). «Вероятная ошибка среднего» (PDF). Биометрика. 6 (1): 1–25. Дои:10.1093 / biomet / 6.1.1. HDL:10338.dmlcz / 143545. JSTOR 2331554.
- ^ Wendl MC (2016). «Псевдонимная слава». Наука. 351 (6280): 1406. Дои:10.1126 / science.351.6280.1406. PMID 27013722.
- ^ Мортимер Р.Г. (2005). Математика для физической химии (3-е изд.). Берлингтон, Массачусетс: Elsevier. стр.326. ISBN 9780080492889. OCLC 156200058.
- ^ а б Фишер Р.А. (1925). «Приложения« Студенческой »раздачи» (PDF). Метрон. 5: 90–104. Архивировано из оригинал (PDF) 5 марта 2016 г.
- ^ Уолпол Р.Э., Майерс Р., Майерс С. и др. (2006). Вероятность и статистика для инженеров и ученых (7-е изд.). Нью-Дели: Пирсон. п. 237. ISBN 9788177584042. OCLC 818811849.
- ^ Крушке Ю.К. (2015). Проведение байесовского анализа данных (2-е изд.). Академическая пресса. ISBN 9780124058880. OCLC 959632184.
- ^ а б c Джонсон Н.Л., Коц С., Балакришнан Н. (1995). «Глава 28». Непрерывные одномерные распределения. 2 (2-е изд.). Вайли. ISBN 9780471584940.
- ^ Гельман А.Б., Карлин Дж. С., Рубин Д. Б. и др. (1997). Байесовский анализ данных (2-е изд.). Бока-Ратон: Чепмен и Холл. п. 68. ISBN 9780412039911.
- ^ Hogg RV, Крейг А.Т. (1978). Введение в математическую статистику (4-е изд.). Нью-Йорк: Макмиллан. КАК В B010WFO0SA. Разделы 4.4 и 4.8
- ^ Кокран РГ (1934). «Распределение квадратичных форм в нормальной системе с приложениями к анализу ковариации». Математика. Proc. Camb. Филос. Soc. 30 (2): 178–191. Bibcode:1934PCPS ... 30..178C. Дои:10.1017 / S0305004100016595.
- ^ Парк С.Ю., Бера АК (2009). «Модель условной гетероскедастичности авторегрессии максимальной энтропии». J. Econom. 150 (2): 219–230. Дои:10.1016 / j.jeconom.2008.12.014.
- ^ Казелла Г., Бергер Р.Л. (1990). Статистические выводы. Ресурсный центр Даксбери. п. 56. ISBN 9780534119584.
- ^ а б Бейли Р.В. (1994). "Полярное генерирование случайных величин с помощью т-Распределение". Математика. Comput. 62 (206): 779–781. Дои:10.2307/2153537. JSTOR 2153537.
- ^ а б Джекман, С. (2009). Байесовский анализ для социальных наук. Вайли. п.507. Дои:10.1002/9780470686621. ISBN 9780470011546.
- ^ а б Бишоп, К. (2006). Распознавание образов и машинное обучение. Нью-Йорк, штат Нью-Йорк: Springer. ISBN 9780387310732.
- ^ Ord JK (1972). Семейства частотных распределений. Лондон: Гриффин. ISBN 9780852641378. См. Таблицу 5.1.
- ^ Орд JK (1972). «Глава 5». Семейства частотных распределений. Лондон: Гриффин. ISBN 9780852641378.
- ^ Ланге К.Л., Литтл Р.Дж., Тейлор Дж. М. (1989). «Надежное статистическое моделирование с использованием т Распределение" (PDF). Варенье. Стат. Доц. 84 (408): 881–896. Дои:10.1080/01621459.1989.10478852. JSTOR 2290063.
- ^ Гельман А.Б., Карлин Дж.Б., Стерн Х.С. и др. (2014). «Вычислительно эффективное моделирование цепи Маркова». Байесовский анализ данных. Бока-Ратон, Флорида: CRC Press. п. 293. ISBN 9781439898208.
- ^ Шах, Амар; Уилсон, Эндрю Гордон; Гахрамани, Зубин (2014). «Студенческие t-процессы как альтернатива гауссовским процессам» (PDF). JMLR. 33 (Материалы 17-й Международной конференции по искусственному интеллекту и статистике (AISTATS) 2014, Рейкьявик, Исландия): 877–885.
- ^ Чен, Зексун; Ван, Бо; Горбань, Александр Н. (2019). «Многомерная гауссова регрессия и регрессия Стьюдента для прогнозирования с несколькими выходами». Нейронные вычисления и приложения. arXiv:1703.04455. Дои:10.1007 / s00521-019-04687-8.
Рекомендации
- Senn, S .; Ричардсон, В. (1994). "Первый т-тест". Статистика в медицине. 13 (8): 785–803. Дои:10.1002 / sim.4780130802. PMID 8047737.
- Hogg RV, Крейг А.Т. (1978). Введение в математическую статистику (4-е изд.). Нью-Йорк: Макмиллан. КАК В B010WFO0SA.
- Venables, W. N .; Рипли, Б. Д. (2002). Современная прикладная статистика с S (Четвертое изд.). Springer.
- Гельман, Андрей; Джон Б. Карлин; Хэл С. Стерн; Дональд Б. Рубин (2003). Байесовский анализ данных (второе издание). CRC / Chapman & Hall. ISBN 1-58488-388-X.
внешняя ссылка
- «Студенческое распределение», Энциклопедия математики, EMS Press, 2001 [1994]
- Самые ранние известные варианты использования некоторых слов математики (S) (Замечания по истории возникновения термина «Студенческое распределение»)
- Руо, М. (2013), Вероятность, статистика и оценка (PDF) (короткое изд.) Первые студенты на странице 112.