Биномиальное распределение - Binomial distribution
Вероятностная функция масс 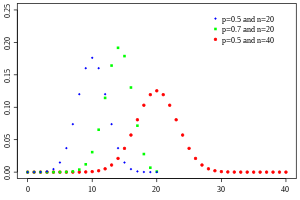 | |||
Кумулятивная функция распределения 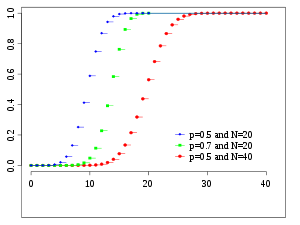 | |||
| Обозначение | |||
|---|---|---|---|
| Параметры | - количество испытаний - вероятность успеха для каждого испытания | ||
| Поддерживать | - количество успехов | ||
| PMF | |||
| CDF | |||
| Иметь в виду | |||
| Медиана | или же | ||
| Режим | или же | ||
| Дисперсия | |||
| Асимметрия | |||
| Бывший. эксцесс | |||
| Энтропия | в Shannons. За нац, используйте естественный журнал в журнале. | ||
| MGF | |||
| CF | |||
| PGF | |||
| Информация Fisher | (для фиксированных ) | ||


![{значок стиля отображения [0,1]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/33c3a52aa7b2d00227e85c641cca67e85583c43c)















![{displaystyle G (z) = [q + pz] ^ {n}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/40494c697ce2f88ebb396ac0191946285cadcbdd)




с п и k как в Треугольник Паскаля
Вероятность того, что мяч в Ящик гальтона с 8 слоями (п = 8) попадает в центральную корзину (k = 4) является .

В теория вероятности и статистика, то биномиальное распределение с параметрами п и п это дискретное распределение вероятностей количества успехов в последовательности п независимый эксперименты, каждый спрашивает да – нет вопроса, и каждый со своим Булево -значен исход: успех (с вероятностью п) или же отказ (с вероятностью q = 1 − п). Единичный эксперимент успеха / неудачи также называется Бернулли суд или эксперимент Бернулли, а последовательность результатов называется Процесс Бернулли; для одного испытания, т.е. п = 1, биномиальное распределение есть Распределение Бернулли. Биномиальное распределение является основой популярного биномиальный тест из Статистическая значимость.
Биномиальное распределение часто используется для моделирования количества успехов в выборке размером п нарисованный с заменой от большой популяции N. Если выборка выполняется без замены, розыгрыши не являются независимыми, и поэтому результирующее распределение является гипергеометрическое распределение, а не биномиальный. Однако для N намного больше, чем п, биномиальное распределение остается хорошим приближением и широко используется.
Определения
Вероятностная функция масс
В общем, если случайная переменная Икс следует биномиальному распределению с параметрами п ∈ ℕ и п ∈ [0,1], запишем Икс ~ B (п, п). Вероятность получить ровно k успехи в п независимые испытания Бернулли даны функция массы вероятности:

за k = 0, 1, 2, ..., п, куда

это биномиальный коэффициент, отсюда и название раздачи. Формулу можно понять так: k успех случается с вероятностью пk и п − k отказы происходят с вероятностью (1 -п)п − k. Тем не менее k успех может произойти где угодно среди п испытания, и есть разные способы распространения k успехов в последовательности п испытания.

При создании справочных таблиц для вероятностей биномиального распределения обычно таблица заполняется до п/ 2 значения. Это потому, что для k > п/ 2, вероятность вычисляется по его дополнению как

Глядя на выражение ж(k, п, п) как функция k, Существует k значение, которое максимизирует его. Этот k значение можно найти, вычислив

и сравнивая его с 1. Всегда есть целое число M это удовлетворяет[1]

ж(k, п, п) монотонно возрастает при k < M и монотонно убывает при k > M, за исключением случая, когда (п + 1)п целое число. В этом случае есть два значения, для которых ж максимальное: (п + 1)п и (п + 1)п − 1. M это наиболее вероятно исход (то есть наиболее вероятный, хотя в целом он все еще может быть маловероятным) испытаний Бернулли и называется Режим.
Пример
Предположим, что предвзятая монета выпадает орел с вероятностью 0,3 при подбрасывании. Вероятность увидеть ровно 4 решки за 6 бросков равна

Кумулятивная функция распределения
В кумулятивная функция распределения можно выразить как:

куда это "пол" под k, т.е. наибольшее целое число меньше или равно k.

Его также можно представить в виде регуляризованная неполная бета-функция, следующее:[2]

что эквивалентно кумулятивная функция распределения из F-распределение:[3]

Даны некоторые оценки в закрытом виде для кумулятивной функции распределения. ниже.
Характеристики
Ожидаемое значение и отклонение
Если Икс ~ B(п, п), то есть, Икс является биномиально распределенной случайной величиной, где n - общее количество экспериментов, а p - вероятность того, что каждый эксперимент даст успешный результат, тогда ожидаемое значение из Икс является:[4]
![{displaystyle operatorname {E} [X] = np.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/3f16b365410a1b23b5592c53d3ae6354f1a79aff)
Это следует из линейности математического ожидания и того факта, что Икс это сумма п идентичные случайные величины Бернулли, каждая с ожидаемым значением п. Другими словами, если являются идентичными (и независимыми) случайными величинами Бернулли с параметром п, тогда и


![{displaystyle operatorname {E} [X] = operatorname {E} [X_ {1} + cdots + X_ {n}] = operatorname {E} [X_ {1}] + cdots + operatorname {E} [X_ {n} ] = p + cdots + p = np.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/5f238d520c68a1d1b9b318492ddda39f4cc45bb8)
В отклонение является:

Это аналогично следует из того факта, что дисперсия суммы независимых случайных величин является суммой дисперсий.
Высшие моменты
Первые 6 центральных моментов даются

Режим
Обычно Режим бинома B(п, п) распределение равно , куда это функция пола. Однако когда (п + 1)п целое число и п не равно ни 0, ни 1, то распределение имеет два режима: (п + 1)п и (п + 1)п - 1. Когда п равно 0 или 1, режим будет 0 и п соответственно. Эти случаи можно резюмировать следующим образом:


Доказательство: Позволять

За Только имеет ненулевое значение с . За мы нашли и за . Это доказывает, что режим равен 0 для и за .







Позволять . Мы нашли

- .

Из этого следует

Так когда целое число, тогда и это режим. В случае, если то только это режим.[5]




Медиана
В общем, не существует единой формулы для определения медиана для биномиального распределения, и оно может быть даже неуникальным. Однако было установлено несколько особых результатов:
- Если нп является целым числом, тогда среднее значение, медиана и мода совпадают и равны нп.[6][7]
- Любая медиана м должно лежать в интервале ⌊нп⌋ ≤ м ≤ ⌈нп⌉.[8]
- Медиана м не может лежать слишком далеко от среднего: |м − нп| ≤ min {ln 2, max {п, 1 − п} }.[9]
- Медиана уникальна и равна м = круглый (нп) когда |м − нп| ≤ min {п, 1 − п} (кроме случая, когда п = 1/2 и п нечетно).[8]
- Когда п = 1/2 и п нечетное, любое число м в интервале 1/2(п − 1) ≤ м ≤ 1/2(п + 1) - медиана биномиального распределения. Если п = 1/2 и п четно, тогда м = п/ 2 - единственная медиана.
Границы хвоста
За k ≤ нп, верхние границы могут быть получены для нижнего хвоста кумулятивной функции распределения вероятность того, что существует не более k успехов. С , эти границы также можно рассматривать как границы для верхнего хвоста кумулятивной функции распределения для k ≥ нп.


Неравенство Хёффдинга дает простую оценку

что, однако, не очень плотно. В частности, для п = 1, имеем F(k;п,п) = 0 (для фиксированного k, п с k < п), но оценка Хёффдинга дает положительную константу.
Более точную оценку можно получить из Граница Чернова:[10]

куда D(а || п) это относительная энтропия между а-коина и п-coin (то есть между Бернулли (а) и Бернулли (п) распределение):

Асимптотически эта граница достаточно жесткая; видеть [10] для подробностей.
Также можно получить ниже границы на хвосте , известный как границы антиконцентрации. Аппроксимируя биномиальный коэффициент формулой Стирлинга, можно показать, что[11]


откуда следует более простая, но более слабая оценка

За п = 1/2 и k ≥ 3п/ 8 для четных п, можно сделать знаменатель постоянным:[12]

Статистические выводы
Оценка параметров
Когда п известно, параметр п можно оценить, используя долю успехов: Эта оценка находится с использованием оценщик максимального правдоподобия а также метод моментов. Эта оценка беспристрастный и равномерно с минимальная дисперсия, доказано использование Теорема Лемана – Шеффе, поскольку он основан на минимально достаточный и полный статистика (например: Икс). Это также последовательный как по вероятности, так и по MSE.

Закрытая форма Байесовская оценка за п также существует при использовании Бета-распределение как сопрягать предварительное распространение. При использовании общего как и прежде, заднее среднее оценщик: . Оценка Байеса асимптотически эффективный и по мере приближения размера выборки к бесконечности (п → ∞), она приближается к MLE решение. Оценка Байеса пристрастный (сколько зависит от приоры), допустимый и последовательный по вероятности.


Для особого случая использования стандартное равномерное распределение как неинформативный приор () апостериорная средняя оценка принимает вид (а задний режим должен просто привести к стандартной оценке). Этот метод называется правило наследования, который был введен в 18 веке Пьер-Симон Лаплас.


При оценке п с очень редкими событиями и маленьким п (например: если x = 0), то использование стандартной оценки приводит к что иногда бывает нереально и нежелательно. В таких случаях существуют различные альтернативные оценки.[13] Один из способов - использовать байесовскую оценку, что приведет к: ). Другой метод - использовать верхнюю границу доверительный интервал полученный с использованием правило трех: )



Доверительные интервалы
Даже для достаточно больших значений п, фактическое распределение среднего существенно ненормально.[14] Из-за этой проблемы было предложено несколько методов оценки доверительных интервалов.
В приведенных ниже уравнениях для доверительных интервалов переменные имеют следующее значение:
- п1 количество успехов из п, общее количество испытаний
- доля успехов
- это квантиль из стандартное нормальное распределение (т.е. пробит ), соответствующий целевой частоте ошибок . Например, для уровня достоверности 95% ошибка = 0,05, поэтому = 0,975 и = 1.96.




Метод Вальда

- А исправление непрерывности 0,5 /п могут быть добавлены.[требуется разъяснение ]
Метод Агрести – Коулла

- Здесь оценка п изменен на

Арксинус метод

Метод Вильсона (оценка)
Обозначения в приведенной ниже формуле отличаются от предыдущих формул в двух отношениях:[17]
- Во-первых, zИкс имеет несколько иное толкование в приведенной ниже формуле: оно имеет обычное значение Иксквантиль стандартного нормального распределения ', а не сокращение' (1 -Икс) -й квантиль '.
- Во-вторых, в этой формуле не используется знак «плюс-минус» для определения двух границ. Вместо этого можно использовать чтобы получить нижнюю границу, или используйте чтобы получить верхнюю границу. Например: для уровня достоверности 95% ошибка = 0,05, поэтому нижнюю границу можно получить, используя , а верхнюю границу можно получить, используя .





Сравнение
Точный (Клоппер – Пирсон ) метод является наиболее консервативным.[14]
Метод Вальда, хотя его часто рекомендуют в учебниках, является наиболее предвзятым.[требуется разъяснение ]
Связанные дистрибутивы
Суммы биномов
Если Икс ~ B (п, п) и Y ~ B (м, п) - независимые биномиальные переменные с одинаковой вероятностью п, тогда Икс + Y снова является биномиальной переменной; его распространение Z = X + Y ~ B (п + м, п):
![{начало {выровнено} имя оператора {P} (Z = k) & = sum _ {i = 0} ^ {k} left [{inom {n} {i}} p ^ {i} (1-p) ^ { ni} ight] left [{inom {m} {ki}} p ^ {ki} (1-p) ^ {m-k + i} ight] & = {inom {n + m} {k}} p ^ {k} (1-p) ^ {n + mk} конец {выровнено}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/38fc38e9a5e2c49743f45b4dab5dae6230ab2ad5)
Однако если Икс и Y не имеют такой же вероятности п, то дисперсия суммы будет меньше, чем дисперсия биномиальной переменной распространяется как

Соотношение двух биномиальных распределений
Этот результат был впервые получен Кацем и соавторами в 1978 году.[19]
Позволять Икс ~ B (п,п1) и Y ~ B (м,п2) быть независимым. Позволять Т = (Икс/п)/(Y/м).
Затем войдите (Т) приблизительно нормально распределяется со средним логарифмом (п1/п2) и дисперсии ((1 /п1) − 1)/п + ((1/п2) − 1)/м.
Условные биномы
Если Икс ~ B (п, п) и Y | Икс ~ B (Икс, q) (условное распределение Y, данныйИкс), тогда Y простая биномиальная случайная величина с распределением Y ~ B (п, pq).
Например, представьте, что бросаете п мячи в корзину UИкс и забирая попавшие шары и бросая их в другую корзину UY. Если п вероятность попадания UИкс тогда Икс ~ B (п, п) - количество шаров, попавших в UИкс. Если q вероятность попадания UY затем количество шаров, которые попали UY является Y ~ B (Икс, q) и поэтому Y ~ B (п, pq).
С и , посредством закон полной вероятности,


![{displaystyle {egin {выровнено} Pr [Y = m] & = sum _ {k = m} ^ {n} Pr [Y = mmid X = k] Pr [X = k] [2pt] & = sum _ { k = m} ^ {n} {inom {n} {k}} {inom {k} {m}} p ^ {k} q ^ {m} (1-p) ^ {nk} (1-q) ^ {km} конец {выровнено}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/7e8f896e04f3bc2c13d2eed61e48bd43e63f6406)
С приведенное выше уравнение можно выразить как

![{displaystyle Pr [Y = m] = sum _ {k = m} ^ {n} {inom {n} {m}} {inom {nm} {km}} p ^ {k} q ^ {m} (1 -p) ^ {nk} (1-q) ^ {km}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/8369ef846ffda72900efc67b334923f70ce48ca5)
Факторинг и вытаскивая все термины, которые не зависят от из суммы теперь дает


![{displaystyle {egin {выравнивается} Pr [Y = m] & = {inom {n} {m}} p ^ {m} q ^ {m} left (sum _ {k = m} ^ {n} {inom { nm} {km}} p ^ {km} (1-p) ^ {nk} (1-q) ^ {km} ight) [2pt] & = {inom {n} {m}} (pq) ^ {m} влево (сумма _ {k = m} ^ {n} {inom {nm} {km}} left (p (1-q) ight) ^ {km} (1-p) ^ {nk} ight) конец {выровнен}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/caaa36dbcb3b4c43d7d5310533ef9d4809ba9db8)
После замены в приведенном выше выражении мы получаем

![{displaystyle Pr [Y = m] = {inom {n} {m}} (pq) ^ {m} left (sum _ {i = 0} ^ {nm} {inom {nm} {i}} (p- pq) ^ {i} (1-p) ^ {nmi} ight)}](https://wikimedia.org/api/rest_v1/media/math/render/svg/54401b2dd0936ca0904832912df2fe9b2c3d5153)
Обратите внимание, что сумма (в скобках) выше равна посредством биномиальная теорема. Подставив это в finally, дает

![{displaystyle {egin {выровнено} Pr [Y = m] & = {inom {n} {m}} (pq) ^ {m} (p-pq + 1-p) ^ {nm} [4pt] & = {inom {n} {m}} (pq) ^ {m} (1-pq) ^ {nm} конец {выровнено}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/324b106ed5f362da979eebfc0feaa94b44b713b2)
и поэтому по желанию.

Распределение Бернулли
В Распределение Бернулли является частным случаем биномиального распределения, где п = 1. Символически, Икс ~ B (1,п) имеет то же значение, что и Икс ~ Бернулли (п). Наоборот, любое биномиальное распределение B (п, п), является распределением суммы п Бернулли испытания, Бернулли (п), каждый с одинаковой вероятностью п.[20]
Биномиальное распределение Пуассона
Биномиальное распределение - это частный случай Биномиальное распределение Пуассона, или же общее биномиальное распределение, которое представляет собой распределение суммы п независимый неидентичный Бернулли испытания B (пя).[21]
Нормальное приближение

Если п достаточно велико, то перекос распределения не слишком велик. В этом случае разумное приближение к B (п, п) дается нормальное распределение

и это базовое приближение можно легко улучшить, используя подходящую исправление непрерывности Базовое приближение обычно улучшается как п увеличивается (минимум на 20) и лучше, когда п не близко к 0 или 1.[22] Разные эмпирические правила может использоваться, чтобы решить, п достаточно большой, и п достаточно далеко от крайних значений нуля или единицы:
- Одно правило[22] это для п > 5 нормальное приближение является адекватным, если абсолютное значение асимметрии строго меньше 1/3; то есть, если

- Более сильное правило гласит, что нормальное приближение подходит только в том случае, если все в пределах 3 стандартных отклонений от его среднего находится в пределах диапазона возможных значений; то есть, только если
- Это правило трех стандартных отклонений эквивалентно следующим условиям, которые также подразумевают первое правило выше.


Правило полностью эквивалентен запросу, что


Перемещение терминов по доходности:

С , мы можем применить квадратную степень и разделить на соответствующие множители и , чтобы получить желаемые условия:


Обратите внимание, что эти условия автоматически подразумевают, что . С другой стороны, снова примените квадратный корень и разделите на 3,


Вычитание второго набора неравенств из первого дает:

Итак, желаемое первое правило выполнено,

- Другое часто используемое правило состоит в том, что оба значения и должно быть больше или равно 5. Однако конкретное число варьируется от источника к источнику и зависит от того, насколько хорошее приближение требуется. В частности, если использовать 9 вместо 5, правило подразумевает результаты, указанные в предыдущих параграфах.

Предположим, что оба значения и больше 9. Поскольку , мы легко получаем, что

Нам осталось только разделить на соответствующие факторы и , чтобы вывести альтернативную форму правила трех стандартных отклонений:


Ниже приводится пример применения исправление непрерывности. Предположим, кто-то хочет вычислить Pr (Икс ≤ 8) для биномиальной случайной величины Икс. Если Y имеет распределение, задаваемое нормальным приближением, то Pr (Икс ≤ 8) аппроксимируется Pr (Y ≤ 8,5). Добавление 0,5 - это поправка на непрерывность; нескорректированное нормальное приближение дает значительно менее точные результаты.
Это приближение, известное как Теорема де Муавра – Лапласа, значительно экономит время при выполнении расчетов вручную (точные расчеты с большими п очень обременительны); исторически это было первое использование нормального распределения, введенное в Абрахам де Муавр книга Доктрина шансов в 1738 году. В настоящее время его можно рассматривать как следствие Центральная предельная теорема поскольку B (п, п) представляет собой сумму п независимые, одинаково распределенные Переменные Бернулли с параметромп. Этот факт лежит в основе проверка гипотез, "z-критерий пропорции" для значения п с помощью х / п, доля выборки и оценка п, в общая тестовая статистика.[23]
Например, предположим, что один случайный выбор п людей из большой популяции и спросите их, согласны ли они с определенным утверждением. Доля согласных, конечно, будет зависеть от выборки. Если группы п люди отбирались многократно и действительно случайным образом, пропорции следовали бы приблизительному нормальному распределению со средним значением, равным истинной пропорции п согласия среди населения и со стандартным отклонением

Пуассоновское приближение
Биномиальное распределение сходится к распределение Пуассона поскольку количество попыток стремится к бесконечности, пока продукт нп остается фиксированным или по крайней мере п стремится к нулю. Следовательно, распределение Пуассона с параметром λ = нп можно использовать как приближение к B (п, п) биномиального распределения, если п достаточно большой и п достаточно мала. Согласно двум практическим правилам это приближение хорошо, если п ≥ 20 и п ≤ 0,05, или если п ≥ 100 и нп ≤ 10.[24]
Относительно точности пуассоновского приближения см. Новак,[25] гл. 4 и ссылки в нем.
Ограничивающие распределения
- Предельная теорема Пуассона: В качестве п приближается к ∞ и п приближается к 0 с продуктом нп фиксируется, биномиальный (п, п) распределение приближается к распределение Пуассона с ожидаемое значение λ = np.[24]
- Теорема де Муавра – Лапласа: В качестве п приближается к ∞, а п остается фиксированным, распределение

- приближается к нормальное распределение с ожидаемым значением 0 и отклонение 1.[нужна цитата ] Иногда этот результат вольно выражается, говоря, что распределение Икс является асимптотически нормальный с ожидаемой стоимостьюнп и отклонение нп(1 − п). Этот результат является частным случаем Центральная предельная теорема.
Бета-распределение
Биномиальное распределение и бета-распределение - это разные взгляды на одну и ту же модель повторных испытаний Бернулли. Биномиальное распределение - это PMF из k достигнутые успехи п независимые события каждое с вероятностью п успеха. Математически, когда α = k + 1 и β = п − k + 1, бета-распределение и биномиальное распределение связаны коэффициентом п + 1:

Бета-распределения также предоставить семью априорные распределения вероятностей для биномиальных распределений в Байесовский вывод:[26]

При однородном априорном распределении апостериорного распределения вероятности успеха п данный п независимые мероприятия с k наблюдаемые успехи - это бета-распределение.[27]
Вычислительные методы
Генерация биномиальных случайных величин
Методы для генерация случайных чисел где предельное распределение является биномиальным распределением.[28][29]
Один из способов генерировать случайные выборки из биномиального распределения - использовать алгоритм инверсии. Для этого необходимо вычислить вероятность того, что Pr (Икс = k) для всех значений k из 0 через п. (Эти вероятности должны суммироваться до значения, близкого к единице, чтобы охватить все пространство выборки.) Затем, используя генератор псевдослучайных чисел чтобы сгенерировать выборки равномерно между 0 и 1, можно преобразовать вычисленные выборки в дискретные числа, используя вероятности, вычисленные на первом этапе.
История
Это распределение было получено Джейкоб Бернулли. Он рассмотрел случай, когда п = р/(р + s) куда п вероятность успеха и р и s положительные целые числа. Блез Паскаль ранее рассматривал случай, когда п = 1/2.
Смотрите также
- Логистическая регрессия
- Мультиномиальное распределение
- Отрицательное биномиальное распределение
- Бета-биномиальное распределение
- Биномиальная мера, пример мультифрактал мера.[30]
- Статистическая механика
Рекомендации
- ^ Феллер, В. (1968). Введение в теорию вероятностей и ее приложения (Третье изд.). Нью-Йорк: Вили. п.151 (теорема в разделе VI.3).
- ^ Уодсворт, Г. П. (1960). Введение в вероятность и случайные переменные. Нью-Йорк: Макгроу-Хилл. п.52.
- ^ Джоуэтт, Г. Х. (1963). «Связь между биномиальным и F-распределениями». Журнал Королевского статистического общества D. 13 (1): 55–57. Дои:10.2307/2986663. JSTOR 2986663.
- ^ Видеть Доказательство вики
- ^ Смотрите также Николя, Андре (7 января 2019 г.). «Режим поиска в биномиальном распределении». Обмен стеком.
- ^ Нойман, П. (1966). "Uber den Median der Binomial- and Poissonverteilung". Wissenschaftliche Zeitschrift der Technischen Universität Dresden (на немецком). 19: 29–33.
- ^ Господи, Ник. (Июль 2010 г.). "Биномиальные средние, когда среднее целое число", Математический вестник 94, 331-332.
- ^ а б Kaas, R .; Бурман, Дж. М. (1980). «Среднее, медиана и мода в биномиальных распределениях». Statistica Neerlandica. 34 (1): 13–18. Дои:10.1111 / j.1467-9574.1980.tb00681.x.
- ^ Хамза, К. (1995). «Наименьшая равномерная верхняя граница расстояния между средним и медианой биномиального распределения и распределения Пуассона». Письма о статистике и вероятности. 23: 21–25. Дои:10.1016 / 0167-7152 (94) 00090-У.
- ^ а б Arratia, R .; Гордон, Л. (1989). «Учебник по большим отклонениям для биномиального распределения». Вестник математической биологии. 51 (1): 125–131. Дои:10.1007 / BF02458840. PMID 2706397. S2CID 189884382.
- ^ Роберт Б. Эш (1990). Теория информации. Dover Publications. п.115.
- ^ Matoušek, J .; Вондрак, Дж. «Вероятностный метод» (PDF). конспект лекций.
- ^ Раззаги, Мехди (2002). «Об оценке биномиальной вероятности успеха при нулевом появлении в выборке». Журнал современных прикладных статистических методов. 1 (2): 326–332. Дои:10.22237 / jmasm / 1036110000.
- ^ а б Браун, Лоуренс Д .; Кай, Т. Тони; ДасГупта, Анирбан (2001), «Интервальная оценка биномиальной пропорции», Статистическая наука, 16 (2): 101–133, CiteSeerX 10.1.1.323.7752, Дои:10.1214 / сс / 1009213286, получено 2015-01-05
- ^ Агрести, Алан; Коулл, Брент А. (май 1998 г.), «Приблизительное лучше, чем« точное »для интервальной оценки биномиальных пропорций» (PDF), Американский статистик, 52 (2): 119–126, Дои:10.2307/2685469, JSTOR 2685469, получено 2015-01-05
- ^ Пирес, М.А. (2002). «Доверительные интервалы для биномиальной пропорции: сравнение методов и оценка программного обеспечения» (PDF). В Klinke, S .; Ahrend, P .; Рихтер, Л. (ред.). Материалы конференции CompStat 2002. Краткие сообщения и плакаты.
- ^ Уилсон, Эдвин Б. (июнь 1927 г.), «Вероятный вывод, закон последовательности и статистический вывод» (PDF), Журнал Американской статистической ассоциации, 22 (158): 209–212, Дои:10.2307/2276774, JSTOR 2276774, заархивировано из оригинал (PDF) на 2015-01-13, получено 2015-01-05
- ^ «Доверительные интервалы». Справочник по инженерной статистике. NIST / Sematech. 2012 г.. Получено 2017-07-23.
- ^ Кац, Д .; и другие. (1978). «Получение доверительных интервалов для отношения рисков в когортных исследованиях». Биометрия. 34 (3): 469–474. Дои:10.2307/2530610. JSTOR 2530610.
- ^ Табога, Марко. «Лекции по теории вероятностей и математической статистике». statlect.com. Получено 18 декабря 2017.
- ^ Ван, Ю. Х. (1993). «О количестве успехов в независимых исследованиях» (PDF). Statistica Sinica. 3 (2): 295–312. Архивировано из оригинал (PDF) на 03.03.2016.
- ^ а б Коробка, Охотник и Охотник (1978). Статистика для экспериментаторов. Вайли. п.130.
- ^ NIST /SEMATECH, «7.2.4. Соответствует ли доля брака требованиям?» Электронный справочник статистических методов.
- ^ а б NIST /SEMATECH, «6.3.3.1. Графики контроля подсчета», Электронный справочник статистических методов.
- ^ Новак С.Ю. (2011) Экстремальные методы ценности с приложениями к финансам. Лондон: CRC / Chapman & Hall / Taylor & Francis. ISBN 9781-43983-5746.
- ^ Маккей, Дэвид (2003). Теория информации, логические выводы и алгоритмы обучения. Издательство Кембриджского университета; Первое издание. ISBN 978-0521642989.
- ^ https://www.statlect.com/probability-distributions/beta-distribution
- ^ Деврой, Люк (1986) Генерация неоднородной случайной величины, Нью-Йорк: Springer-Verlag. (См. Особенно Глава X, Дискретные одномерные распределения )
- ^ Качитвичянукуль, В .; Шмайзер, Б. В. (1988). «Генерация биномиальных случайных величин». Коммуникации ACM. 31 (2): 216–222. Дои:10.1145/42372.42381. S2CID 18698828.
- ^ Мандельброт, Б. Б., Фишер, А. Дж., И Кальвет, Л. Е. (1997). Мультифрактальная модель доходности активов. 3.2. Биномиальная мера - простейший пример мультифрактала.
дальнейшее чтение
- Хирш, Вернер З. (1957). «Биномиальное распределение - успех или неудача, насколько они вероятны?». Введение в современную статистику. Нью-Йорк: Макмиллан. С. 140–153.
- Нетер, Джон; Вассерман, Уильям; Уитмор, Г. А. (1988). Прикладная статистика (Третье изд.). Бостон: Аллин и Бэкон. С. 185–192. ISBN 0-205-10328-6.
внешняя ссылка
- Интерактивная графика: Одномерные отношения распределения
- Калькулятор формулы биномиального распределения
- Разница двух биномиальных переменных: X-Y или же | X-Y |
- Запрос биномиального распределения вероятностей в WolframAlpha