Фиктивная переменная (статистика) - Dummy variable (statistics)
В статистика и эконометрика, особенно в регрессивный анализ, а фиктивная переменная[а] это тот, который принимает только значение 0 или 1, чтобы указать на отсутствие или наличие некоторого категориального эффекта, который, как можно ожидать, изменит результат.[2][3] Их можно рассматривать как числовые замены для качественный факты в регрессионная модель, сортировка данных в взаимоисключающий категории (например, курящий и некурящий).[4]
Манекен независимая переменная (также называемая фиктивной объясняющей переменной), которая для некоторых наблюдений имеет значение 0, приведет к тому, что эта переменная коэффициент не иметь роли во влиянии на зависимая переменная, в то время как когда манекен принимает значение 1, его коэффициент действует, чтобы изменить перехватить. Например, предположим, что членство в группе является одной из качественных переменных, относящихся к регрессии. Если членству в группе произвольно присвоено значение 1, тогда все остальные получат значение 0. Тогда перехват будет постоянным членом для нечленов, но будет постоянным членом плюс коэффициент фиктивной принадлежности членства в случае группы члены.[5]
Фиктивные переменные часто используются в анализ временных рядов с переключением режимов, сезонным анализом и приложениями качественных данных.
Включение манекена независимого

Фиктивные переменные включаются так же, как количественные переменные (в качестве независимых переменных) в регрессионные модели. Например, если мы рассмотрим Мясорубка регрессионная модель определения заработной платы, в которой заработная плата зависит от пола (качественно) и продолжительности образования (количественно):

куда это срок ошибки. В модели женский = 1, если человек - женщина и женский = 0, когда человек мужчина. можно интерпретировать как разницу в заработной плате мужчин и женщин при неизменном уровне образования. Таким образом, δ0 помогает определить, существует ли дискриминация в оплате труда мужчин и женщин. Например, если δ0> 0 (положительный коэффициент), то женщины получают более высокую заработную плату, чем мужчины (при сохранении других факторов постоянными). Коэффициенты, прикрепленные к фиктивным переменным, называются дифференциальные коэффициенты пересечения. Модель можно изобразить графически как перехватывающий сдвиг между самками и самцами. На рисунке случай δ0Показано <0 (при этом мужчины получают более высокую заработную плату, чем женщины).[6]


Фиктивные переменные могут быть расширены на более сложные случаи. Например, сезонные эффекты могут быть зафиксированы путем создания фиктивных переменных для каждого из сезонов: если наблюдение для лета, и равно нулю в противном случае; тогда и только тогда, когда осень, иначе равно нулю; тогда и только тогда, когда зима, иначе равно нулю; и тогда и только тогда, когда пружина, иначе равняется нулю. в данные панели, оценщик фиксированных эффектов манекены создаются для каждого из юнитов в данные поперечного сечения (например, фирмы или страны) или периоды в объединенном временном ряду. Однако в таких регрессиях либо постоянный срок должен быть удален или один из манекенов должен быть удален, при этом связанная с ним категория становится базовой категорией, по которой оцениваются другие, чтобы избежать ловушка фиктивной переменной:




Постоянный член во всех уравнениях регрессии - это коэффициент, умноженный на регрессор, равный единице. Когда регрессия выражается в виде матричного уравнения, матрица регрессоров состоит из столбца единиц (постоянный член), векторов нулей и единиц (фиктивные числа) и, возможно, других регрессоров. Если, скажем, включать и мужские, и женские манекены, сумма этих векторов будет вектором единиц, поскольку каждое наблюдение подразделяется на мужские или женские. Таким образом, эта сумма равна регрессору постоянного члена, первому вектору единиц. В результате уравнение регрессии будет неразрешимым даже с помощью типичного псевдообратного метода. Другими словами: если присутствуют и регрессор вектора единиц (постоянный член), и исчерпывающий набор фиктивных переменных, идеальный мультиколлинеарность происходит,[7] и система уравнений, образованная регрессией, не имеет единственного решения. Это называется ловушка фиктивной переменной. Ловушки можно избежать, удалив либо постоянный член, либо один из вызывающих нарушение манекенов. Удаленный макет становится базовой категорией, с которой сравниваются другие категории.
Модели ANOVA
Модель регрессии, в которой зависимая переменная является количественной по своей природе, но все объясняющие переменные являются фиктивными (качественными по своей природе), называется моделью. Анализ отклонений (ANOVA) модель.[4]
Модель ANOVA с одной качественной переменной
Предположим, мы хотим провести регрессию, чтобы выяснить, различается ли средняя годовая зарплата учителей государственных школ в трех географических регионах в стране A с 51 штатом: (1) Север (21 штат) (2) Юг (17 штатов) (3) Запад (13 штатов). Предположим, что простая арифметическая средняя заработная плата выглядит следующим образом: 24 424,14 доллара (север), 22 894 доллара (юг), 26 158,62 доллара (запад). Среднеарифметические значения разные, но отличаются ли они друг от друга статистически? Чтобы сравнить средние значения, Анализ отклонений регрессионная модель может быть определена как:
- ,

куда
- средняя годовая зарплата учителей государственных школ в штате i
- если государство я находится в Северном регионе
- в противном случае (любой регион кроме Севера)
- если государство я находится в Южном регионе
- иначе





В этой модели у нас есть только качественные регрессоры, принимающие значение 1, если наблюдение относится к определенной категории, и 0, если оно принадлежит к любой другой категории. Это делает его моделью ANOVA.

Теперь, принимая ожидание обеих сторон, получаем следующее:
Средняя заработная плата учителей государственных школ в Северном регионе:
E (Yя|D2я = 1, D3я = 0) = α1 + α2
Средняя заработная плата учителей государственных школ Южного региона:
E (Yя| D2i = 0, D3i = 1) = α1 + α3
Средняя заработная плата учителей государственных школ в Западном регионе:
E (Yя| D2i = 0, D3i = 0) = α1
(Термин ошибки не включается в ожидаемые значения, поскольку предполагается, что он удовлетворяет обычным OLS условий, т.е.E (uя) = 0)
Ожидаемые значения можно интерпретировать следующим образом: Средняя зарплата учителей государственных школ на Западе равна перехватываемому члену α1 в уравнении множественной регрессии и дифференциальных коэффициентах пересечения, α2 и α3, объясните, насколько средняя заработная плата учителей в Северном и Южном регионах отличается от заработной платы учителей на Западе. Таким образом, средняя заработная плата учителей на Севере и Юге составляет в сравнении против средней зарплаты учителей на Западе. Следовательно, Западный регион становится базовая группа или эталонная группа, то есть группа, с которой производятся сравнения. В пропущенная категорият. е. категория, которой не назначен манекен, принимается в качестве категории основной группы.
Используя указанные данные, результатом регрессии будет:
- Ŷя = 26 158,62 - 1734,473 дн.2я - 3264.615D3я
se = (1128,523) (1435,953) (1499,615)
т = (23,1759) (-1,2078) (-2,1776)
р = (0,0000) (0,2330) (0,0349)
р2 = 0.0901
где se = стандартная ошибка, т = t-статистика, п = значение p
Результат регрессии можно интерпретировать следующим образом: Средняя зарплата учителей на Западе (базовая группа) составляет около 26 158 долларов, зарплата учителей на Севере ниже примерно на 1734 доллара (26 158,62 долларов - 1734 473 доллара = 24 424,14 доллара, что является средней зарплатой). учителей на Севере) и учителей на Юге ниже примерно на 3265 долларов (26 158,62 доллара - 3264,615 доллара = 22 894 доллара, что является средней зарплатой учителей на Юге).
Чтобы выяснить, отличаются ли средние зарплаты учителей на Севере и Юге статистически от зарплат учителей на Западе (категория сравнения), мы должны выяснить, равны ли коэффициенты наклона результата регрессии статистически значимый. Для этого необходимо учитывать п значения. Расчетный коэффициент наклона для Севера статистически не значим, так как его п значение составляет 23 процента; тем не менее, показатель Юга статистически значим на уровне 5%, поскольку его п значение составляет всего около 3,5%. Таким образом, общий результат состоит в том, что средние зарплаты учителей на Западе и Севере статистически не отличаются друг от друга, но средняя заработная плата учителей на Юге статистически ниже, чем на Западе, примерно на 3265 долларов. Модель схематически показана на рисунке 2. Эта модель представляет собой модель ANOVA с одной качественной переменной, имеющей 3 категории.[4]
Модель ANOVA с двумя качественными переменными
Предположим, мы рассматриваем модель ANOVA, имеющую две качественные переменные, каждая из которых имеет две категории: почасовая заработная плата должна быть объяснена с точки зрения качественных переменных Семейное положение (женат / не женат) и географический регион (север / не-север). Здесь семейное положение и географический регион являются двумя независимыми фиктивными переменными.[4]
Скажем, результат регрессии на основе некоторых заданных данных выглядит следующим образом:
- Ŷя = 8,8148 + 1,0997D2 - 1,6729D3
куда,
- Y = почасовая оплата (в $)
- D2 = семейное положение, 1 = замужем, 0 = иначе
- D3 = географический регион, 1 = север, 0 = иначе
В этой модели каждой качественной переменной присваивается одна фиктивная переменная, на единицу меньше, чем количество категорий, включенных в каждую.
Здесь основная группа - это опущенная категория: не состоящие в браке, не-северные регионы (не состоящие в браке люди, которые не живут в северном регионе). Все сравнения будут проводиться по отношению к этой базовой группе или исключенной категории. Средняя почасовая оплата в базовой категории составляет около 8,81 доллара (условный член). Для сравнения, средняя почасовая оплата тех, кто состоит в браке, выше примерно на 1,10 доллара и составляет примерно 9,91 доллара (8,81 доллара + 1,10 доллара). Напротив, средняя почасовая оплата у тех, кто живет на Севере, ниже примерно на 1,67 доллара и составляет примерно 7,14 доллара (8,81 доллара - 1,67 доллара).
Таким образом, если в регрессию включено несколько качественных переменных, важно отметить, что пропущенная категория должна быть выбрана в качестве эталонной категории, и все сравнения будут производиться по отношению к этой категории. Член пересечения покажет ожидаемое значение эталонной категории, а коэффициенты наклона покажут, насколько другие категории отличаются от эталонной (пропущенной) категории.[4]
Модели ANCOVA
Модель регрессии, которая содержит смесь количественных и качественных переменных, называется Анализ ковариации (ANCOVA) модель. Модели ANCOVA являются расширением моделей ANOVA. Они статистически контролируют влияние количественных независимых переменных (также называемых ковариатами или контрольными переменными).[4]
Чтобы проиллюстрировать, как качественные и количественные регрессоры включаются в модели ANCOVA, предположим, что мы рассматриваем тот же пример, который используется в модели ANOVA с одной качественной переменной: среднегодовая зарплата учителей государственных школ в трех географических регионах страны A. Если мы включим количественную Переменная, Расходы правительства штата на государственные школы на ученика, в этой регрессии мы получаем следующую модель:
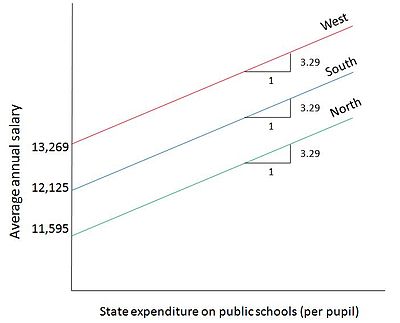
- Yя = α1 + α2D2i + α3D3i + α4Икся + Uя
куда,
- Yя = средняя годовая зарплата учителей государственных школ в штате i
- Икся = Государственные расходы на государственные школы на ученика
- D2i = 1, если государство i находится в Северном регионе
- D2i = 0, иначе
- D3i = 1, если государство i находится в Южном регионе
- D3i = 0, иначе
Скажем, выход регрессии для этой модели
- Ŷя = 13 269,11–1673,514D2i - 1144.157D3i + 3,2889Xя
Результат показывает, что на каждое увеличение государственных расходов на одного учащегося в государственных школах средняя зарплата учителя государственной школы увеличивается примерно на 3,29 доллара. Кроме того, для штата в Северном регионе средняя зарплата учителей ниже, чем в Западном регионе, примерно на 1673 доллара, а для штата в Южном регионе средняя заработная плата учителей ниже, чем в Западном регионе, примерно на 1144 долларов. На рисунке 3 схематически изображена эта модель. Строки средней заработной платы параллельны друг другу, исходя из предположения модели, что коэффициент расходов не зависит от штата. Компромисс, показанный отдельно на графике для каждой категории, находится между двумя количественными переменными: заработная плата учителей государственных школ (Y) по отношению к государственным расходам на ученика в государственных школах (X).[4]
Взаимодействия между фиктивными переменными
Количественные регрессоры в регрессионных моделях часто имеют взаимодействие между собой. Таким же образом качественные регрессоры или фиктивные переменные также могут иметь эффекты взаимодействия друг с другом, и эти взаимодействия могут быть отображены в регрессионной модели. Например, в регрессии, включающей определение заработной платы, если рассматривать две качественные переменные, а именно пол и семейное положение, может существовать взаимосвязь между семейным положением и полом.[6] Эти взаимодействия могут быть показаны в уравнении регрессии, как показано в приведенном ниже примере.
С двумя качественными переменными, являющимися полом и семейным положением, и с количественным объяснением, являющимся количеством лет образования, регрессия, которая является чисто линейной в объяснениях, будет
- Yя = β1 + β2D2, я + β3D3, я + αXя + Uя
куда
- я обозначает конкретного человека
- Y = почасовая оплата (в $)
- X = Годы обучения
- D2 = 1, если женский, 0 в противном случае
- D3 = 1, если замужем, 0 в противном случае
Эта спецификация не учитывает возможность того, что может иметь место взаимодействие между двумя качественными переменными, D2 и D3. Например, замужняя женщина может получать заработную плату, отличную от заработной платы не состоящего в браке мужчины, на сумму, не равную сумме разницы в том, что она единолично женщина и единолично состоит в браке. Тогда влияние взаимодействующих манекенов на среднее значение Y не просто добавка как в случае вышеприведенной спецификации, но мультипликативный также, и определение заработной платы может быть определено как:
- Yя = β1 + β2D2, я + β3D3, я + β4(D2, яD3, я) + αXя + Uя
Здесь,
- β2 = дифференциальный эффект женственности
- β3 = дифференциальный эффект от брака
- β4 = дальнейший дифференциальный эффект бытия обе женский и состоите в браке
Согласно этому уравнению при отсутствии ненулевой ошибки заработная плата неженатого мужчины равна β1+ αXя, у незамужней женщины β1+ β2 + αXя, что быть женатым мужчиной - β1+ β3 + αXя, а замужняя женщина - β1 + β2 + β3 + β4+ αXя (где любая из оценок коэффициентов манекенов могла оказаться положительной, нулевой или отрицательной).
Таким образом, макет взаимодействия (продукт двух макетов) может изменять зависимую переменную от значения, которое она получает, когда эти два макета рассматриваются по отдельности.[4]
Однако использования продуктов фиктивных переменных для фиксации взаимодействий можно избежать, используя другую схему категоризации данных - ту, которая определяет категории в терминах комбинаций характеристик. Если мы позволим
- D4 = 1, если женщина незамужняя, 0 в противном случае
- D5 = 1, если женатый мужчина, 0 в противном случае
- D6 = 1, если замужняя женщина, 0 в противном случае
тогда достаточно указать регрессию
- Yя = δ1 + δ4D4, я + δ5D5, я + δ6D6, я + αXя + Uя.
Тогда при нулевом шоковом члене значение зависимой переменной δ1+ αXя для базовой категории неженатых мужчин δ1 + δ4+ αXя для незамужних женщин, δ1 + δ5+ αXя для женатых мужчин, а δ1 + δ6+ αXя для замужних женщин. Эта спецификация включает в себя такое же количество переменных с правой стороны, что и предыдущая спецификация с элементом взаимодействия, и результаты регрессии для прогнозируемого значения зависимой переменной, зависящей от Xядля любой комбинации качественных признаков идентичны между данной спецификацией и спецификацией взаимодействия.
Фиктивные зависимые переменные
Что произойдет, если зависимая переменная - фиктивная?
Модель с фиктивной зависимой переменной (также известной как качественная зависимая переменная) - это модель, в которой зависимая переменная под влиянием независимых переменных носит качественный характер. Некоторые решения относительно того, «сколько» действия должно быть выполнено, предполагают предварительное принятие решения о том, выполнять действие или нет. Например, количество продукции, которую необходимо произвести, затраты, которые должны быть понесены, и т. Д. Включают предварительные решения о том, производить или нет, тратить или нет и т. Д. Такие «предыдущие решения» становятся зависимыми фикциями в регрессионной модели.[8]
Например, решение работника стать частью рабочей силы становится фиктивной зависимой переменной. Решение дихотомический, то есть решение имеет два возможных исхода: да и нет. Таким образом, зависимая фиктивная переменная «Участие» примет значение 1, если участвует, и 0, если не участвует.[4] Некоторые другие примеры дихотомических зависимых манекенов цитируются ниже:
Решение: Выбор профессии. Зависимый манекен: Супервизор = 1, если супервизор, 0, если не супервизор.
Решение: Принадлежность к политической партии. Зависимый манекен: Принадлежность = 1, если связана с партией, 0, если не аффилирована.
Решение: Отставка. Зависимый манекен: На пенсии = 1, если на пенсии, 0, если не на пенсии.
Когда качественная зависимая фиктивная переменная имеет более двух значений (например, принадлежность ко многим политическим партиям), она становится множественным ответом, или мультиномиальной, или полихотомический модель.[8]
Модели зависимых фиктивных переменных
Анализ моделей зависимых фиктивных переменных может выполняться разными методами. Один из таких методов - обычный OLS метод, который в данном контексте называется линейная вероятностная модель. Альтернативный метод - предположить, что существует ненаблюдаемая непрерывная скрытая переменная Y* и что наблюдаемая дихотомическая переменная Y = 1, если Y* > 0, 0 иначе. Это основная концепция логит и пробит модели. Эти модели кратко обсуждаются ниже.[9]
Линейная вероятностная модель
Обычная модель наименьших квадратов, в которой зависимая переменная Y дихотомический манекен, принимающий значения 0 и 1, является линейная вероятностная модель (LPM).[9] Предположим, мы рассматриваем следующую регрессию:

куда
- = семейный доход

- если дом принадлежит семье, 0 если дом не принадлежит семье

Модель называется линейная вероятностная модель потому что регрессия линейна. В условное среднее из Yя учитывая Xя, записанный как , интерпретируется как условная возможность что событие произойдет для этого значения Икся - то есть Pr (Yя = 1 |Икся). В этом примере дает вероятность того, что дом принадлежит семье, доход которой определяется Икся.

Теперь, используя OLS предположение , мы получили


Модель LPM имеет ряд проблем:
- Линия регрессии не будет хорошо подогнанный единица и, следовательно, меры значимости, такие как R2, не будет надежным.
- Модели, которые анализируются с использованием подхода LPM, будут иметь гетероскедастический беспорядки.
- Член ошибки будет иметь ненормальное распределение.
- LPM может давать прогнозируемые значения зависимой переменной, которые больше 1 или меньше 0. Это будет трудно интерпретировать, поскольку прогнозируемые значения предназначены для вероятностей, которые должны лежать между 0 и 1.
- Между переменными модели LPM может существовать нелинейная связь, и в этом случае линейная регрессия не будет точно соответствовать данным.[4][10]
Альтернативы LPM

Чтобы избежать ограничений LPM, необходима модель, которая в качестве объясняющей переменной Икся, увеличивается, пя = E (Yя = 1 | Икся) должен оставаться в диапазоне от 0 до 1. Таким образом, отношения между независимыми и зависимыми переменными обязательно нелинейны.
Для этого кумулятивная функция распределения (CDF) можно использовать для оценки регрессии зависимой фиктивной переменной. На рисунке 4 показана S-образная кривая, напоминающая CDF случайной величины. В этой модели вероятность находится между 0 и 1, и нелинейность была зафиксирована. Теперь стоит вопрос о выборе CDF, который будет использоваться.
Можно использовать два альтернативных CDF: логистика и нормальный CDF. Логистический CDF дает начало логит модель и нормальный CDF дает рост пробит модель.[4]
Логит модель
Недостатки LPM привели к разработке более совершенной и улучшенной модели, названной моделью logit. В логит-модели кумулятивное распределение члена ошибки в уравнении регрессии является логистическим.[9] Регрессия более реалистична, поскольку она нелинейна.
Логит-модель оценивается с использованием подход максимального правдоподобия. В этой модели , которая представляет собой вероятность того, что зависимая переменная примет значение 1 с учетом независимой переменной:


куда .

Затем модель выражается в виде отношение шансов: то, что моделируется в логистической регрессии, является натуральным логарифмом шансов, причем шансы определяются как . Принимая натуральный логарифм шансов, логит (Lя) выражается как


Эта связь показывает, что Lя линейно по отношению к Икся, но вероятности не линейны в терминах Икся.[10]
Пробит модель
Еще одна модель, которая была разработана для устранения недостатков LPM, - это пробит-модель. Пробит-модель использует тот же подход к нелинейности, что и логит-модель; однако вместо логистической CDF используется обычный CDF.[9]
Смотрите также
- Бинарная регрессия
- Чау-тест
- Проверка гипотезы
- Функция индикатора
- Линейная дискриминантная функция
- Мультиколлинеарность
Рекомендации
- ^ Фиктивные переменные также называются индикаторная переменная, проектная переменная, быстрое кодирование, Логический индикатор, двоичная переменная, или же качественная переменная.[1]
- ^ Гаравалья, Сьюзен; Шарма, Аша. «Умное руководство по фиктивным переменным: четыре приложения и макрос» (PDF). Архивировано из оригинал (PDF) 25 марта 2003 г.
- ^ Draper, N.R .; Смит, Х. (1998). "'Фиктивные переменные". Прикладной регрессионный анализ. Вайли. С. 299–326. ISBN 0-471-17082-8.
- ^ «Интерпретация коэффициентов фиктивных переменных» (PDF). Архивировано из оригинал (PDF) 18 августа 2003 г.
- ^ а б c d е ж грамм час я j k Гуджарати, Дамодар Н. (2003). Базовая эконометрика. Макгроу Хилл. ISBN 0-07-233542-4.
- ^ Кеннеди, Питер (2003). Руководство по эконометрике (Пятое изд.). Кембридж: MIT Press. С. 249–250. ISBN 0-262-61183-X.
- ^ а б Вулдридж, Джеффри М (2009). Вводная эконометрика: современный подход. Cengage Learning. п. 865. ISBN 0-324-58162-9.
- ^ Костюмы, Дэниел Б. (1957). «Использование фиктивных переменных в уравнениях регрессии». Журнал Американской статистической ассоциации. 52 (280): 548–551. Дои:10.1080/01621459.1957.10501412. JSTOR 2281705.
- ^ а б Баррето, Умберто; Хауленд, Фрэнк (2005). «Глава 22: фиктивные модели с зависимыми переменными». Вводная эконометрика: использование моделирования Монте-Карло с Microsoft Excel. Издательство Кембриджского университета. ISBN 0-521-84319-7.
- ^ а б c d Маддала, Г. С. (1992). Введение в эконометрику. Макмиллан Паб. Co. p. 631. ISBN 0-02-374545-2.
- ^ а б Аднан Касман, «Фиктивные модели с зависимыми переменными».. Конспект лекций
дальнейшее чтение
- Астериу, Димитриос; Холл, С.Г. (2015). "Фиктивные переменные". Прикладная эконометрика (3-е изд.). Лондон: Пэлгрейв Макмиллан. С. 209–230. ISBN 978-1-137-41546-2.
- Койман, Мариус А. (1976). Фиктивные переменные в эконометрике. Тилбург: Издательство Тилбургского университета. ISBN 90-237-2919-6.
внешняя ссылка
- Maathuis, Marloes (2007). "Глава 7: Регрессия фиктивной переменной" (PDF). Stat 423: Прикладная регрессия и дисперсионный анализ. Архивировано из оригинал (PDF) 16 декабря 2011 г.
- Фокс, Джон (2010). «Регрессия с фиктивной переменной» (PDF).
- Бейкер, Сэмюэл Л. (2006). "Фиктивные переменные" (PDF). Архивировано из оригинал (PDF) 1 марта 2006 г.