Агрегирование бутстрапа - Bootstrap aggregating - Wikipedia
| Часть серии по |
| Машинное обучение и сбор данных |
|---|
Площадки для машинного обучения |
Агрегирование бутстрапа, также называется упаковка (из бOotstrap аггрегатing), это ансамбль машинного обучения мета-алгоритм разработан для повышения стабильности и точности машинное обучение алгоритмы, используемые в статистическая классификация и регресс. Это также снижает отклонение и помогает избежать переоснащение. Хотя обычно это применяется к Древо решений методы, его можно использовать с любым типом метода. Бэггинг - это особый случай усреднение модели подход.
Описание техники
Учитывая стандарт Обучающий набор размера п, упаковка создает м новые тренировочные наборы , каждый размер п ', к отбор проб из D равномерно и с заменой. При выборке с заменой некоторые наблюдения могут повторяться в каждом . Если п′ =п, то для больших п набор ожидается дробь (1 - 1 /е ) (≈63,2%) уникальных примеров D, остальные дубликаты.[1] Такой образец известен как бутстрап образец. Выборка с заменой гарантирует, что каждый бутстрап независим от своих аналогов, так как он не зависит от предыдущих выбранных выборок при выборке. Потом, м модели устанавливаются с использованием вышеуказанных м выборки бутстрапа и объединяются путем усреднения вывода (для регрессии) или голосования (для классификации).


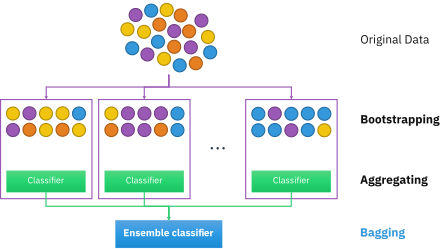
Бэггинг приводит к «улучшениям для нестабильных процедур»,[2] которые включают, например, искусственные нейронные сети, деревья классификации и регрессии, и выбор подмножества в линейная регрессия.[3] Было показано, что бэггинг улучшает обучение прообразу.[4][5] С другой стороны, это может слегка ухудшить производительность стабильных методов, таких как K-ближайших соседей.[2]
Процесс алгоритма
Исходный набор данных
Исходный набор данных содержит несколько записей выборок от s1 до s5. Каждый образец имеет 5 характеристик (от гена 1 до гена 5). Все образцы помечены как «Да» или «Нет» в зависимости от проблемы классификации. 
Создание загрузочных наборов данных
Учитывая приведенную выше таблицу для классификации новой выборки, сначала необходимо создать самонастраиваемый набор данных с использованием данных из исходного набора данных. Этот набор данных начальной загрузки обычно имеет размер исходного набора данных или меньше.
В этом примере размер равен 5 (от s1 до s5). Загрузочный набор данных создается путем случайного выбора образцов из исходного набора данных. Допускается повторный выбор. Любые выборки, которые не выбраны для набора данных начальной загрузки, помещаются в отдельный набор данных, называемый набором данных Out-of-Bag.
См. Пример загруженного набора данных ниже. Он имеет 5 записей (того же размера, что и исходный набор данных). Есть повторяющиеся записи, такие как две s3, поскольку записи выбираются случайным образом с заменой.

Этот шаг будет повторяться для создания m наборов данных с начальной загрузкой.
Создание деревьев решений

Дерево решений создается для каждого начального набора данных с использованием случайно выбранных значений столбцов для разделения узлов.
Прогнозирование с использованием нескольких деревьев решений
 Когда в таблицу добавляется новый образец. Загрузочный набор данных используется для определения значения классификатора новой записи.
Когда в таблицу добавляется новый образец. Загрузочный набор данных используется для определения значения классификатора новой записи.

Новая выборка тестируется в случайном лесу, созданном каждым загруженным набором данных, и каждое дерево создает значение классификатора для новой выборки. Для классификации процесс, называемый голосованием, используется для определения окончательного результата, где результат, наиболее часто получаемый случайным лесом, является заданным результатом для выборки. Для регрессии выборке присваивается среднее значение классификатора, созданное деревьями.

После того, как образец протестирован в случайном лесу. Образцу присваивается значение классификатора, и он добавляется в таблицу.
Алгоритм (Классификация)
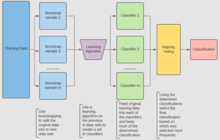
Для классификации используйте Обучающий набор , Индуктор и количество образцов начальной загрузки как вход. Создать классификатор как выход[6]



- Создайте новые тренировочные наборы , от с заменой
- Классификатор строится из каждого набора с помощью определить классификацию набора
- Наконец классификатор генерируется с использованием ранее созданного набора классификаторов на исходном наборе данных , классификация, наиболее часто предсказываемая подклассификаторами окончательная классификация

для i = 1 - m {D '= выборка начальной загрузки из D (выборка с заменой) Ci = I (D')} C * (x) = argmax Σ 1 (наиболее часто предсказываемая метка y) y∈Y i: Ci ( х) = уПример: данные об озоне
Чтобы проиллюстрировать основные принципы упаковки в мешки, ниже приводится анализ взаимосвязи между озон и температура (данные из Rousseeuw и Leroy (1986), анализ выполнен в р ).
Взаимосвязь между температурой и озоном, судя по диаграмме рассеяния, в этом наборе данных является нелинейной. Чтобы математически описать эту взаимосвязь, ЛЕСС используются сглаживающие (с полосой пропускания 0,5). Вместо того, чтобы создавать единую систему сглаживания для всего набора данных, 100 бутстрап были взяты образцы. Каждая выборка состоит из случайного подмножества исходных данных и сохраняет подобие распределения и вариативности основного набора. Для каждого образца бутстрапа подбирался сглаживающий фильтр LOESS. Затем были сделаны прогнозы на основе этих 100 сглаживателей для всего диапазона данных. Черные линии представляют эти первоначальные прогнозы. Линии не согласуются в своих прогнозах и имеют тенденцию переоценивать свои точки данных: это видно по шаткому течению линий.
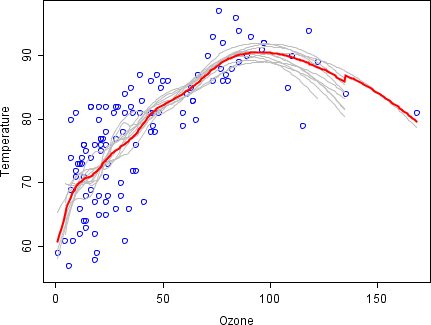
Взяв среднее значение из 100 сглаживателей, каждое из которых соответствует подмножеству исходного набора данных, мы приходим к одному предиктору с упаковкой (красная линия). Течение красной линии стабильно и не слишком соответствует какой-либо точке (точкам) данных.
Преимущества против недостатков
Преимущества:
- Многие слабые ученики в совокупности обычно превосходят одного ученика по всему набору и имеют меньше возможностей
- Устраняет дисперсию при высокой дисперсии низкий наборы данных[7]
- Может выполняться в параллельно, поскольку каждый отдельный бутстрап может обрабатываться отдельно перед объединением[8]
Недостатки:
- В наборе данных с высокой систематической погрешностью упаковка в пакеты также будет иметь большое отклонение в совокупности.[7]
- Утрата интерпретируемости модели.
- Может быть дорогостоящим в вычислительном отношении в зависимости от набора данных
История
Концепция Bootstrap Aggregating основана на концепции Bootstrapping, разработанной Брэдли Эфроном.[9]Bootstrap Aggregating был предложен Лео Брейман кто также ввел сокращенный термин «Бэггинг» (BOotstrap аггрегатing). Брейман разработал концепцию упаковки в 1994 году, чтобы улучшить классификацию путем комбинирования классификаций случайно сгенерированных обучающих наборов. Он утверждал: «Если возмущение обучающей выборки может вызвать значительные изменения в построенном предикторе, то упаковка может повысить точность».[3]
Смотрите также
- Повышение (мета-алгоритм)
- Самостоятельная загрузка (статистика)
- Перекрестная проверка (статистика)
- Случайный лес
- Метод случайных подпространств (упаковка атрибутов)
- Переделанная граница эффективности
- Прогнозный анализ: деревья классификации и регрессии
Рекомендации
- ^ Аслам, Джавед А .; Попа, Ралука А .; и Ривест, Рональд Л. (2007); Об оценке объема и достоверности статистического аудита, Труды семинара по технологиям электронного голосования (EVT '07), Бостон, Массачусетс, 6 августа 2007 г. В более общем смысле, при розыгрыше с заменой п ' значения из набора п (разные и одинаково вероятные), ожидаемое количество уникальных розыгрышей .
- ^ а б Брейман, Лео (1996). "Предсказатели мешков". Машинное обучение. 24 (2): 123–140. CiteSeerX 10.1.1.32.9399. Дои:10.1007 / BF00058655. S2CID 47328136.
- ^ а б Брейман, Лео (сентябрь 1994). "Предикторы упаковки" (PDF). Департамент статистики Калифорнийского университета в Беркли. Технический отчет № 421. Получено 2019-07-28.
- ^ Саху, А., Рангер, Г., Апли, Д., Шумоподавление изображения с использованием подхода многофазных основных компонентов ядра и ансамблевой версии, IEEE Applied Imagery Pattern Recognition Workshop, pp.1-7, 2011.
- ^ Шинде, Амит, Аншуман Саху, Дэниел Апли и Джордж Рангер. "Прообразы для вариационных паттернов из Kernel PCA и Bagging. »IIE Transactions, Том 46, Выпуск 5, 2014 г.
- ^ Бауэр, Эрик; Кохави, Рон (1999). «Эмпирическое сравнение алгоритмов классификации голосования: пакетирование, усиление и варианты». Машинное обучение. 36: 108–109. Дои:10.1023 / А: 1007515423169. S2CID 1088806. Получено 6 декабря 2020.
- ^ а б "Что такое бэггинг (загрузочная агрегация)?". CFI. Институт корпоративных финансов. Получено 5 декабря, 2020.
- ^ Зогни, Рауф (5 сентября 2020 г.). «Баггинг (агрегирование начальной загрузки), обзор». Средняя. Стартап.
- ^ Эфрон, Б. (1979). «Методы начальной загрузки: еще один взгляд на складной нож». Анналы статистики. 7 (1): 1–26. Дои:10.1214 / aos / 1176344552.

дальнейшее чтение
- Брейман, Лео (1996). «Предсказатели упаковки». Машинное обучение. 24 (2): 123–140. CiteSeerX 10.1.1.32.9399. Дои:10.1007 / BF00058655. S2CID 47328136.
- Альфаро, Э., Гамес, М. и Гарсия, Н. (2012). «adabag: пакет R для классификации с AdaBoost.M1, AdaBoost-SAMME и Bagging». Цитировать журнал требует
| журнал =(Помогите) - Коциантис, Сотирис (2014). «Варианты бэггинга и бустинга для решения задач классификации: обзор». Knowledge Eng. Обзор. 29 (1): 78–100. Дои:10.1017 / S0269888913000313.
- Бёмке, Брэдли; Гринвелл, Брэндон (2019). «Бэггинг». Практическое машинное обучение с R. Чепмен и Холл. С. 191–202. ISBN 978-1-138-49568-5.