Рекуррентная нейронная сеть - Recurrent neural network
| Часть серии по |
| Машинное обучение и сбор данных |
|---|
Площадки для машинного обучения |
А рекуррентная нейронная сеть (RNN) является классом искусственные нейронные сети где связи между узлами образуют ориентированный граф во временной последовательности. Это позволяет ему демонстрировать динамическое поведение во времени. Происходит от нейронные сети с прямой связью, RNN могут использовать свое внутреннее состояние (память) для обработки последовательностей входных данных переменной длины.[1][2][3] Это делает их применимыми к таким задачам, как несегментированные, связанные распознавание почерка[4] или же распознавание речи.[5][6]
Термин «рекуррентная нейронная сеть» используется без разбора для обозначения двух широких классов сетей с аналогичной общей структурой, одна из которых конечный импульс а другой бесконечный импульс. Оба класса сетей демонстрируют временные динамическое поведение.[7] Конечная импульсная рекуррентная сеть - это ориентированный ациклический граф которая может быть развернута и заменена нейронной сетью со строго прямой связью, в то время как бесконечная импульсная рекуррентная сеть является ориентированный циклический граф что нельзя развернуть.
Как конечные импульсные, так и бесконечные импульсные рекуррентные сети могут иметь дополнительные сохраненные состояния, и хранилище может находиться под непосредственным контролем нейронной сети. Хранилище также может быть заменено другой сетью или графиком, если он включает временные задержки или имеет петли обратной связи. Такие контролируемые состояния называются стробированным состоянием или стробированной памятью и являются частью долговременная кратковременная память сети (LSTM) и закрытые повторяющиеся единицы. Это также называется нейронной сетью с обратной связью (FNN).
История
Рекуррентные нейронные сети были основаны на Дэвид Румелхарт Работа 1986 г.[8] Сети Хопфилда - особого вида РНС - были открыты Джон Хопфилд в 1982 году. В 1993 году система компрессора нейронной истории решила задачу «очень глубокого обучения», которая потребовала более 1000 последующих слоев в RNN, развернутых во времени.[9]
LSTM
Долговременная кратковременная память (LSTM) сети были изобретены Hochreiter и Шмидхубер в 1997 году и установил рекорды точности во многих областях применения.[10]
Примерно в 2007 году LSTM начала революцию распознавание речи, превосходя традиционные модели в некоторых речевых приложениях.[11] В 2009 г. Коннекционистская временная классификация (CTC) обученная сеть LSTM была первой RNN, которая выиграла соревнования по распознаванию образов, когда она выиграла несколько соревнований по подключению распознавание почерка.[12][13] В 2014 году китайский поисковый гигант Baidu использовали обученные CTC RNN, чтобы сломать Набор данных для распознавания речи Switchboard Hub5'00 эталонный тест без использования традиционных методов обработки речи.[14]
LSTM также улучшил распознавание речи с большим словарным запасом.[5][6] и текст в речь синтез[15] и использовался в Google Android.[12][16] Сообщается, что в 2015 году производительность распознавания речи Google резко выросла на 49%.[нужна цитата ] через LSTM, обученный CTC.[17]
LSTM побил рекорды по улучшению машинный перевод,[18] Языковое моделирование[19] и многоязычная обработка языков.[20] LSTM в сочетании с сверточные нейронные сети (CNN) улучшено автоматические подписи к изображениям.[21] Учитывая накладные расходы на вычисления и память при запуске LSTM, были предприняты усилия по ускорению LSTM с помощью аппаратных ускорителей.[22]
Архитектура
RNN бывают разных вариантов.
Полностью повторяющийся

Базовые RNN - это сеть нейроноподобный узлы организованы в последовательные слои. Каждый узел в данном слое связан с направленное (одностороннее) соединение каждому другому узлу в следующем последующем слое.[нужна цитата ] Каждый узел (нейрон) имеет изменяющуюся во времени действительную активацию. Каждое соединение (синапс) имеет изменяемый действительный масса. Узлы - это либо входные узлы (получающие данные извне), либо выходные узлы (выдающие результаты), либо скрытые узлы (которые изменяют данные. по пути от входа к выходу).
За контролируемое обучение в настройках дискретного времени последовательности входных векторов с действительным знаком прибывают во входные узлы, по одному вектору за раз. На любом заданном временном шаге каждый не входящий блок вычисляет свою текущую активацию (результат) как нелинейную функцию взвешенной суммы активаций всех блоков, которые к нему подключены. Заданные супервизором целевые активации могут быть предоставлены для некоторых выходных устройств в определенные временные интервалы. Например, если входная последовательность представляет собой речевой сигнал, соответствующий произносимой цифре, конечным целевым выходом в конце последовательности может быть метка, классифицирующая цифру.
В обучение с подкреплением настройки, ни один учитель не дает целевых сигналов. Вместо этого фитнес-функция или же функция вознаграждения иногда используется для оценки производительности RNN, которая влияет на ее входной поток через блоки вывода, подключенные к исполнительным механизмам, влияющим на окружающую среду. Это может быть использовано для игры, в которой прогресс измеряется количеством выигранных очков.
Каждая последовательность дает ошибку как сумму отклонений всех целевых сигналов от соответствующих активаций, вычисленных сетью. Для обучающего набора, состоящего из множества последовательностей, полная ошибка - это сумма ошибок всех отдельных последовательностей.
Сети Элмана и Иорданские сети
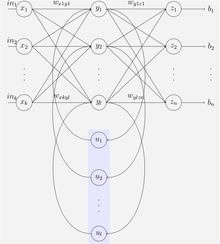
An Эльман сеть - это трехуровневая сеть (расположенная по горизонтали как Икс, у, и z на иллюстрации) с добавлением набора контекстных единиц (ты на иллюстрации). Средний (скрытый) слой связан с этими блоками контекста с весом, равным единице.[23] На каждом временном шаге вход подается вперед, и правило обучения применяется. Фиксированные обратные соединения сохраняют копию предыдущих значений скрытых единиц в единицах контекста (поскольку они распространяются по соединениям до применения правила обучения). Таким образом, сеть может поддерживать своего рода состояние, позволяя ей выполнять такие задачи, как прогнозирование последовательности, которые выходят за рамки стандартных возможностей. многослойный персептрон.
Иордания сети похожи на сети Эльмана. Единицы контекста загружаются из выходного слоя вместо скрытого. Блоки контекста в сети Иордании также называются уровнем состояния. У них есть постоянная связь с собой.[23]
Сети Элмана и Джордана также известны как «Простые рекуррентные сети» (SRN).


Переменные и функции
- : входной вектор
- : вектор скрытого слоя
- : выходной вектор
- , и : матрицы параметров и вектор
- и : Функции активации








Hopfield
В Сеть Хопфилда является РНС, в которой все связи симметричны. Это требует стационарный входных данных и, таким образом, не является общей RNN, поскольку не обрабатывает последовательности шаблонов. Это гарантирует, что он сойдется. Если соединения обучаются с использованием Hebbian обучение тогда сеть Хопфилда может работать как крепкий память с адресацией по содержимому, устойчивая к изменению подключения.
Двунаправленная ассоциативная память
Представлено Барт Коско,[26] Сеть с двунаправленной ассоциативной памятью (BAM) - это вариант сети Хопфилда, в которой ассоциативные данные хранятся в виде вектора. Двунаправленность возникает из-за передачи информации через матрицу и ее транспонировать. Обычно биполярное кодирование предпочтительнее двоичного кодирования ассоциативных пар. В последнее время стохастические модели BAM, использующие Марков степпинг был оптимизирован для повышения стабильности сети и соответствия реальным приложениям.[27]
Сеть BAM имеет два уровня, каждый из которых может использоваться как вход для вызова ассоциации и создания выходных данных на другом уровне.[28]
Состояние эха
Сеть состояний эха (ESN) имеет редко связанный случайный скрытый слой. Веса выходных нейронов - единственная часть сети, которая может изменяться (обучаться). ESN хорошо воспроизводят определенные Временные ряды.[29] Вариант для импульсные нейроны известен как машина состояния жидкости.[30]
Самостоятельно RNN (IndRNN)
Независимо рекуррентная нейронная сеть (IndRNN)[31] решает проблемы исчезновения и взрыва градиента в традиционной полносвязной RNN. Каждый нейрон в одном слое получает только свое прошлое состояние в качестве контекстной информации (вместо полной связи со всеми другими нейронами в этом слое), и, таким образом, нейроны не зависят от истории друг друга. Обратное распространение градиента можно регулировать, чтобы избежать исчезновения и увеличения градиента, чтобы сохранить долгосрочную или краткосрочную память. Информация о кросс-нейронах исследуется на следующих уровнях. IndRNN можно надежно обучить с помощью ненасыщенных нелинейных функций, таких как ReLU. С помощью пропуска соединений можно обучать глубокие сети.
Рекурсивный
А рекурсивная нейронная сеть[32] создается путем применения того же набора весов рекурсивно над дифференцируемой графоподобной структурой путем обхода структуры в топологический порядок. Такие сети обычно также обучаются в обратном режиме автоматическая дифференциация.[33][34] Они могут обрабатывать распределенные представления структуры, такой как логические термины. Частным случаем рекурсивных нейронных сетей является РНС, структура которой соответствует линейной цепочке. Рекурсивные нейронные сети были применены к обработка естественного языка.[35] Рекурсивная нейронная тензорная сеть использует тензор функция композиции для всех узлов в дереве.[36]
Компрессор нейронной истории
Компрессор нейронной истории представляет собой неконтролируемый стек RNN.[37] На уровне ввода он учится предсказывать свой следующий ввод на основе предыдущих вводов. Только непредсказуемые входы некоторой RNN в иерархии становятся входами для RNN следующего более высокого уровня, которая поэтому повторно вычисляет свое внутреннее состояние только изредка. Таким образом, каждая RNN более высокого уровня изучает сжатое представление информации в RNN ниже. Это делается таким образом, чтобы входная последовательность могла быть точно реконструирована из представления на самом высоком уровне.
Система эффективно минимизирует длину описания или отрицательные логарифм вероятности данных.[38] Учитывая большую предсказуемость обучения в последовательности входящих данных, RNN самого высокого уровня может использовать контролируемое обучение, чтобы легко классифицировать даже глубокие последовательности с большими интервалами между важными событиями.
Можно разделить иерархию RNN на две RNN: «сознательный» блок (более высокий уровень) и «подсознательный» автоматизатор (более низкий уровень).[37] После того, как блокировщик научился предсказывать и сжимать входные данные, которые непредсказуемы автоматизатором, автоматизатор может быть вынужден на следующей фазе обучения предсказывать или имитировать с помощью дополнительных блоков скрытые блоки более медленно изменяющегося блока. Это позволяет автоматизатору легко запоминать подходящие, редко меняющиеся воспоминания через длительные промежутки времени. В свою очередь, это помогает автоматизатору сделать многие из его некогда непредсказуемых входных данных предсказуемыми, так что блок может сосредоточиться на оставшихся непредсказуемых событиях.[37]
А генеративная модель частично преодолел проблема исчезающего градиента[39] из автоматическая дифференциация или же обратное распространение в нейронных сетях в 1992 году. В 1993 году такая система решила задачу «очень глубокого обучения», которая требовала более 1000 последующих слоев в RNN, развернутых во времени.[9]
РНС второго порядка
RNN второго порядка используют веса более высокого порядка вместо стандартного веса и состояния могут быть продуктом. Это позволяет прямое отображение на конечный автомат и в обучении, и в стабильности, и в представлении.[40][41] Примером этого является долговременная краткосрочная память, но у нее нет таких формальных отображений или доказательства стабильности.


Долговременная кратковременная память

Долгосрочная краткосрочная память (LSTM) - это глубокое обучение система, которая избегает проблема исчезающего градиента. LSTM обычно дополняется повторяющимися воротами, называемыми «воротами забывания».[42] LSTM предотвращает исчезновение или взрыв ошибок обратного распространения.[39] Вместо этого ошибки могут течь в обратном направлении через неограниченное количество виртуальных слоев, развернутых в пространстве. То есть LSTM может изучать задачи[12] которые требуют воспоминаний о событиях, которые произошли на тысячи или даже миллионы дискретных временных шагов раньше. Топологии, подобные LSTM, могут быть разработаны для конкретных задач.[43] LSTM работает даже с большими задержками между важными событиями и может обрабатывать сигналы, которые смешивают низкочастотные и высокочастотные компоненты.
Многие приложения используют стеки LSTM RNN.[44] и обучить их Коннекционистская временная классификация (CTC)[45] найти матрицу весов RNN, которая максимизирует вероятность последовательностей меток в обучающем наборе, учитывая соответствующие входные последовательности. СТС добивается согласованности и признания.
LSTM может научиться распознавать контекстно-зависимые языки в отличие от предыдущих моделей на базе скрытые марковские модели (HMM) и аналогичные концепции.[46]
Закрытый рекуррентный блок
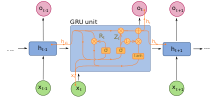
Закрытые рекуррентные подразделения (ГРУ) - это стробирующий механизм в повторяющиеся нейронные сети введены в 2014 году. Используются в полной форме и в нескольких упрощенных вариантах.[47][48] Их производительность при моделировании полифонической музыки и моделирования речевых сигналов оказалась аналогичной работе с долговременной краткосрочной памятью.[49] У них меньше параметров, чем у LSTM, так как у них отсутствует выходной вентиль.[50]
Двунаправленный
Двунаправленные RNN используют конечную последовательность для прогнозирования или маркировки каждого элемента последовательности на основе прошлого и будущего контекстов элемента. Это делается путем объединения выходных данных двух RNN, одна обрабатывает последовательность слева направо, а другая - справа налево. Комбинированные выходные данные - это предсказания заданных учителем целевых сигналов. Этот метод оказался особенно полезным в сочетании с LSTM RNN.[51][52]
Непрерывное время
Постоянно повторяющаяся нейронная сеть (CTRNN) использует систему обыкновенные дифференциальные уравнения для моделирования воздействия на нейрон входящей последовательности спайков.
Для нейрона в сети с потенциал действия , скорость изменения активации определяется выражением:



Где:
- : Постоянная времени постсинаптический узел
- : Активация постсинаптического узла
- : Скорость изменения активации постсинаптического узла.
- : Вес соединения от пре до постсинаптического узла
- : Сигмоид x, например. .
- : Активация пресинаптического узла
- : Смещение пресинаптического узла.
- : Вход (если есть) в узел








CTRNN были применены к эволюционная робототехника где они использовались для улучшения зрения,[53] сотрудничество,[54] и минимальное когнитивное поведение.[55]
Обратите внимание, что Теорема выборки Шеннона, рекуррентные нейронные сети с дискретным временем можно рассматривать как рекуррентные нейронные сети с непрерывным временем, в которых дифференциальные уравнения преобразованы в эквивалентные разностные уравнения.[56] Это преобразование можно рассматривать как происходящее после функций активации постсинаптического узла. прошли фильтр нижних частот, но до отбора проб.

Иерархический
Эта секция нуждается в расширении. Вы можете помочь добавляя к этому. (Август 2019 г.) |
Иерархические RNN соединяют свои нейроны различными способами, чтобы разложить иерархическое поведение на полезные подпрограммы.[37][57]
Рекуррентная многослойная сеть персептронов
Как правило, сеть рекуррентной многослойной сети персептронов (RMLP) состоит из каскадных подсетей, каждая из которых содержит несколько уровней узлов. Каждая из этих подсетей является прямой, за исключением последнего уровня, который может иметь обратные связи. Каждая из этих подсетей соединена только прямыми соединениями.[58]
Модель с несколькими временными шкалами
Рекуррентная нейронная сеть с несколькими временными шкалами (MTRNN) - это нейронная вычислительная модель, которая может моделировать функциональную иерархию мозга посредством самоорганизации, которая зависит от пространственной связи между нейронами и от различных типов активности нейронов, каждый из которых имеет свои временные свойства.[59][60] При такой разнообразной нейронной активности непрерывные последовательности любого набора поведений сегментируются в примитивы многократного использования, которые, в свою очередь, гибко интегрируются в разнообразные последовательные поведения. Биологическое одобрение такого типа иерархии обсуждалось в предсказание памяти теория функции мозга Хокинс в его книге Об интеллекте.[нужна цитата ]
Нейронные машины Тьюринга
Нейронные машины Тьюринга (NTM) - это метод расширения рекуррентных нейронных сетей путем связывания их с внешними объем памяти ресурсы, с которыми они могут взаимодействовать процессы внимания. Комбинированная система аналогична Машина Тьюринга или же Архитектура фон Неймана но это дифференцируемый сквозной, что позволяет эффективно обучать его с помощью градиентный спуск.[61]
Дифференцируемый нейронный компьютер
Дифференцируемые нейронные компьютеры (DNC) - это расширение нейронных машин Тьюринга, позволяющее использовать нечеткие объемы каждого адреса памяти и запись хронологии.
Автоматические выталкивающие устройства нейронной сети
Автоматические выталкивающие устройства нейронной сети (NNPDA) похожи на NTM, но ленты заменяются аналоговыми стеками, которые дифференцируются и обучаются. В этом плане они похожи по сложности на распознаватели контекстно-свободные грамматики (CFG).[62]
Memristive Networks
Грег Снайдер из Лаборатория HP описывает систему корковых вычислений с мемристивными наноустройствами.[63] В мемристоры (резисторы с памятью) выполнены из тонкопленочных материалов, в которых сопротивление электрически регулируется за счет переноса ионов или кислородных вакансий внутри пленки. DARPA с Проект SyNAPSE в сотрудничестве с Департаментом когнитивных и нейронных систем (CNS) Бостонского университета профинансировал исследования IBM Research и HP Labs для разработки нейроморфных архитектур, которые могут быть основаны на мемристических системах. физическая нейронная сеть которые имеют очень похожие свойства на (Литтл-) сети Хопфилда, поскольку они имеют непрерывную динамику, имеют ограниченный объем памяти и естественным образом расслабляются за счет минимизации функции, которая является асимптотической по отношению к модели Изинга. В этом смысле динамика мемристической схемы имеет преимущество по сравнению с схемой резистор-конденсатор в том, что она имеет более интересное нелинейное поведение. С этой точки зрения создание аналоговых мемристивных сетей представляет собой особый тип нейроморфная инженерия в котором поведение устройства зависит от схемы подключения или топологии.[64][65]
Обучение персонала
Градиентный спуск
Градиентный спуск - это первый заказ итеративный оптимизация алгоритм для нахождения минимума функции. В нейронных сетях его можно использовать для минимизации члена ошибки путем изменения каждого веса пропорционально производной ошибки по этому весу, при условии, что нелинейный функции активации находятся дифференцируемый. Различные методы для этого были разработаны в 1980-х и начале 1990-х гг. Werbos, Уильямс, Робинсон, Шмидхубер, Hochreiter, Перлмуттер и другие.
Стандартный метод называется «обратное распространение во времени »Или BPTT, и является обобщением обратное распространение для сетей прямого распространения.[66][67] Как и этот метод, это экземпляр автоматическая дифференциация в режиме обратного накопления Принцип минимума Понтрягина. Онлайн-вариант, более затратный в вычислительном отношении, называется «Рекуррентное обучение в реальном времени» или RTRL,[68][69] который является примером автоматическая дифференциация в режиме прямого накопления со сложенными касательными векторами. В отличие от BPTT, этот алгоритм является локальным во времени, но не локальным в пространстве.
В этом контексте локальный в пространстве означает, что вектор весов единицы может быть обновлен с использованием только информации, хранящейся в подключенных единицах и самой единице, так что сложность обновления отдельной единицы линейна по размерности вектора весов. Локальный по времени означает, что обновления происходят постоянно (онлайн) и зависят только от самого последнего временного шага, а не от нескольких временных шагов в пределах заданного временного горизонта, как в BPTT. Биологические нейронные сети кажутся локальными как во времени, так и в пространстве.[70][71]
Для рекурсивного вычисления частных производных RTRL имеет временную сложность O (количество скрытых x, количество весов) на временной шаг для вычисления Матрицы Якоби, в то время как BPTT принимает только O (количество весов) за временной шаг за счет сохранения всех прямых активаций в пределах данного временного горизонта.[72] Существует онлайн-гибрид между BPTT и RTRL с промежуточной сложностью,[73][74] наряду с вариантами для непрерывного времени.[75]
Основная проблема с градиентным спуском для стандартных архитектур RNN заключается в том, что градиенты ошибок исчезают экспоненциально быстро с размером временного интервала между важными событиями.[39][76] LSTM в сочетании с гибридным методом обучения BPTT / RTRL пытается решить эти проблемы.[10] Эта проблема также решена в независимо рекуррентной нейронной сети (IndRNN).[31] путем сведения контекста нейрона к его собственному прошлому состоянию, и информация о кросс-нейронах может быть исследована на следующих уровнях. Воспоминания различного диапазона, включая долговременную память, могут быть изучены без проблемы исчезновения и взрыва градиента.
Он-лайн алгоритм, называемый причинно-рекурсивным обратным распространением (CRBP), реализует и объединяет парадигмы BPTT и RTRL для локально рекуррентных сетей.[77] Он работает с наиболее распространенными локально повторяющимися сетями. Алгоритм CRBP может минимизировать глобальную ошибку. Этот факт повышает стабильность алгоритма, обеспечивая единый взгляд на методы расчета градиента для рекуррентных сетей с локальной обратной связью.
Один из подходов к вычислению градиентной информации в RNN с произвольной архитектурой основан на построении диаграмм потоков сигналов.[78] Он использует пакетный алгоритм BPTT, основанный на теореме Ли для расчета чувствительности сети.[79] Его предложили Ван и Бофайс, а его быстрая онлайн-версия - Камполуччи, Унчини и Пьяцца.[79]
Методы глобальной оптимизации
Обучение весов в нейронной сети можно смоделировать как нелинейную глобальная оптимизация проблема. Целевая функция может быть сформирована для оценки соответствия или ошибки конкретного вектора весов следующим образом: сначала веса в сети устанавливаются в соответствии с вектором весов. Затем сеть сравнивается с обучающей последовательностью. Обычно сумма квадратов разности между предсказаниями и целевыми значениями, указанными в обучающей последовательности, используется для представления ошибки текущего вектора весовых коэффициентов. Затем можно использовать произвольные методы глобальной оптимизации для минимизации этой целевой функции.
Наиболее распространенный метод глобальной оптимизации для обучения RNN - это генетические алгоритмы, особенно в неструктурированных сетях.[80][81][82]
Первоначально генетический алгоритм кодируется с помощью весов нейронной сети предопределенным образом, где один ген в хромосома представляет собой одно звено веса. Вся сеть представлена в виде одной хромосомы. Фитнес-функция оценивается следующим образом:
- Каждый весовой коэффициент, закодированный в хромосоме, назначается соответствующему весовому звену сети.
- Обучающий набор передается в сеть, которая распространяет входные сигналы вперед.
- Среднеквадратичная ошибка возвращается в фитнес-функцию.
- Эта функция управляет процессом генетического отбора.
Многие хромосомы составляют популяцию; поэтому многие разные нейронные сети развиваются до тех пор, пока не будет удовлетворен критерий остановки. Распространенная схема остановки:
- Когда нейронная сеть изучила определенный процент обучающих данных или
- Когда минимальное значение среднеквадратичной ошибки удовлетворяется или
- Когда достигнуто максимальное количество обучающих поколений.
Критерий остановки оценивается функцией приспособленности, поскольку она получает обратную величину среднеквадратичной ошибки от каждой сети во время обучения.Следовательно, цель генетического алгоритма - максимизировать функцию приспособленности, уменьшая среднеквадратичную ошибку.
Другие глобальные (и / или эволюционные) методы оптимизации могут быть использованы для поиска хорошего набора весов, например: имитация отжига или же оптимизация роя частиц.
Связанные поля и модели
RNN могут вести себя хаотично. В таких случаях, теория динамических систем может использоваться для анализа.
Они на самом деле рекурсивные нейронные сети с особой структурой: линейной цепью. В то время как рекурсивные нейронные сети работают с любой иерархической структурой, комбинируя дочерние представления в родительские представления, рекуррентные нейронные сети работают с линейной прогрессией времени, объединяя предыдущий временной шаг и скрытое представление в представление для текущего временного шага.
В частности, RNN могут появляться как нелинейные версии конечная импульсная характеристика и бесконечный импульсный отклик фильтры, а также как нелинейная авторегрессионная экзогенная модель (НАРКС).[83]
Библиотеки
- Apache Singa
- Кафе: Создано Berkeley Vision and Learning Center (BVLC). Он поддерживает как CPU, так и GPU. Разработано в C ++, и имеет Python и MATLAB обертки.
- Chainer: Первая стабильная библиотека глубокого обучения, поддерживающая динамические нейронные сети, определяемые по запуску. Полностью на Python, производственная поддержка CPU, GPU, распределенное обучение.
- Deeplearning4j: Глубокое обучение в Ява и Scala на мульти-GPU с поддержкой Искра. Универсальный библиотека глубокого обучения для JVM производственный стек, работающий на Механизм научных вычислений C ++. Позволяет создавать собственные слои. Интегрируется с Hadoop и Кафка.
- Dynet: Набор инструментов динамических нейронных сетей.
- Поток: включает интерфейсы для RNN, включая GRU и LSTM, написанные на Юля.
- Керас: Высокоуровневый, простой в использовании API, предоставляющий оболочку для многих других библиотек глубокого обучения.
- Microsoft Cognitive Toolkit
- MXNet: современная платформа глубокого обучения с открытым исходным кодом, используемая для обучения и развертывания глубоких нейронных сетей.
- Весло Весло (https://github.com/paddlepaddle/paddle ): PaddlePaddle (параллельное распределенное глубокое обучение) - это платформа глубокого обучения, которая изначально была разработана учеными и инженерами Baidu с целью применения глубокого обучения ко многим продуктам Baidu.
- PyTorch: Тензоры и динамические нейронные сети на Python с сильным ускорением графического процессора.
- TensorFlow: Theano-подобная библиотека с лицензией Apache 2.0 с поддержкой CPU, GPU и проприетарной системы Google. ТПУ,[84] мобильный
- Theano: Эталонная библиотека глубокого обучения для Python с API, в значительной степени совместимая с популярными NumPy библиотека. Позволяет пользователю писать символьные математические выражения, а затем автоматически генерировать их производные, избавляя пользователя от необходимости кодировать градиенты или обратное распространение. Эти символьные выражения автоматически компилируются в код CUDA для быстрой реализации на GPU.
- Факел (www.torch.ch ): Научная вычислительная среда с широкой поддержкой алгоритмов машинного обучения, написанная на C и lua. Основным автором является Ронан Коллобер, и теперь он используется в Facebook AI Research и Twitter.
Приложения
Приложения рекуррентных нейронных сетей включают:
- Машинный перевод[18]
- Управление роботом[85]
- Прогнозирование временных рядов[86][87][88]
- Распознавание речи[89][90][91]
- Синтез речи[92]
- Обнаружение аномалий временного ряда[93]
- Обучение ритму[94]
- Музыкальная композиция[95]
- Изучение грамматики[96][97][98]
- Распознавание почерка[99][100]
- Признание действий человека[101]
- Обнаружение гомологии белков[102]
- Прогнозирование субклеточной локализации белков[52]
- Несколько задач прогнозирования в области управления бизнес-процессами[103]
- Прогнозирование путей оказания медицинской помощи[104]
Рекомендации
- ^ Дюпон, Сэмюэл (2019). «Подробный обзор современного развития нейросетевых структур». Ежегодные обзоры под контролем. 14: 200–230.
- ^ Абиодун, Олударе Исаак; Джантан, Аман; Омолара, Абиодун Эстер; Дада, Кеми Виктория; Мохамед, Начаат Абделатиф; Аршад, Хумаира (01.11.2018). «Современное состояние приложений искусственных нейронных сетей: обзор». Гелион. 4 (11): e00938. Дои:10.1016 / j.heliyon.2018.e00938. ISSN 2405-8440. ЧВК 6260436. PMID 30519653.
- ^ Тилаб, Ахмед (2018-12-01). «Прогнозирование временных рядов с использованием методологий искусственных нейронных сетей: систематический обзор». Журнал "Будущие вычисления и информатика". 3 (2): 334–340. Дои:10.1016 / j.fcij.2018.10.003. ISSN 2314-7288.
- ^ Могилы, Алексей; Ливицки, Маркус; Фернандес, Сантьяго; Бертолами, Роман; Бунке, Хорст; Шмидхубер, Юрген (2009). «Новая система коннекционистов для улучшенного распознавания рукописного ввода» (PDF). IEEE Transactions по анализу шаблонов и машинному анализу. 31 (5): 855–868. CiteSeerX 10.1.1.139.4502. Дои:10.1109 / тпами.2008.137. PMID 19299860. S2CID 14635907.
- ^ а б Сак, Хашим; Старший, Андрей; Бофай, Франсуаза (2014). «Рекуррентные архитектуры нейронных сетей с кратковременной памятью для крупномасштабного акустического моделирования» (PDF).
- ^ а б Ли, Сянган; У, Сихун (2014-10-15). «Построение глубоких рекуррентных нейронных сетей на основе кратковременной памяти для распознавания речи с большим словарным запасом». arXiv:1410.4281 [cs.CL ].
- ^ Милянович, Милош (февраль – март 2012 г.). «Сравнительный анализ нейронных сетей с рекуррентным и конечным импульсным откликом при прогнозировании временных рядов» (PDF). Индийский журнал компьютеров и инженерии. 3 (1).
- ^ Уильямс, Рональд Дж .; Хинтон, Джеффри Э .; Румелхарт, Дэвид Э. (октябрь 1986 г.). «Изучение представлений путем обратного распространения ошибок». Природа. 323 (6088): 533–536. Bibcode:1986Натура.323..533R. Дои:10.1038 / 323533a0. ISSN 1476-4687. S2CID 205001834.
- ^ а б Шмидхубер, Юрген (1993). Кандидатская диссертация: Системное моделирование и оптимизация (PDF). Страница 150 и далее демонстрирует присвоение кредитов по эквиваленту 1200 уровней в развернутой RNN.
- ^ а б Хохрайтер, Зепп; Шмидхубер, Юрген (1 ноября 1997 г.). «Кратковременная долговременная память». Нейронные вычисления. 9 (8): 1735–1780. Дои:10.1162 / neco.1997.9.8.1735. PMID 9377276. S2CID 1915014.
- ^ Фернандес, Сантьяго; Грейвс, Алекс; Шмидхубер, Юрген (2007). Применение рекуррентных нейронных сетей для распознавания ключевых слов. Материалы 17-й Международной конференции по искусственным нейронным сетям. ICANN'07. Берлин, Гейдельберг: Springer-Verlag. С. 220–229. ISBN 978-3-540-74693-5.
- ^ а б c Шмидхубер, Юрген (январь 2015 г.). «Глубокое обучение в нейронных сетях: обзор». Нейронные сети. 61: 85–117. arXiv:1404.7828. Дои:10.1016 / j.neunet.2014.09.003. PMID 25462637. S2CID 11715509.
- ^ Грейвс, Алекс; Шмидхубер, Юрген (2009). Бенджио, Йошуа; Шурманс, Дейл; Лафферти, Джон; Уильямс, редактор Крис - К. Я.; Кулотта, Арон (ред.). «Распознавание рукописного ввода в автономном режиме с помощью многомерных рекуррентных нейронных сетей». Фонд нейронных систем обработки информации (NIPS): 545–552. Цитировать журнал требует
| журнал =(помощь) - ^ Ханнун, Авни; Кейс, Карл; Каспер, Джаред; Катандзаро, Брайан; Диамос, Грег; Эльзен, Эрих; Пренгер, Райан; Сатиш, Санджив; Сенгупта, Шубхо (17 декабря 2014 г.). «Глубокая речь: масштабирование сквозного распознавания речи». arXiv:1412.5567 [cs.CL ].
- ^ Fan, Bo; Ван, Лицзюань; Сунг, Фрэнк К .; Се, Лэй (2015) «Говорящая голова с реальным фото с глубоким двунаправленным LSTM», в Материалы ICASSP 2015
- ^ Дзен, Хейга; Сак, Хашим (2015). «Однонаправленная рекуррентная нейронная сеть с долговременной кратковременной памятью с рекуррентным выходным уровнем для синтеза речи с малой задержкой» (PDF). Google.com. ICASSP. С. 4470–4474.
- ^ Сак, Хашим; Старший, Андрей; Рао, Канишка; Бофейс, Франсуаза; Шалквик, Йохан (сентябрь 2015 г.). «Голосовой поиск Google: быстрее и точнее».
- ^ а б Суцкевер Илья; Виньялс, Ориол; Ле, Куок В. (2014). «Последовательность для последовательного обучения с помощью нейронных сетей» (PDF). Электронные материалы конференции по системам обработки нейронной информации. 27: 5346. arXiv:1409.3215. Bibcode:2014arXiv1409.3215S.
- ^ Юзефович, Рафаль; Виньялс, Ориол; Шустер, Майк; Шазир, Ноам; У Юнхуэй (07.02.2016). «Изучение границ языкового моделирования». arXiv:1602.02410 [cs.CL ].
- ^ Гиллик, Дэн; Бранк, Клифф; Виньялс, Ориол; Субраманья, Амарнаг (30 ноября 2015 г.). «Многоязычная обработка байтов». arXiv:1512.00103 [cs.CL ].
- ^ Виньялс, Ориол; Тошев Александр; Бенджио, Сами; Эрхан, Думитру (17 ноября 2014 г.). «Покажи и расскажи: генератор заголовков нейронных изображений». arXiv:1411.4555 [cs.CV ].
- ^ «Обзор аппаратных ускорителей и методов оптимизации для RNN», JSA, 2020 г. PDF
- ^ а б Круз, Холк; Нейронные сети как кибернетические системы, 2-е и исправленное издание
- ^ Элман, Джеффри Л. (1990). «Нахождение структуры во времени». Наука о мышлении. 14 (2): 179–211. Дои:10.1016 / 0364-0213 (90) 90002-Е.
- ^ Джордан, Майкл И. (1 января 1997 г.). «Последовательный порядок: подход с параллельной распределенной обработкой». Нейросетевые модели познания - биоповеденческие основы. Успехи в психологии. Нейросетевые модели познания. 121. С. 471–495. Дои:10.1016 / s0166-4115 (97) 80111-2. ISBN 9780444819314.
- ^ Коско, Барт (1988). «Двунаправленные ассоциативные воспоминания». IEEE Transactions по системам, человеку и кибернетике. 18 (1): 49–60. Дои:10.1109/21.87054. S2CID 59875735.
- ^ Раккияппан, Раджан; Чандрасекар, Аруначалам; Лакшманан, Субраманиан; Пак, Джу Х. (2 января 2015 г.). «Экспоненциальная устойчивость для марковских скачкообразных стохастических нейронных сетей BAM с зависимыми от режима вероятностными изменяющимися во времени задержками и импульсным управлением». Сложность. 20 (3): 39–65. Bibcode:2015Cmplx..20c..39R. Дои:10.1002 / cplx.21503.
- ^ Рохас, Рауль (1996). Нейронные сети: систематическое введение. Springer. п. 336. ISBN 978-3-540-60505-8.
- ^ Джегер, Герберт; Хаас, Харальд (2004-04-02). «Использование нелинейности: прогнозирование хаотических систем и экономия энергии в беспроводной связи». Наука. 304 (5667): 78–80. Bibcode:2004 Наука ... 304 ... 78J. CiteSeerX 10.1.1.719.2301. Дои:10.1126 / science.1091277. PMID 15064413. S2CID 2184251.
- ^ Маасс, Вольфганг; Натшлегер, Томас; Маркрам, Генри (20 августа 2002). «Новый взгляд на вычисления в реальном времени в общих рекуррентных нейронных цепях». Технический отчет. Институт теоретической информатики, Технический университет Граца. Цитировать журнал требует
| журнал =(помощь) - ^ а б Ли, Шуай; Ли, Ванцин; Кук, Крис; Zhu, Ce; Янбо, Гао (2018). «Независимо рекуррентная нейронная сеть (IndRNN): создание более длинной и глубокой RNN». arXiv:1803.04831 [cs.CV ].
- ^ Голлер, Кристоф; Кюхлер, Андреас (1996). Изучение зависимых от задачи распределенных представлений путем обратного распространения через структуру. Международная конференция IEEE по нейронным сетям. 1. п. 347. CiteSeerX 10.1.1.52.4759. Дои:10.1109 / ICNN.1996.548916. ISBN 978-0-7803-3210-2. S2CID 6536466.
- ^ Линнаинмаа, Сеппо (1970). Представление кумулятивной ошибки округления алгоритма в виде разложения Тейлора локальных ошибок округления. M.Sc. защитил диссертацию (на финском языке) в Хельсинкском университете.
- ^ Гриванк, Андреас; Вальтер, Андреа (2008). Оценка производных: принципы и методы алгоритмической дифференциации (Второе изд.). СИАМ. ISBN 978-0-89871-776-1.
- ^ Сохер, Ричард; Лин, Клифф; Ng, Andrew Y .; Мэннинг, Кристофер Д., «Анализ естественных сцен и естественного языка с помощью рекурсивных нейронных сетей» (PDF), 28-я Международная конференция по машинному обучению (ICML 2011)
- ^ Сохер, Ричард; Перелыгин Алексей; Wu, Jean Y .; Чуанг, Джейсон; Мэннинг, Кристофер Д.; Ng, Andrew Y .; Поттс, Кристофер. «Рекурсивные глубинные модели для семантической композиционности по банку дерева настроений» (PDF). Emnlp 2013.
- ^ а б c d Шмидхубер, Юрген (1992). «Изучение сложных, расширенных последовательностей с использованием принципа сжатия истории» (PDF). Нейронные вычисления. 4 (2): 234–242. Дои:10.1162 / neco.1992.4.2.234. S2CID 18271205.
- ^ Шмидхубер, Юрген (2015). «Глубокое обучение». Scholarpedia. 10 (11): 32832. Bibcode:2015SchpJ..1032832S. Дои:10.4249 / scholarpedia.32832.
- ^ а б c Хохрайтер, Зепп (1991), Untersuchungen zu Dynamischen Neuronalen Netzen, Дипломная работа, Institut f. Informatik, Technische Univ. Мюнхен, советник Юрген Шмидхубер
- ^ Джайлз, К. Ли; Миллер, Клиффорд Б .; Чен, Донг; Чен, Синь-Хен; Сунь, Го-Чжэн; Ли, Йи-Чун (1992). «Изучение и извлечение конечных автоматов с рекуррентными нейронными сетями второго порядка» (PDF). Нейронные вычисления. 4 (3): 393–405. Дои:10.1162 / neco.1992.4.3.393. S2CID 19666035.
- ^ Омлин, Кристиан У .; Джайлз, К. Ли (1996). «Построение детерминированных конечных автоматов в рекуррентных нейронных сетях». Журнал ACM. 45 (6): 937–972. CiteSeerX 10.1.1.32.2364. Дои:10.1145/235809.235811. S2CID 228941.
- ^ Gers, Felix A .; Schraudolph, Nicol N .; Шмидхубер, Юрген (2002). «Изучение точного времени с помощью рекуррентных сетей LSTM» (PDF). Журнал исследований в области машинного обучения. 3: 115–143. Получено 2017-06-13.
- ^ Байер, Джастин; Виерстра, Даан; Тогелиус, Юлиан; Шмидхубер, Юрген (14 сентября 2009 г.). Развитие структур ячеек памяти для последовательного обучения (PDF). Искусственные нейронные сети - ICANN 2009. Конспект лекций по информатике. 5769. Берлин, Гейдельберг: Springer. С. 755–764. Дои:10.1007/978-3-642-04277-5_76. ISBN 978-3-642-04276-8.
- ^ Фернандес, Сантьяго; Грейвс, Алекс; Шмидхубер, Юрген (2007). «Маркировка последовательностей в структурированных доменах с иерархическими рекуррентными нейронными сетями». Proc. 20-я Международная совместная конференция по искусственному контролю, Иджчай, 2007 г.: 774–779. CiteSeerX 10.1.1.79.1887.
- ^ Грейвс, Алекс; Фернандес, Сантьяго; Гомес, Фаустино Дж. (2006). «Временная классификация коннекционистов: маркировка несегментированных данных последовательности с помощью рекуррентных нейронных сетей». Материалы Международной конференции по машинному обучению: 369–376. CiteSeerX 10.1.1.75.6306.
- ^ Gers, Felix A .; Шмидхубер, Юрген (ноябрь 2001 г.). «Рекуррентные сети LSTM изучают простые контекстно-зависимые и контекстно-зависимые языки». IEEE-транзакции в нейронных сетях. 12 (6): 1333–1340. Дои:10.1109/72.963769. ISSN 1045-9227. PMID 18249962. S2CID 10192330.
- ^ Черт возьми, Джоэл; Салем, Фатхи М. (12 января 2017 г.). «Упрощенные минимальные вариации стробированных единиц для рекуррентных нейронных сетей». arXiv:1701.03452 [cs.NE ].
- ^ Дей, Рахул; Салем, Фатхи М. (20 января 2017 г.). "Gate-варианты нейронных сетей Gated Recurrent Unit (GRU)". arXiv:1701.05923 [cs.NE ].
- ^ Чунг, Чжунён; Гульчере, Чаглар; Чо, Кён Хён; Бенжио, Йошуа (2014). «Эмпирическая оценка стробированных рекуррентных нейронных сетей при моделировании последовательности». arXiv:1412.3555 [cs.NE ].
- ^ Бритц, Денни (27 октября 2015 г.). "Учебное пособие по рекуррентным нейронным сетям, часть 4 - Реализация RNN GRU / LSTM с помощью Python и Theano - WildML". Wildml.com. Получено 18 мая, 2016.
- ^ Грейвс, Алекс; Шмидхубер, Юрген (01.07.2005). «Покадровая классификация фонем с двунаправленным LSTM и другими архитектурами нейронных сетей». Нейронные сети. IJCNN 2005. 18 (5): 602–610. CiteSeerX 10.1.1.331.5800. Дои:10.1016 / j.neunet.2005.06.042. PMID 16112549.
- ^ а б Тиреу, Триас; Рецко, Мартин (июль 2007 г.). «Двунаправленные сети долгосрочной краткосрочной памяти для прогнозирования субклеточной локализации эукариотических белков». IEEE / ACM Transactions по вычислительной биологии и биоинформатике. 4 (3): 441–446. Дои:10.1109 / tcbb.2007.1015. PMID 17666763. S2CID 11787259.
- ^ Харви, Инман; Мужья, Фил; Клифф, Дэйв (1994), «Увидеть свет: искусственная эволюция, настоящее видение», 3-я международная конференция по моделированию адаптивного поведения: от животных к аниматам 3, стр. 392–401
- ^ Куинн, Мэтью (2001). «Развитие коммуникации без выделенных каналов связи». Успехи в искусственной жизни. Конспект лекций по информатике. 2159. С. 357–366. CiteSeerX 10.1.1.28.5890. Дои:10.1007 / 3-540-44811-X_38. ISBN 978-3-540-42567-0. Отсутствует или пусто
| название =(помощь) - ^ Пиво, Рэндалл Д. (1997). «Динамика адаптивного поведения: исследовательская программа». Робототехника и автономные системы. 20 (2–4): 257–289. Дои:10.1016 / S0921-8890 (96) 00063-2.
- ^ Шерстинский, Алексей (07.12.2018). Блум-Редди, Бенджамин; Пейдж, Брукс; Куснер, Мэтт; Каруана, Рич; Рейнфорт, Том; Тех, Йи Уай (ред.). Получение определения рекуррентной нейронной сети и развертывание RNN с использованием обработки сигналов. Семинар «Критика и коррекция тенденций в машинном обучении» на NeurIPS-2018.
- ^ Пейн, Райнер У .; Тани, июн (01.09.2005). «Как самоорганизуется иерархическое управление в искусственных адаптивных системах». Адаптивное поведение. 13 (3): 211–225. Дои:10.1177/105971230501300303. S2CID 9932565.
- ^ Тутку, Курт (июнь 1995). Рекуррентные многослойные персептроны для идентификации и управления: путь к приложениям. Отчет об исследованиях Института компьютерных наук. 118. Университет Вюрцбурга на Хубланде. CiteSeerX 10.1.1.45.3527.CS1 maint: дата и год (связь)
- ^ Ямасита, Юичи; Тани, июн (07.11.2008). «Появление функциональной иерархии в модели нейронной сети с множеством временных масштабов: эксперимент с гуманоидным роботом». PLOS вычислительная биология. 4 (11): e1000220. Bibcode:2008PLSCB ... 4E0220Y. Дои:10.1371 / journal.pcbi.1000220. ЧВК 2570613. PMID 18989398.
- ^ Альнаджар, Фади; Ямасита, Юичи; Тани, июн (2013). «Иерархическая и функциональная взаимосвязь когнитивных механизмов более высокого порядка: нейроботическая модель для исследования стабильности и гибкости рабочей памяти». Границы нейроробототехники. 7: 2. Дои:10.3389 / fnbot.2013.00002. ЧВК 3575058. PMID 23423881.
- ^ Грейвс, Алекс; Уэйн, Грег; Данихелка, Иво (2014). «Нейронные машины Тьюринга». arXiv:1410.5401 [cs.NE ].
- ^ Сунь, Го-Чжэн; Джайлз, К. Ли; Чен, Син-Хен (1998). «Автомат нейронной сети: архитектура, динамика и обучение». В Джайлсе, К. Ли; Гори, Марко (ред.). Адаптивная обработка последовательностей и структур данных. Конспект лекций по информатике. Берлин, Гейдельберг: Springer. С. 296–345. CiteSeerX 10.1.1.56.8723. Дои:10.1007 / bfb0054003. ISBN 9783540643418.
- ^ Снайдер, Грег (2008), «Корковые вычисления с мемристивными наноустройствами», Обзор Sci-DAC, 10: 58–65
- ^ Каравелли, Франческо; Траверса, Фабио Лоренцо; Ди Вентра, Массимилиано (2017). «Сложная динамика мемристических схем: аналитические результаты и универсальная медленная релаксация». Физический обзор E. 95 (2): 022140. arXiv:1608.08651. Bibcode:2017PhRvE..95b2140C. Дои:10.1103 / PhysRevE.95.022140. PMID 28297937. S2CID 6758362.
- ^ Каравелли, Франческо (07.11.2019). «Асимптотическое поведение мемристических цепей». Энтропия. 21 (8): 789. Bibcode:2019Entrp..21..789C. Дои:10.3390 / e21080789. ЧВК 789.
- ^ Вербос, Пол Дж. (1988). «Обобщение обратного распространения ошибки применительно к повторяющейся модели газового рынка». Нейронные сети. 1 (4): 339–356. Дои:10.1016 / 0893-6080 (88) 90007-х.
- ^ Румелхарт, Дэвид Э. (1985). Изучение внутренних представлений путем распространения ошибок. Сан-Диего (Калифорния): Институт когнитивных наук Калифорнийского университета.
- ^ Робинсон, Энтони Дж .; Фолсайд, Фрэнк (1987). Сеть распространения динамических ошибок, управляемая служебными программами. Технический отчет CUED / F-INFENG / TR.1. Департамент инженерии Кембриджского университета.
- ^ Уильямс, Рональд Дж .; Ципсер, Д. (1 февраля 2013 г.). «Алгоритмы обучения на основе градиентов для рекуррентных сетей и их вычислительная сложность». В Шовене, Ив; Румелхарт, Дэвид Э. (ред.). Обратное распространение: теория, архитектура и приложения. Психология Press. ISBN 978-1-134-77581-1.
- ^ Шмидхубер, Юрген (01.01.1989). «Алгоритм локального обучения для динамических сетей с прямой связью и рекуррентных сетей». Связь Наука. 1 (4): 403–412. Дои:10.1080/09540098908915650. S2CID 18721007.
- ^ Príncipe, José C .; Euliano, Neil R .; Лефевр, В. Курт (2000). Нейронные и адаптивные системы: основы посредством моделирования. Вайли. ISBN 978-0-471-35167-2.
- ^ Янн, Оливье; Таллек, Корентин; Шарпи, Гийом (28 июля 2015). «Обучение рекуррентных сетей в режиме онлайн без возврата». arXiv:1507.07680 [cs.NE ].
- ^ Шмидхубер, Юрген (1992-03-01). "Алгоритм обучения с фиксированным размером хранилища O (n3) времени для полностью рекуррентных, постоянно работающих сетей". Нейронные вычисления. 4 (2): 243–248. Дои:10.1162 / neco.1992.4.2.243. S2CID 11761172.
- ^ Уильямс, Рональд Дж. (1989). «Сложность алгоритмов вычисления точных градиентов для рекуррентных нейронных сетей». Технический отчет NU-CCS-89-27. Бостон (MA): Северо-Восточный университет, Колледж компьютерных наук. Цитировать журнал требует
| журнал =(помощь) - ^ Перлмуттер, Барак А. (01.06.1989). "Изучение траекторий пространства состояний в рекуррентных нейронных сетях". Нейронные вычисления. 1 (2): 263–269. Дои:10.1162 / neco.1989.1.2.263. S2CID 16813485.
- ^ Хохрайтер, Зепп; и другие. (15 января 2001 г.). «Градиентный поток в повторяющихся сетях: трудность изучения долгосрочных зависимостей». В Колене, Джон Ф .; Кремер, Стефан С. (ред.). Полевое руководство по динамическим рекуррентным сетям. Джон Вили и сыновья. ISBN 978-0-7803-5369-5.
- ^ Камполуччи, Паоло; Унчини, Аурелио; Пьяцца, Франческо; Рао, Бхаскар Д. (1999). «Алгоритмы онлайн-обучения для локально рекуррентных нейронных сетей». IEEE-транзакции в нейронных сетях. 10 (2): 253–271. CiteSeerX 10.1.1.33.7550. Дои:10.1109/72.750549. PMID 18252525.
- ^ Ван, Эрик А.; Бофайс, Франсуаза (1996). «Схематический вывод градиентных алгоритмов для нейронных сетей». Нейронные вычисления. 8: 182–201. Дои:10.1162 / neco.1996.8.1.182. S2CID 15512077.
- ^ а б Камполуччи, Паоло; Унчини, Аурелио; Пьяцца, Франческо (2000). «Подход сигнально-потокового графа к онлайн-расчету градиента». Нейронные вычисления. 12 (8): 1901–1927. CiteSeerX 10.1.1.212.5406. Дои:10.1162/089976600300015196. PMID 10953244. S2CID 15090951.
- ^ Гомес, Фаустино Дж .; Мииккулайнен, Ристо (1999), «Решение немарковских задач управления с помощью нейроэволюции» (PDF), IJCAI 99, Морган Кауфманн, получено 5 августа 2017
- ^ Сайед, Омар (май 1995 г.). «Применение генетических алгоритмов к рекуррентным нейронным сетям для изучения сетевых параметров и архитектуры». M.Sc. докторская диссертация, факультет электротехники, Западный резервный университет Кейс, советник Ёсиясу Такефудзи.
- ^ Гомес, Фаустино Дж .; Шмидхубер, Юрген; Мииккулайнен, Ристо (июнь 2008 г.). «Ускоренная нейронная эволюция через кооперативно коэволюционирующие синапсы». Журнал исследований в области машинного обучения. 9: 937–965.
- ^ Siegelmann, Hava T .; Хорн, Билл Дж .; Джайлз, К. Ли (1995). «Вычислительные возможности рекуррентных нейронных сетей NARX». IEEE Transactions on Systems, Man and Cybernetics, Part B (Cybernetics). 27 (2): 208–15. CiteSeerX 10.1.1.48.7468. Дои:10.1109/3477.558801. PMID 18255858.
- ^ Мец, Кейд (18 мая 2016 г.). «Google создал свои собственные чипы для работы своих AI-ботов». Проводной.
- ^ Майер, Германн; Гомес, Фаустино Дж .; Виерстра, Даан; Надь, Иштван; Кнолль, Алоис; Шмидхубер, Юрген (октябрь 2006 г.). Система для роботизированной кардиохирургии, которая учится связывать узлы с помощью рекуррентных нейронных сетей. 2006 Международная конференция IEEE / RSJ по интеллектуальным роботам и системам. С. 543–548. CiteSeerX 10.1.1.218.3399. Дои:10.1109 / IROS.2006.282190. ISBN 978-1-4244-0258-8. S2CID 12284900.
- ^ Виерстра, Даан; Шмидхубер, Юрген; Гомес, Фаустино Дж. (2005). "Evolino: гибридная нейроэволюция / Оптимальный линейный поиск для последовательного обучения". Труды 19-й Международной совместной конференции по искусственному интеллекту (IJCAI), Эдинбург: 853–858.
- ^ Петнехази, Габор (1 января 2019 г.). «Рекуррентные нейронные сети для прогнозирования временных рядов». arXiv:1901.00069 [cs.LG ].
- ^ Хевамалаге, Хансика; Бергмейр, Кристоф; Бандара, Касун (2020). «Рекуррентные нейронные сети для прогнозирования временных рядов: текущее состояние и будущие направления». Международный журнал прогнозирования. 37: 388–427. arXiv:1909.00590. Дои:10.1016 / j.ijforecast.2020.06.008. S2CID 202540863.
- ^ Грейвс, Алекс; Шмидхубер, Юрген (2005). «Покадровая классификация фонем с двунаправленным LSTM и другими архитектурами нейронных сетей». Нейронные сети. 18 (5–6): 602–610. CiteSeerX 10.1.1.331.5800. Дои:10.1016 / j.neunet.2005.06.042. PMID 16112549.
- ^ Фернандес, Сантьяго; Грейвс, Алекс; Шмидхубер, Юрген (2007). Применение рекуррентных нейронных сетей для распознавания ключевых слов. Материалы 17-й Международной конференции по искусственным нейронным сетям. ICANN'07. Берлин, Гейдельберг: Springer-Verlag. С. 220–229. ISBN 978-3540746935.
- ^ Грейвс, Алекс; Мохамед, Абдель-Рахман; Хинтон, Джеффри Э. (2013). «Распознавание речи с глубокими рекуррентными нейронными сетями». Акустика, обработка речи и сигналов (ICASSP), Международная конференция IEEE 2013 г.: 6645–6649. arXiv:1303.5778. Bibcode:2013arXiv1303.5778G. Дои:10.1109 / ICASSP.2013.6638947. ISBN 978-1-4799-0356-6. S2CID 206741496.
- ^ Чанг, Эдвард Ф .; Чартье, Джош; Ануманчипалли, Гопала К. (24 апреля 2019 г.). «Синтез речи из нейронного декодирования устных предложений». Природа. 568 (7753): 493–498. Bibcode:2019Натура.568..493A. Дои:10.1038 / s41586-019-1119-1. ISSN 1476-4687. PMID 31019317. S2CID 129946122.
- ^ Малхотра, Панкадж; Виг, Ловекеш; Шрофф, Гаутам; Агарвал, Пунит (апрель 2015 г.). «Сети долгосрочной краткосрочной памяти для обнаружения аномалий во временных рядах» (PDF). Европейский симпозиум по искусственным нейронным сетям, вычислительному интеллекту и машинному обучению - ESANN 2015.
- ^ Gers, Felix A .; Schraudolph, Nicol N .; Шмидхубер, Юрген (2002). «Изучение точного времени с помощью повторяющихся сетей LSTM» (PDF). Журнал исследований в области машинного обучения. 3: 115–143.
- ^ Эк, Дуглас; Шмидхубер, Юрген (28 августа 2002 г.). Изучение долгосрочной структуры блюза. Искусственные нейронные сети - ICANN 2002. Конспект лекций по информатике. 2415. Берлин, Гейдельберг: Springer. С. 284–289. CiteSeerX 10.1.1.116.3620. Дои:10.1007/3-540-46084-5_47. ISBN 978-3540460848.
- ^ Шмидхубер, Юрген; Gers, Felix A .; Экк, Дуглас (2002). «Изучение нерегулярных языков: сравнение простых повторяющихся сетей и LSTM». Нейронные вычисления. 14 (9): 2039–2041. CiteSeerX 10.1.1.11.7369. Дои:10.1162/089976602320263980. PMID 12184841. S2CID 30459046.
- ^ Gers, Felix A .; Шмидхубер, Юрген (2001). «Рекуррентные сети LSTM изучают простые контекстно-свободные и контекстно-зависимые языки» (PDF). IEEE-транзакции в нейронных сетях. 12 (6): 1333–1340. Дои:10.1109/72.963769. PMID 18249962.
- ^ Перес-Ортис, Хуан Антонио; Gers, Felix A .; Эк, Дуглас; Шмидхубер, Юрген (2003). «Фильтры Калмана улучшают производительность сети LSTM в задачах, не решаемых традиционными повторяющимися сетями». Нейронные сети. 16 (2): 241–250. CiteSeerX 10.1.1.381.1992. Дои:10.1016 / s0893-6080 (02) 00219-8. PMID 12628609.
- ^ Грейвс, Алекс; Шмидхубер, Юрген (2009). «Распознавание рукописного ввода в автономном режиме с помощью многомерных рекуррентных нейронных сетей». Достижения в системах обработки нейронной информации 22, NIPS'22. Ванкувер (Британская Колумбия): MIT Press: 545–552.
- ^ Грейвс, Алекс; Фернандес, Сантьяго; Ливицки, Маркус; Бунке, Хорст; Шмидхубер, Юрген (2007). Неограниченное распознавание рукописного ввода в Интернете с помощью рекуррентных нейронных сетей. Материалы 20-й Международной конференции по системам обработки нейронной информации.. НИПС'07. Curran Associates Inc., стр. 577–584. ISBN 9781605603520.
- ^ Баккуш, Моэз; Мамалет, Франк; Вольф, Кристиан; Гарсия, Кристоф; Баскурт, Атилла (2011). Салах, Альберт Али; Лепри, Бруно (ред.). «Последовательное глубокое обучение для распознавания действий человека». 2-й Международный семинар по пониманию человеческого поведения (HBU). Конспект лекций по информатике. Амстердам, Нидерланды: Springer. 7065: 29–39. Дои:10.1007/978-3-642-25446-8_4. ISBN 978-3-642-25445-1.
- ^ Хохрайтер, Зепп; Heusel, Martin; Обермайер, Клаус (2007). «Быстрое определение гомологии белков на основе модели без выравнивания». Биоинформатика. 23 (14): 1728–1736. Дои:10.1093 / биоинформатика / btm247. PMID 17488755.
- ^ Налог, Ник; Веренич Илья; Ла Роза, Марчелло; Дюма, Марлон (2017). Прогнозный мониторинг бизнес-процессов с помощью нейронных сетей LSTM. Труды Международной конференции по передовой инженерии информационных систем (CAiSE). Конспект лекций по информатике. 10253. С. 477–492. arXiv:1612.02130. Дои:10.1007/978-3-319-59536-8_30. ISBN 978-3-319-59535-1. S2CID 2192354.
- ^ Чой, Эдвард; Бахадори, Мохаммад Таха; Шуэц, Энди; Стюарт, Уолтер Ф .; Сунь, Цзимэн (2016). «Доктор AI: Прогнозирование клинических событий с помощью рекуррентных нейронных сетей». Материалы 1-й конференции по машинному обучению для здравоохранения. 56: 301–318. arXiv:1511.05942. Bibcode:2015arXiv151105942C. ЧВК 5341604. PMID 28286600.
дальнейшее чтение
- Мандич, Данило П. и Чемберс, Джонатон А. (2001). Рекуррентные нейронные сети для прогнозирования: алгоритмы обучения, архитектуры и стабильность. Вайли. ISBN 978-0-471-49517-8.
внешняя ссылка
- Seq2SeqSharp Платформа рекуррентных нейронных сетей LSTM / BiLSTM / Transformer, работающая на процессорах и графических процессорах, для задач от последовательности к последовательности (C #, .СЕТЬ )
- RNNSharp CRF на основе рекуррентных нейронных сетей (C #, .СЕТЬ )
- Рекуррентные нейронные сети с более чем 60 работами РНН Юрген Шмидхубер группа в Институт исследований искусственного интеллекта Далле Молле
- Реализация нейронной сети Эльмана за WEKA
- Рекуррентные нейронные сети и LSTM в Java
- альтернативная попытка получения полного RNN / вознаграждения