Реляционная база данных - Relational database
А реляционная база данных это цифровой база данных на основе реляционная модель данных, как предлагает Э. Ф. Кодд в 1970 г.[1]Программная система, используемая для поддержки реляционных баз данных, является система управления реляционной базой данных (СУБД). Во многих системах реляционных баз данных есть возможность использовать SQL (Язык структурированных запросов) для запросов и обслуживания базы данных.[2]
История
Термин «реляционная база данных» был изобретен Э. Ф. Кодд в IBM в 1970 году. Кодд ввел этот термин в свою исследовательскую работу «Реляционная модель данных для больших общих банков данных».[3]В этой и последующих статьях он определил, что он имел в виду под словом «реляционный». Одно известное определение того, что составляет систему реляционной базы данных, состоит из 12 правил Кодда. Однако никакие коммерческие реализации реляционной модели не соответствуют всем правилам Кодда,[4] поэтому этот термин постепенно стал описывать более широкий класс систем баз данных, который как минимум:
- Представьте данные пользователю как связи (представление в табличной форме, т.е. как коллекция из столы с каждой таблицей, состоящей из набора строк и столбцов);
- Предоставьте реляционные операторы для управления данными в табличной форме.
В 1974 году IBM начала разработку Система R, исследовательский проект по разработке прототипа СУБД.[5][6]Первая система, продаваемая как СУБД, была Реляционное хранилище данных Multics (Июнь 1976 г.).[нужна цитата ] Oracle был выпущен в 1979 году компанией Relational Software, сейчас Корпорация Oracle.[7] Ingres и IBM BS12 последовал. Другие примеры СУБД включают: DB2, SAP Sybase ASE, и Informix. В 1984 году началась разработка первой СУБД для Macintosh под кодовым названием Silver Surfer, позже она была выпущена в 1987 году как 4-е измерение и известен сегодня как 4D.[8]
Первые системы, которые были относительно точными реализациями реляционной модели, были от:
- Университет Мичигана - Микро СУБД (1969)[нужна цитата ]
- Массачусетский технологический институт (1971)[9]
- Британский научный центр IBM в Питерли - IS1 (1970–72) и его преемник, PRTV (1973–79)
Наиболее распространенное определение РСУБД - это продукт, который представляет представление данных в виде набора строк и столбцов, даже если оно не основано строго на теория отношений. Согласно этому определению, продукты СУБД обычно реализуют некоторые, но не все из 12 правил Кодда.
Вторая школа мысли утверждает, что если база данных не реализует все правила Кодда (или текущее понимание реляционной модели, как выражено Кристофер Дж. Дат, Хью Дарвен и другие), это не относительное. Эта точка зрения, разделяемая многими теоретиками и другими строгими приверженцами принципов Кодда, дисквалифицирует большинство СУБД как нереляционных. Для пояснения они часто называют некоторые СУБД действительно реляционные системы управления базами данных (TRDBMS), называя других системы управления псевдореляционными базами данных (PRDBMS).
По состоянию на 2009 год в большинстве коммерческих реляционных СУБД используются SQL как их язык запросов.[10]
Были предложены и реализованы альтернативные языки запросов, в частности, реализация до 1996 г. Ingres QUEL.
Реляционная модель
Эта модель организует данные в один или несколько столы (или "отношения") столбцы и ряды, с уникальным ключом, идентифицирующим каждую строку. Ряды еще называют записи или же кортежи.[11] Столбцы также называются атрибутами. Как правило, каждая таблица / отношение представляет один «тип объекта» (например, покупателя или продукта). Строки представляют экземпляры этого типа объекта (например, «Ли» или «стул»), а столбцы - значения, приписываемые этому экземпляру (например, адрес или цена).
Например, каждая строка таблицы класса соответствует классу, а класс соответствует нескольким студентам, поэтому связь между таблицей классов и таблицей учеников - «один ко многим».[12]
Ключи
Каждая строка в таблице имеет свой уникальный ключ. Строки в таблице можно связать со строками в других таблицах, добавив столбец для уникального ключа связанной строки (такие столбцы известны как внешние ключи ). Кодд показал, что отношения данных произвольной сложности могут быть представлены простым набором концепций.[нужна цитата ]
Часть этой обработки включает в себя постоянную возможность выбора или изменения одной и только одной строки в таблице. Следовательно, большинство физических реализаций имеют уникальный первичный ключ (PK) для каждой строки в таблице. Когда в таблицу записывается новая строка, создается новое уникальное значение для первичного ключа; это ключ, который система использует в первую очередь для доступа к таблице. Производительность системы оптимизирована для ПК. Другое, больше естественные ключи также может быть идентифицирован и определен как альтернативные ключи (АК). Часто для формирования AK требуется несколько столбцов (это одна из причин, по которой один целочисленный столбец обычно превращается в PK). И PK, и AK имеют возможность однозначно идентифицировать строку в таблице. Для обеспечения уникального идентификатора по всему миру могут применяться дополнительные технологии, глобально уникальный идентификатор, когда есть более широкие системные требования.
Первичные ключи в базе данных используются для определения отношений между таблицами. Когда ПК переходит в другую таблицу, он становится внешним ключом в другой таблице. Когда каждая ячейка может содержать только одно значение, а PK переносится в обычную таблицу сущностей, этот шаблон проектирования может представлять либо один к одному или же один ко многим отношение. Большинство проектов реляционных баз данных решают многие-ко-многим отношения путем создания дополнительной таблицы, содержащей PK из обеих других таблиц сущностей - отношение становится сущностью; затем таблица разрешения именуется соответствующим образом, и два FK объединяются, чтобы сформировать PK. Миграция PK в другие таблицы - вторая основная причина, по которой целые числа, назначенные системой, обычно используются в качестве PK; обычно нет ни эффективности, ни ясности в переносе кучи других типов столбцов.
Отношения
Отношения - это логическая связь между различными таблицами, установленная на основе взаимодействия между этими таблицами.
Сделки
Чтобы система управления базами данных (СУБД) работала эффективно и точно, она должна использовать ACID транзакции.[13][14][15]
Хранимые процедуры
Наиболее[сомнительный ] программирования в СУБД выполняется с использованием хранимые процедуры (СП). Часто процедуры могут использоваться для значительного уменьшения объема информации, передаваемой внутри и вне системы. Для повышения безопасности проект системы может предоставлять доступ только к хранимым процедурам, а не напрямую к таблицам. Фундаментальные хранимые процедуры содержат логику, необходимую для вставки новых и обновления существующих данных. Могут быть написаны более сложные процедуры для реализации дополнительных правил и логики, связанных с обработкой или выбором данных.
Терминология
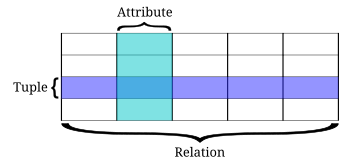
Реляционная база данных была впервые определена в июне 1970 г. Эдгар Кодд, из IBM Исследовательская лаборатория Сан-Хосе.[1] Взгляд Кодда на то, что квалифицируется как СУБД, кратко изложен в 12 правил Кодда. Реляционная база данных стала преобладающим типом базы данных. Другие модели, кроме реляционная модель включить иерархическая модель базы данных и сетевая модель.
В таблице ниже приведены некоторые из наиболее важных терминов реляционных баз данных и соответствующие SQL срок:
| Термин SQL | Термин реляционной базы данных | Описание |
|---|---|---|
| Ряд | Кортеж или же записывать | Набор данных, представляющий один элемент |
| Столбец | Атрибут или же поле | Помеченный элемент кортежа, например «Адрес» или «Дата рождения» |
| Стол | Связь или же Базовый отнвар | Набор кортежей с одинаковыми атрибутами; набор столбцов и строк |
| Вид или же набор результатов | Производный relvar | Любой набор кортежей; отчет о данных из СУБД в ответ на запрос |
Отношения или таблицы
А связь определяется как набор кортежи которые имеют то же самое атрибуты. Кортеж обычно представляет объект и информацию об этом объекте. Объекты обычно представляют собой физические объекты или концепции. Отношение обычно описывается как стол, который организован в ряды и столбцы. Все данные, на которые ссылается атрибут, находятся в одном домен и соответствовать тем же ограничениям.
Реляционная модель определяет, что кортежи отношения не имеют определенного порядка и что кортежи, в свою очередь, не устанавливают порядок атрибутов. Приложения получают доступ к данным, задавая запросы, которые используют такие операции, как Выбрать для определения кортежей, проект для определения атрибутов и присоединиться совместить отношения. Отношения можно изменить с помощью вставлять, Удалить, и Обновить операторы. Новые кортежи могут предоставлять явные значения или быть производными от запроса. Точно так же запросы идентифицируют кортежи для обновления или удаления.
Кортежи по определению уникальны. Если кортеж содержит кандидат или первичный ключ, тогда очевидно, что он уникален; однако не требуется определять первичный ключ, чтобы строка или запись были кортежем. Определение кортежа требует, чтобы он был уникальным, но не требует определения первичного ключа. Поскольку кортеж уникален, его атрибуты по определению составляют суперключ.
Базовые и производные отношения
В реляционной базе данных все данные хранятся и доступны через связи. Отношения, в которых хранятся данные, называются «базовыми отношениями», а в реализациях - «таблицами». Другие отношения не хранят данные, но вычисляются путем применения реляционных операций к другим отношениям. Эти отношения иногда называют «производными отношениями». В реализациях они называются "взгляды "или" запросы ". Производные отношения удобны тем, что они действуют как единое отношение, даже если они могут получать информацию из нескольких отношений. Кроме того, производные отношения могут использоваться как слой абстракции.
Домен
Домен описывает набор возможных значений для данного атрибута и может рассматриваться как ограничение на значение атрибута. Математически присоединение домена к атрибуту означает, что любое значение атрибута должно быть элементом указанного набора. Строка символов "Азбука", например, находится не в целочисленной области, а в целочисленном значении 123 является. Другой пример домена описывает возможные значения поля «CoinFace» как («Головы», «Решки»). Таким образом, поле CoinFace не принимает входные значения, такие как (0,1) или (H, T).
Ограничения
Ограничения позволяют дополнительно ограничить домен атрибута. Например, ограничение может ограничивать данный целочисленный атрибут значениями от 1 до 10. Ограничения обеспечивают один метод реализации бизнес правила в базе данных и поддерживает последующее использование данных на уровне приложений. SQL реализует функциональность ограничений в виде проверить ограничения. Ограничения ограничивают данные, которые могут храниться в связи. Обычно они определяются с помощью выражений, которые приводят к логический значение, указывающее, удовлетворяют ли данные ограничению. Ограничения могут применяться к отдельным атрибутам, к кортежу (ограничение комбинаций атрибутов) или ко всему отношению. Поскольку каждый атрибут имеет связанный домен, существуют ограничения (ограничения домена). Два основных правила реляционной модели известны как целостность сущности и ссылочная целостность.
Ссылочная целостность основана на простой концепции аналитических алгоритмов на основе реляционных векторов, обычно используемых в облачных платформах. Это позволяет обрабатывать несколько интерфейсов в ссылочной базе данных с дополнительной функцией добавления дополнительного уровня безопасности в динамически определяемую виртуальную среду.[16]
Первичный ключ
Каждый связь / table имеет первичный ключ, что является следствием того, что отношение является набор.[17] Первичный ключ однозначно определяет кортеж в таблице. Хотя естественные атрибуты (атрибуты, используемые для описания вводимых данных) иногда являются хорошими первичными ключами, суррогатные ключи вместо этого часто используются. Суррогатный ключ - это искусственный атрибут, присваиваемый объекту, который однозначно его идентифицирует (например, в таблице с информацией о студентах в школе им всем может быть присвоен идентификатор студента, чтобы различать их). Суррогатный ключ не имеет внутреннего (внутреннего) значения, но полезен благодаря своей способности однозначно идентифицировать кортеж. Еще одним распространенным явлением, особенно в отношении количества элементов N: M, является составной ключ. Составной ключ - это ключ, состоящий из двух или более атрибутов в таблице, которые (вместе) однозначно идентифицируют запись.[нужна цитата ]
Иностранный ключ
Внешний ключ - это поле в реляционной таблице, которое соответствует столбцу первичного ключа другой таблицы. Он связывает два ключа. Внешние ключи не обязательно должны иметь уникальные значения в ссылочном отношении. Внешний ключ можно использовать для Перекрестная ссылка таблицы, и он эффективно использует значения атрибутов в ссылочном отношении для ограничения области одного или нескольких атрибутов в ссылочном отношении. Эта концепция формально описывается следующим образом: «Для всех кортежей в ссылочном отношении, проецируемом на ссылочные атрибуты, должен существовать кортеж в ссылочном отношении, проецируемый на те же самые атрибуты, так что значения в каждом из ссылочных атрибутов совпадают с соответствующими значениями в указанные атрибуты ".
Хранимые процедуры
Хранимая процедура - это исполняемый код, который связан с базой данных и обычно хранится в ней. Хранимые процедуры обычно собирают и настраивают общие операции, такие как вставка кортеж в связь, сбор статистической информации о шаблонах использования или инкапсуляция сложных бизнес-логика и расчеты. Часто их используют как интерфейс прикладного программирования (API) для безопасности или простоты. Реализации хранимых процедур в СУБД SQL часто позволяют разработчикам использовать преимущества процедурный расширения (часто специфичные для производителя) к стандарту декларативный Синтаксис SQL. Хранимые процедуры не являются частью модели реляционной базы данных, но все коммерческие реализации включают их.
Индекс
Индекс - это один из способов обеспечения более быстрого доступа к данным. Индексы могут быть созданы по любой комбинации атрибутов на связь. Запросы, фильтрующие с помощью этих атрибутов, могут находить совпадающие кортежи напрямую с помощью индекса (аналогично Хеш-таблица lookup) без необходимости проверять каждый кортеж по очереди. Это аналогично использованию указатель книги чтобы перейти непосредственно на страницу, на которой находится искомая информация, так что вам не нужно читать всю книгу, чтобы найти то, что вы ищете. Реляционные базы данных обычно предоставляют несколько методов индексирования, каждый из которых является оптимальным для некоторой комбинации распределения данных, размера отношения и типичного шаблона доступа. Индексы обычно реализуются через B + деревья, R-деревья, и растровые изображения.Индексы обычно не считаются частью базы данных, поскольку они считаются деталью реализации, хотя индексы обычно поддерживаются той же группой, которая обслуживает другие части базы данных. Использование эффективных индексов как для первичных, так и для внешних ключей может значительно повысить производительность запросов. Это связано с тем, что индексы B-дерева приводят к тому, что время запроса пропорционально log (n), где n - количество строк в таблице, а хеш-индексы приводят к запросам с постоянным временем (нет зависимости от размера, если соответствующая часть индекса входит в объем памяти).
Реляционные операции
Запросы к реляционной базе данных и производные relvar в базе данных выражаются в реляционное исчисление или реляционная алгебра. В своей первоначальной реляционной алгебре Кодд ввел восемь реляционных операторов в две группы по четыре оператора в каждой. Первые четыре оператора были основаны на традиционном математическом установить операции:
- В союз оператор объединяет кортежи из двух связи и удаляет все повторяющиеся кортежи из результата. Оператор реляционного объединения эквивалентен оператору СОЕДИНЕНИЕ SQL оператор.
- В пересечение Оператор создает набор кортежей, которые являются общими для двух отношений. Пересечение реализовано в SQL в виде ПЕРЕСЕЧЕНИЕ оператор.
- В разница Оператор воздействует на два отношения и производит набор кортежей из первого отношения, которых нет во втором отношении. Разница реализована в SQL в виде КРОМЕ или оператор МИНУС.
- В декартово произведение двух отношений - это соединение, которое не ограничено никакими критериями, в результате чего каждый кортеж первого отношения сопоставляется с каждым кортежем второго отношения. Декартово произведение реализовано в SQL как Перекрестное соединение оператор.
Остальные операторы, предложенные Коддом, включают специальные операции, характерные для реляционных баз данных:
- Операция выбора или ограничения извлекает кортежи из отношения, ограничивая результаты только теми, которые соответствуют определенному критерию, т.е. подмножество с точки зрения теории множеств. Эквивалент выбора в SQL - это ВЫБРАТЬ оператор запроса с КУДА пункт.
- В проекционная операция извлекает только указанные атрибуты из кортежа или набора кортежей.
- Операция соединения, определенная для реляционных баз данных, часто называется естественным соединением. В этом типе соединения два отношения связаны своими общими атрибутами. MySQL приближение естественного соединения - это Внутреннее соединение оператор. В SQL INNER JOIN предотвращает появление декартова произведения, когда в запросе есть две таблицы. Для каждой таблицы, добавленной в SQL-запрос, добавляется одно дополнительное ВНУТРЕННЕЕ СОЕДИНЕНИЕ, чтобы предотвратить декартово произведение. Таким образом, для N таблиц в запросе SQL должно быть N − 1 INNER JOINS, чтобы предотвратить декартово произведение.
- В родственное деление операция - это немного более сложная операция, которая, по сути, включает использование кортежей одного отношения (делимого) для разделения второго отношения (делителя). Оператор реляционного деления фактически противоположен оператору декартового произведения (отсюда и название).
Другие операторы были введены или предложены после того, как Кодд представил первоначальную восьмерку, включая операторы реляционного сравнения и расширения, которые, среди прочего, предлагают поддержку вложенности и иерархических данных.
Нормализация
Нормализация была впервые предложена Коддом как неотъемлемая часть реляционной модели. Он включает в себя набор процедур, предназначенных для устранения непростых доменов (неатомарных значений) и избыточности (дублирования) данных, что, в свою очередь, предотвращает аномалии манипулирования данными и потерю целостности данных. Наиболее распространенные формы нормализации, применяемые к базам данных, называются нормальные формы.
СУБД

Коннолли и Бегг определяют систему управления базой данных (СУБД) как «систему программного обеспечения, которая позволяет пользователям определять, создавать, поддерживать и контролировать доступ к базе данных».[18] RDBMS - это расширение этого акронима, которое иногда используется, когда базовая база данных является реляционной.
Альтернативное определение для система управления реляционной базой данных система управления базами данных (СУБД) на основе реляционная модель. Большинство широко используемых сегодня баз данных основано на этой модели.[19]
РСУБД были распространенным вариантом для хранения информации в базах данных, используемых для финансовых отчетов, производственной и логистической информации, данных о персонале и других приложений с 1980-х годов. Реляционные базы данных часто заменяют устаревшие иерархические базы данных и сетевые базы данных, потому что СУБД было проще внедрять и администрировать. Тем не менее, реляционные базы данных постоянно сталкивались с неудачными попытками база данных объектов системы управления в 1980-х и 1990-х годах (которые были введены в попытке решить так называемые объектно-относительное рассогласование импеданса между реляционными базами данных и объектно-ориентированными прикладными программами), а также База данных XML системы управления в 1990-е гг.[нужна цитата ] Однако из-за обилия технологий, таких как горизонтальное масштабирование из компьютерные кластеры, NoSQL базы данных в последнее время стали популярными как альтернатива базам данных СУБД.[20]
Распределенные реляционные базы данных
Распределенная архитектура реляционной базы данных (DRDA) был разработан рабочей группой IBM в период с 1988 по 1994 год. DRDA позволяет реляционным базам данных, подключенным к сети, взаимодействовать друг с другом для выполнения запросов SQL.[21][22]Сообщения, протоколы и структурные компоненты DRDA определяются Распределенная архитектура управления данными.
В соответствии с DB-двигатели, в сентябре 2020 года наиболее широко используемыми системами были (ранжированы в следующем порядке):
- Oracle,
- MySQL (бесплатно программное обеспечение ),
- Microsoft SQL Server,
- PostgreSQL (Open Source, продолжение разработки INGRES),
- IBM DB2,
- SQLite (бесплатно программное обеспечение),
- Microsoft Access,
- и MariaDB (бесплатно программное обеспечение),
- Терадата,
- и Apache Hive (бесплатное программное обеспечение; специализировано для хранилища данных ).[23]
По данным исследовательской компании Gartner, в 2011 году пятерка ведущих проприетарное программное обеспечение поставщиков реляционных баз данных по выручке Oracle (48.8%), IBM (20.2%), Microsoft (17.0%), SAP включая Sybase (4,6%), и Терадата (3.7%).[24]
Смотрите также
- SQL
- База данных объектов (OODBMS)
- Онлайн-аналитическая обработка (OLAP) и ROLAP (Реляционная онлайн-аналитическая обработка)
- Хранилище данных
- Схема звездочки
- Схема снежинки
- Список систем управления реляционными базами данных
- Сравнение систем управления реляционными базами данных
Рекомендации
- ^ а б Кодд, Э.Ф. (1970). «Реляционная модель данных для больших общих банков данных». Коммуникации ACM. 13 (6): 377–387. Дои:10.1145/362384.362685.
- ^ Эмблер, Скотт. «Реляционные базы данных 101: взгляд на картину в целом».[нужен лучший источник ]
- ^ «Реляционная модель данных для больших общих банков данных» (PDF).
- ^ Свидание, Крис. База данных в деталях: теория отношений для практиков. О'Рейли. ISBN 0-596-10012-4.
- ^ Финансирование революции: государственная поддержка компьютерных исследований. Национальная академия прессы. 8 января 1999 г. ISBN 0309062780.
- ^ Sumathi, S .; Эсаккираджан, С. (13 февраля 2008 г.). Основы систем управления реляционными базами данных. Springer. ISBN 3540483977.
Продукт назывался SQL / DS (язык структурированных запросов / хранилище данных) и работал в среде операционной системы DOS / VSE.
- ^ «Хронология Oracle» (PDF). Журнал Профит. Oracle. 12 (2): 26 мая 2007 г.. Получено 2013-05-16.
- ^ «Новая программа для баз данных выводит Macintosh в высшую лигу». трибунацифровой чикаго трибуна. Получено 2016-03-17.
- ^ SIGFIDET '74 Материалы семинара 1974 г. ACM SIGFIDET (ныне SIGMOD) по описанию, доступу и управлению данными
- ^ Рамакришнан, Рагху; Донжеркович, Донко; Ранганатан, Арвинд; Бейер, Кевин С .; Кришнапрасад, Муралидхар (1998). «SRQL: язык сортированных реляционных запросов» (PDF). e Труды SSDBM.
- ^ «Обзор реляционной базы данных». oracle.com.
- ^ «Универсальная модель отношений для вложенной базы данных», Модель вложенной универсальной реляционной базы данных, Берлин, Гейдельберг: Springer Berlin Heidelberg, стр. 109–135, 1992, ISBN 978-3-540-55493-6, получено 2020-11-01
- ^ «Этой весной Грей будет удостоен премии А. М. Тьюринга». Microsoft PressPass. 1998-11-23. В архиве из оригинала от 6 февраля 2009 г.. Получено 2009-01-16.
- ^ Грей, Джим (Сентябрь 1981 г.). «Концепция сделки: достоинства и ограничения» (PDF). Труды 7-й Международной конференции по очень большим базам данных. Купертино, Калифорния: Тандемные компьютеры. стр. 144–154. Получено 2006-11-09.
- ^ Грей, Джим, и Рейтер, Андреас, Распределенная обработка транзакций: концепции и методы. Морган Кауфманн, 1993. ISBN 1-55860-190-2.
- ^ Визе, Лена (2015). Расширенное управление данными: для SQL, noSQL, облачных и распределенных баз данных. Walter de Gruyter GmbH & Co KG. п. 192.
- ^ Дата (1984), п. 268.
- ^ Коннолли, Томас М .; Бегг, Кэролайн Э. (2014). Системы баз данных - практический подход к реализации проекта и управлению (6-е изд.). Пирсон. п. 64. ISBN 978-1292061184.
- ^ Пратт, Филип Дж .; Наконец, Мэри З. (2014-09-08). Концепции управления базами данных (8-е изд.). Курсовая технология. п. 29. ISBN 9781285427102.
- ^ «Базы данных NoSQL съедают рынок реляционных баз данных». Получено 2018-03-14.
- ^ Райнш Р. (1988). «Распределенная база данных для SAA». Журнал IBM Systems. 27 (3): 362–389. Дои:10.1147 / sj.273.0362.
- ^ Справочник по архитектуре распределенной реляционной базы данных. IBM Corp. SC26-4651-0. 1990 г.
- ^ «Рейтинг реляционных СУБД DB-Engines». Получено 2020-09-11.
- ^ «Oracle - явный лидер на рынке СУБД с оборотом $ 24 млрд». 2012-04-12. Получено 2013-03-01.
- Дата, К. Дж. (1984). Руководство по DB2 (под ред. студента). Эддисон-Уэсли. ISBN 0201113171. OCLC 256383726. ПР 2838595M.
| Типы | |
|---|---|
| Концепции | |
| Объекты | |
| Составные части | |
| Функции | |
| похожие темы | |
| |