Большое количество данных - Big data - Wikipedia
Эта статья может содержать чрезмерное количество цитирований. (Ноябрь 2019) (Узнайте, как и когда удалить этот шаблон сообщения) |

Большое количество данных это область, которая рассматривает способы анализа, систематического извлечения информации из или иного решения наборы данных слишком большие или сложные, чтобы их можно было решить с помощью традиционных обработка данных программное обеспечение. Данные с большим количеством наблюдений (строк) предлагают больше статистическая мощность, в то время как данные с более высокой сложностью (больше атрибутов или столбцов) могут привести к более высокому коэффициент ложного обнаружения.[2] Проблемы с большими данными включают сбор данных, хранилище данных, анализ данных, поиск, обмен, передача, визуализация, запрос, обновление, конфиденциальность информации и источник данных. Первоначально большие данные были связаны с тремя ключевыми понятиями: объем, разнообразие, и скорость. Когда мы обрабатываем большие данные, мы можем не брать выборку, а просто наблюдать и отслеживать, что происходит. Поэтому большие данные часто включают данные, размеры которых превышают возможности традиционного программного обеспечения для обработки в приемлемое время и ценить.
Текущее использование термина большое количество данных имеет тенденцию относиться к использованию прогнозная аналитика, аналитика поведения пользователей или некоторые другие методы расширенного анализа данных, которые извлекают ценить от данных, и редко до определенного размера набора данных. «Нет никаких сомнений в том, что объем доступных сейчас данных действительно велик, но это не самая важная характеристика этой новой экосистемы данных».[3]Анализ наборов данных может найти новые корреляции для «выявления тенденций в бизнесе, предотвращения болезней, борьбы с преступностью и так далее».[4] Ученые, руководители предприятий, практикующие врачи, реклама и правительства одинаково регулярно сталкиваются с трудностями с большими наборами данных в областях, включая Поиск в Интернете, финтех, городская информатика и бизнес-информатика. Ученые сталкиваются с ограничениями в электронная наука работа, в том числе метеорология, геномика,[5] коннектомика, комплексное физическое моделирование, биология и исследования окружающей среды.[6]
Наборы данных быстро растут, в определенной степени потому, что они все чаще собираются дешевыми и многочисленными методами сбора информации. Интернет вещей такие устройства, как мобильные устройства, антенна (дистанционное зондирование ), журналы программного обеспечения, камеры, микрофоны, определение радиочастоты (RFID) считыватели и беспроводные сенсорные сети.[7][8] Технологические возможности хранения информации на душу населения в мире примерно удваивались каждые 40 месяцев с 1980-х годов;[9] по состоянию на 2012 год[Обновить], ежедневно 2,5 эксабайты (2.5×260 байтов) данных.[10] На основании IDC прогнозировалось, что глобальный объем данных будет экспоненциально расти с 4,4 зеттабайты до 44 зеттабайт в период с 2013 по 2020 год. По прогнозам IDC, к 2025 году объем данных будет составлять 163 зеттабайта.[11] Один из вопросов для крупных предприятий - определить, кто должен владеть инициативами в области больших данных, которые влияют на всю организацию.[12]
Системы управления реляционными базами данных, рабочий стол статистика[требуется разъяснение ] а программные пакеты, используемые для визуализации данных, часто испытывают трудности с обработкой больших данных. Для работы может потребоваться «массово параллельное программное обеспечение, работающее на десятках, сотнях или даже тысячах серверов».[13] То, что квалифицируется как «большие данные», зависит от возможностей пользователей и их инструментов, а расширение возможностей делает большие данные постоянно меняющейся целью. "Некоторые организации сталкиваются с сотнями гигабайты данных впервые может вызвать необходимость пересмотреть варианты управления данными. Для других могут потребоваться десятки или сотни терабайт, прежде чем размер данных станет существенным фактором ".[14]
Определение
Этот термин используется с 1990-х годов, при этом некоторые считают, что Джон Маши для популяризации термина.[15][16]Большие данные обычно включают в себя наборы данных, размеры которых превышают возможности широко используемых программных инструментов. захватывать, священник, управлять и обрабатывать данные в течение приемлемого времени.[17] Философия больших данных охватывает неструктурированные, полуструктурированные и структурированные данные, однако основное внимание уделяется неструктурированным данным.[18] «Размер» больших данных - постоянно меняющаяся цель, по состоянию на 2012 г.[Обновить] от нескольких десятков терабайт до многих зеттабайты данных.[19]Большие данные требуют набора техник и технологий с новыми формами интеграция чтобы раскрыть идеи из наборы данных разнообразны, сложны и масштабны.[20]
«Разнообразие», «правдивость» и другие различные «V» добавляются некоторыми организациями для его описания, и это пересмотр оспаривается некоторыми отраслевыми властями.[21]
Определение 2018 года гласит: «Большие данные - это то, где необходимы инструменты параллельных вычислений для обработки данных», и отмечает: «Это представляет собой отчетливое и четко определенное изменение в используемой компьютерной науке с помощью теорий параллельного программирования и потери некоторых гарантий и возможностей. сделан Реляционная модель Кодда."[22]
Растущая зрелость концепции более четко определяет разницу между "большими данными" и "Бизнес-аналитика ":[23]
- Business Intelligence использует инструменты прикладной математики и описательная статистика с данными с высокой плотностью информации для измерения вещей, выявления тенденций и т. д.
- Большие данные используют математический анализ, оптимизацию, индуктивная статистика и концепции из идентификация нелинейных систем[24] выводить законы (регрессии, нелинейные отношения и причинно-следственные связи) из больших наборов данных с низкой плотностью информации[25] для выявления отношений и зависимостей или для прогнозирования результатов и поведения.[24][26][рекламный источник? ]
Характеристики
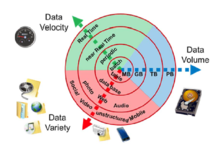
Большие данные можно описать следующими характеристиками:
- Объем
- Количество сгенерированных и сохраненных данных. Размер данных определяет ценность и потенциальное понимание, а также то, можно ли их считать большими данными или нет. Размер больших данных обычно превышает терабайты и петабайты.[27]
- Разнообразие
- Тип и характер данных. Ранние технологии, такие как СУБД, были способны эффективно и действенно обрабатывать структурированные данные. Однако изменение типа и характера от структурированного к полуструктурированному или неструктурированному поставило под вопрос существующие инструменты и технологии. Технологии больших данных развивались с основной целью собирать, хранить и обрабатывать полуструктурированные и неструктурированные (разнообразные) данные, генерируемые с высокой скоростью (скорость) и огромными по размеру (объему). Позже эти инструменты и технологии были исследованы и использованы для обработки структурированных данных, но предпочтительнее для хранения. В конце концов, обработка структурированных данных по-прежнему оставалась необязательной, либо с использованием больших данных, либо с использованием традиционных СУБД. Это помогает в анализе данных с целью эффективного использования скрытых идей, полученных из данных, собранных через социальные сети, файлы журналов, датчики и т. Д. Большие данные извлекаются из текста, изображений, аудио, видео; плюс он восполняет недостающие части через слияние данных.
- Скорость
- Скорость, с которой данные генерируются и обрабатываются, чтобы соответствовать требованиям и задачам, стоящим на пути роста и развития. Большие данные часто доступны в режиме реального времени. В сравнении с небольшие данные, большие данные производятся постоянно. Два типа скорости, связанные с большими данными, - это частота генерации и частота обработки, записи и публикации.[28]
- Достоверность
- Это расширенное определение больших данных, которое относится к качеству данных и их ценности.[29] В Качество данных Количество собранных данных может сильно различаться, что влияет на точность анализа.[30]
Другими важными характеристиками больших данных являются:[31]
- Исчерпывающий
- Была ли вся система (т.е. = все) захвачено или записано или нет.

- Мелкозернистый и уникально лексический
- Соответственно, доля конкретных данных каждого элемента в каждом собранном элементе и правильность индексации или идентификации элемента и его характеристик.
- Реляционный
- Если собранные данные содержат общие поля, которые позволят объединить или метаанализ различных наборов данных.
- Экстенсиональный
- Если новые поля в каждом элементе собранных данных можно легко добавить или изменить.
- Масштабируемость
- Если размер данных может быстро увеличиваться.
- Ценить
- Утилита, которую можно извлечь из данных.
- Изменчивость
- Это относится к данным, значение или другие характеристики которых меняются в зависимости от контекста, в котором они создаются.
Архитектура
Репозитории больших данных существовали во многих формах, часто создаваемые корпорациями с особыми потребностями. Коммерческие поставщики исторически предлагали параллельные системы управления базами данных для больших данных, начиная с 1990-х годов. За много лет WinterCorp опубликовала самый крупный отчет по базе данных.[32][рекламный источник? ]
Терадата Корпорация в 1984 г. начала продавать параллельную обработку DBC 1012 система. Системы Teradata были первыми, кто в 1992 году сохранил и проанализировал 1 терабайт данных. В 1991 году объем жестких дисков составлял 2,5 ГБ, поэтому определение больших данных постоянно развивается в соответствии с Закон Крайдера. Компания Teradata установила первую систему на основе РСУБД петабайтного класса в 2007 году. По состоянию на 2017 год.[Обновить], установлено несколько десятков реляционных баз данных Teradata петабайтного класса, самая большая из которых превышает 50 ПБ. До 2008 года системы были на 100% структурированными реляционными данными. С тех пор Teradata добавила неструктурированные типы данных, включая XML, JSON, и Avro.
В 2000 году Seisint Inc. (ныне Решения рисков LexisNexis ) разработал C ++ распределенная платформа для обработки данных и запросов, известная как Системы HPCC Платформа. Эта система автоматически разделяет, распределяет, хранит и доставляет структурированные, полуструктурированные и неструктурированные данные на несколько стандартных серверов. Пользователи могут писать конвейеры обработки данных и запросы на декларативном языке программирования потоков данных, называемом ECL. Аналитики данных, работающие в ECL, не обязаны заранее определять схемы данных и могут скорее сосредоточиться на конкретной проблеме, изменяя данные наилучшим образом по мере разработки решения. В 2004 году LexisNexis приобрела Seisint Inc.[33] и их платформу высокоскоростной параллельной обработки и успешно использовали эту платформу для интеграции систем данных Choicepoint Inc., когда они приобрели эту компанию в 2008 году.[34] В 2011 году системная платформа HPCC была открыта по лицензии Apache v2.0.
ЦЕРН и другие физические эксперименты собирали большие наборы данных за многие десятилетия, обычно анализируемые с помощью высокопроизводительные вычисления а не архитектур с уменьшением карты, обычно подразумеваемой нынешним движением «больших данных».
В 2004 г. Google опубликовал статью о процессе под названием Уменьшение карты который использует аналогичную архитектуру. Концепция MapReduce предоставляет модель параллельной обработки, и была выпущена соответствующая реализация для обработки огромных объемов данных. С помощью MapReduce запросы разделяются и распределяются по параллельным узлам и обрабатываются параллельно (этап Map). Затем результаты собираются и доставляются (этап уменьшения). Фреймворк оказался очень удачным,[35] поэтому другие хотели воспроизвести алгоритм. Следовательно, выполнение платформы MapReduce был принят проектом с открытым исходным кодом Apache под названием Hadoop.[36] Apache Spark был разработан в 2012 году в ответ на ограничения парадигмы MapReduce, поскольку он добавляет возможность настраивать множество операций (а не только сопоставление с последующим сокращением).
MIKE2.0 - это открытый подход к управлению информацией, который признает необходимость внесения изменений в связи с последствиями для больших данных, указанными в статье под названием «Предложение решений для больших данных».[37] Методология рассматривает обработку больших данных с точки зрения полезной перестановки источников данных, сложность во взаимоотношениях и трудности с удалением (или изменением) отдельных записей.[38]
Исследования 2012 года показали, что многоуровневая архитектура - это один из вариантов решения проблем, связанных с большими данными. А распределенный параллельный архитектура распределяет данные по множеству серверов; Эти среды параллельного выполнения могут значительно повысить скорость обработки данных. Этот тип архитектуры вставляет данные в параллельную СУБД, в которой реализовано использование фреймворков MapReduce и Hadoop. Этот тип инфраструктуры стремится сделать вычислительную мощность прозрачной для конечного пользователя за счет использования внешнего сервера приложений.[39]
В озеро данных позволяет организации сместить фокус с централизованного управления на общую модель, чтобы реагировать на меняющуюся динамику управления информацией. Это позволяет быстро разделить данные в озеро данных, тем самым сокращая накладные расходы.[40][41]
Технологии
2011 год Глобальный институт McKinsey Отчет характеризует основные компоненты и экосистему больших данных следующим образом:[42]
- Методы анализа данных, такие как A / B тестирование, машинное обучение и обработка естественного языка
- Технологии больших данных, например бизнес-аналитика, облачные вычисления и базы данных
- Визуализация, например диаграммы, графики и другие виды отображения данных
Многомерные большие данные также могут быть представлены как OLAP кубы данных или, математически, тензоры. Системы баз данных с массивами решили предоставить хранилище и поддержку запросов высокого уровня для этого типа данных. Дополнительные технологии, применяемые к большим данным, включают эффективные вычисления на основе тензоров,[43] Такие как полилинейное подпространственное обучение.,[44] массовая параллельная обработка (MPP ) базы данных, поисковые приложения, сбор данных,[45] распределенные файловые системы, распределенный кеш (например, пакетный буфер и Memcached ), распределенные базы данных, облако и На основе HPC инфраструктура (приложения, хранилища и вычислительные ресурсы)[46] и Интернет.[нужна цитата ] Несмотря на то, что было разработано много подходов и технологий, по-прежнему сложно проводить машинное обучение с большими данными.[47]
Немного MPP реляционные базы данных могут хранить петабайты данных и управлять ими. Подразумевается возможность загружать, отслеживать, создавать резервные копии и оптимизировать использование больших таблиц данных в СУБД.[48][рекламный источник? ]
DARPA с Топологический анализ данных Программа ищет фундаментальную структуру массивных наборов данных, и в 2008 году технология стала публичной с запуском компании под названием Аясди.[49][требуется сторонний источник ]
Практики процессов аналитики больших данных обычно враждебно относятся к более медленному общему хранилищу,[50] предпочитая хранилище с прямым подключением (DAS ) в различных формах с твердотельного накопителя (SSD ) на большую мощность SATA диск похоронен внутри узлов параллельной обработки. Восприятие архитектур совместно используемых хранилищ—Сеть хранения данных (SAN) и Network Attached Storage (NAS) - они относительно медленные, сложные и дорогие. Эти качества несовместимы с системами анализа больших данных, которые процветают за счет производительности системы, стандартной инфраструктуры и низкой стоимости.
Доставка информации в реальном времени или почти в реальном времени - одна из определяющих характеристик аналитики больших данных. Таким образом, по возможности избегают задержек. Данные в памяти с прямым подключением или на диске в порядке - данные в памяти или на диске на другом конце FC SAN подключение нет. Стоимость SAN в масштабе, необходимом для приложений аналитики, намного выше, чем у других методов хранения.
У общего хранилища есть как преимущества, так и недостатки в аналитике больших данных, но специалисты по аналитике больших данных по состоянию на 2011 г.[Обновить] не одобрял это.[51][рекламный источник? ]
Приложения

Большие данные настолько увеличили потребность в специалистах по управлению информацией, что Software AG, Корпорация Oracle, IBM, Microsoft, SAP, ЭМС, HP и Dell потратили более 15 миллиардов долларов на софтверные компании, специализирующиеся на управлении данными и аналитике. В 2010 году эта отрасль стоила более 100 миллиардов долларов и росла почти на 10 процентов в год: примерно в два раза быстрее, чем бизнес программного обеспечения в целом.[4]
Развитые страны все чаще используют технологии, требующие обработки больших объемов данных. В мире насчитывается 4,6 миллиарда абонентов мобильных телефонов, и от 1 до 2 миллиардов человек имеют доступ к Интернету.[4] Между 1990 и 2005 годами более 1 миллиарда человек во всем мире вошли в средний класс, что означает, что больше людей стали более грамотными, что, в свою очередь, привело к росту информации. Эффективная способность мира по обмену информацией через телекоммуникационные сети составляет 281 петабайты в 1986 г. - 471 петабайты в 1993 г. - 2,2 эксабайта в 2000 г. - 65 эксабайты в 2007[9] Согласно прогнозам, к 2014 году объем интернет-трафика составит 667 эксабайт в год.[4] Согласно одной оценке, одна треть глобально хранимой информации находится в форме буквенно-цифрового текста и данных неподвижных изображений,[52] который является наиболее полезным для большинства приложений с большими данными. Это также показывает потенциал еще неиспользованных данных (то есть в форме видео- и аудиоконтента).
Хотя многие поставщики предлагают готовые решения для больших данных, эксперты рекомендуют разрабатывать собственные решения, специально адаптированные для решения текущей проблемы компании, если компания обладает достаточными техническими возможностями.[53]
Правительство
Использование и принятие больших данных в государственных процессах позволяет повысить эффективность с точки зрения затрат, производительности и инноваций.[54] но не без недостатков. Анализ данных часто требует, чтобы несколько частей правительства (центрального и местного) работали в сотрудничестве и создавали новые инновационные процессы для достижения желаемого результата.
CRVS (регистрация актов гражданского состояния и естественного движения населения ) собирает все свидетельства о статусе от рождения до смерти. CRVS - это источник больших данных для правительств.
Международная разработка
Исследования по эффективному использованию информационных и коммуникационных технологий в целях развития (также известные как ICT4D) показывают, что технологии больших данных могут внести важный вклад, но также создают уникальные проблемы для Международная разработка.[55][56] Достижения в области анализа больших данных открывают рентабельные возможности для улучшения принятия решений в важнейших областях развития, таких как здравоохранение, занятость, экономическая производительность, преступность, безопасность и природная катастрофа и управление ресурсами.[57][58][59] Кроме того, данные, создаваемые пользователями, открывают новые возможности для передачи голоса неслышимому.[60] Однако давние проблемы для развивающихся регионов, такие как неадекватная технологическая инфраструктура и нехватка экономических и человеческих ресурсов, усугубляют существующие проблемы с большими данными, такие как конфиденциальность, несовершенная методология и проблемы взаимодействия.[57]
Здравоохранение
Аналитика больших данных помогла улучшить здравоохранение, предоставляя персонализированную медицину и предписывающую аналитику, вмешательство в клинические риски и прогнозную аналитику, сокращение потерь и вариативности медицинской помощи, автоматизированную внешнюю и внутреннюю отчетность по данным пациентов, стандартизированные медицинские термины и реестры пациентов, а также фрагментированные точечные решения.[61][62][63][64] Некоторые области улучшений более желательны, чем реализованы на самом деле. Уровень данных, генерируемых в системы здравоохранения нетривиально. С появлением мобильного здравоохранения, электронного здравоохранения и носимых технологий объем данных будет продолжать расти. Это включает в себя электронная медицинская карта данные, данные изображений, данные пациентов, данные датчиков и другие формы трудно обрабатываемых данных. В настоящее время существует еще большая потребность в таких средах, чтобы уделять больше внимания качеству данных и информации.[65] «Большие данные очень часто означают»грязные данные 'и доля неточностей в данных увеличивается с ростом объема данных. "Человеческий контроль в масштабе больших данных невозможен, и службы здравоохранения остро нуждаются в интеллектуальных инструментах для контроля точности и достоверности, а также обработки пропущенной информации.[66] Хотя обширная информация в сфере здравоохранения теперь представлена в электронном виде, она подходит под зонтик больших данных, поскольку большая часть информации неструктурирована и трудна в использовании.[67] Использование больших данных в здравоохранении вызвало серьезные этические проблемы, начиная от рисков для прав личности, конфиденциальности и автономия, к прозрачности и доверию.[68]
Большие данные в исследованиях в области здравоохранения особенно перспективны с точки зрения исследовательских биомедицинских исследований, поскольку анализ на основе данных может продвигаться вперед быстрее, чем исследования, основанные на гипотезах.[69] Затем тенденции, наблюдаемые при анализе данных, можно проверить в традиционных последующих биологических исследованиях, основанных на гипотезах, и, в конечном итоге, в клинических исследованиях.
Связанная подобласть приложений, которая в значительной степени полагается на большие данные в области здравоохранения, - это область компьютерная диагностика в медицине.[70] Достаточно вспомнить, что, например, для эпилепсия мониторинг принято создавать от 5 до 10 ГБ данных ежедневно. [71] Точно так же одно несжатое изображение груди томосинтез в среднем 450 МБ данных. [72]Это лишь некоторые из множества примеров, когда компьютерная диагностика использует большие данные. По этой причине большие данные были признаны одной из семи ключевых проблем, которые компьютерная диагностика системы необходимо преодолеть, чтобы достичь следующего уровня производительности. [73]
Образование
А Глобальный институт McKinsey исследование выявило нехватку 1,5 млн высококвалифицированных специалистов и менеджеров по обработке данных[42] и ряд университетов[74][нужен лучший источник ] включая Университет Теннесси и Калифорнийский университет в Беркли, создали магистерские программы для удовлетворения этого спроса. Частные учебные лагеря также разработали программы для удовлетворения этого спроса, включая бесплатные программы, такие как Инкубатор данных или платные программы, такие как Генеральная Ассамблея.[75] В конкретной области маркетинга одна из проблем, подчеркнутая Веделем и Каннаном.[76] состоит в том, что у маркетинга есть несколько поддоменов (например, реклама, продвижение, разработка продуктов, брендинг), которые используют разные типы данных. Поскольку универсальные аналитические решения нежелательны, бизнес-школы должны готовить менеджеров по маркетингу к тому, чтобы они обладали обширными знаниями обо всех различных методах, используемых в этих поддоменах, чтобы получить общую картину и эффективно работать с аналитиками.
Средства массовой информации
Чтобы понять, как СМИ используют большие данные, сначала необходимо предоставить некоторый контекст в механизме, используемом для медиа-процесса. Ник Кулдри и Джозеф Туроу предположили, что практикующие в СМИ и рекламе рассматривают большие данные как множество действенных точек информации о миллионах людей. Похоже, что отрасль отходит от традиционного подхода к использованию конкретных средств массовой информации, таких как газеты, журналы или телешоу, и вместо этого обращается к потребителям с помощью технологий, которые достигают целевой аудитории в оптимальное время в оптимальных местах. Конечная цель состоит в том, чтобы служить или передать сообщение или контент, который (с точки зрения статистики) соответствует мышлению потребителя. Например, издательская среда все чаще адаптирует сообщения (рекламные объявления) и контент (статьи) для обращения к потребителям, которые были получены исключительно с помощью различных сбор данных виды деятельности.[77]
- Таргетинг на потребителей (для рекламы маркетологов)[78]
- Сбор данных
- Журналистика данных: издатели и журналисты используют инструменты больших данных, чтобы предоставлять уникальные и инновационные идеи и инфографика.
Канал 4, британский Государственная служба телевещательная компания, является лидером в области больших данных и анализ данных.[79]
Страхование
Поставщики медицинского страхования собирают данные о социальных «детерминантах здоровья», таких как продукты питания и Потребление ТВ, семейное положение, размер одежды и покупательские привычки, на основании которых они делают прогнозы относительно затрат на здоровье, чтобы выявлять проблемы со здоровьем у своих клиентов. Спорный вопрос, используются ли эти прогнозы в настоящее время для ценообразования.[80]
Интернет вещей (IoT)
Большие данные и Интернет вещей работают вместе. Данные, извлеченные из устройств IoT, обеспечивают отображение взаимосвязи устройств. Такие сопоставления использовались медиаиндустрией, компаниями и правительствами для более точного нацеливания на свою аудиторию и повышения эффективности СМИ. Интернет вещей также все чаще используется как средство сбора сенсорных данных, и эти сенсорные данные используются в медицине,[81] производство[82] и транспорт[83] контексты.
Кевин Эштон, эксперт в области цифровых инноваций, которому приписывают создание этого термина,[84] определяет Интернет вещей в этой цитате: «Если бы у нас были компьютеры, которые знали все, что нужно знать о вещах - используя данные, которые они собирали без какой-либо нашей помощи, - мы могли бы отслеживать и подсчитывать все и значительно сокращать потери, потери , и стоимость. Мы бы знали, когда что-то нужно было заменить, отремонтировать или отозвать, и были ли они свежими или устаревшими ».
Информационные технологии
Особенно с 2015 года большие данные стали популярными в деловые операции как инструмент, помогающий сотрудникам работать более эффективно и оптимизировать сбор и распространение информационные технологии (ЭТО). Использование больших данных для решения проблем ИТ и сбора данных на предприятии называется Аналитика ИТ-операций (ITOA).[85] Применяя принципы больших данных к концепциям машинный интеллект и глубокие вычисления, ИТ-отделы могут прогнозировать потенциальные проблемы и предлагать решения еще до того, как они возникнут.[85] В это время предприятия ITOA также начали играть важную роль в управление системами предлагая платформы, которые помогли разрозненные хранилища данных вместе и генерировали понимание всей системы, а не отдельных участков данных.
Тематические исследования
Правительство
Китай
- Платформа интегрированных совместных операций (IJOP, 一体化 联合 作战 平台) используется правительством для мониторинга населения, в частности Уйгуры.[86] Биометрия, включая образцы ДНК, собираются с помощью программы бесплатных медицинских осмотров.[87]
- К 2020 году Китай планирует присвоить всем своим гражданам личную оценку «Социальный кредит», основанную на их поведении.[88] В Система социального кредита, теперь пилотируемый в ряде китайских городов, считается формой масса наблюдения который использует технологию анализа больших данных.[89][90]
Индия
- Анализ больших данных был опробован на BJP победить на всеобщих выборах в Индии в 2014 году.[91]
- В Индийское правительство использует многочисленные методы, чтобы выяснить, как индийский электорат реагирует на действия правительства, а также идеи для усиления политики.
Израиль
- С помощью решения GlucoMe для работы с большими данными можно создать индивидуальные методы лечения диабета.[92]
объединенное Королевство
Примеры использования больших данных в государственных услугах:
- Данные о лекарствах, отпускаемых по рецепту: связав происхождение, местонахождение и время выписки каждого рецепта, исследовательское подразделение смогло продемонстрировать значительную задержку между выпуском любого конкретного лекарства и адаптацией стандарта в масштабах всей Великобритании. Национальный институт здравоохранения и передового опыта руководящие указания. Это говорит о том, что новым или самым современным лекарствам требуется некоторое время, чтобы проникнуть к пациенту в целом.[93]
- Объединение данных: местный орган власти смешанные данные об услугах, таких как ротация дорожного покрытия, с услугами для людей из группы риска, например, «еда на колесах». Подключение данных позволило местным властям избежать любых задержек, связанных с погодными условиями.[94]
Соединенные Штаты Америки
- В 2012 г. Администрация Обамы объявила об Инициативе по исследованиям и развитию больших данных, чтобы изучить, как большие данные могут быть использованы для решения важных проблем, с которыми сталкивается правительство.[95] Инициатива состоит из 84 различных программ больших данных, распределенных по шести департаментам.[96]
- Анализ больших данных сыграл большую роль в Барак Обама успешный Избирательная кампания 2012 г..[97]
- В Федеральное правительство США владеет пятью из десяти самых могущественных суперкомпьютеры в мире.[98][99]
- В Дата-центр Юты был построен в Соединенных Штатах Национальное Агенство Безопасности. По завершении объект сможет обрабатывать большой объем информации, собранной АНБ через Интернет. Точный объем дискового пространства неизвестен, но более свежие источники утверждают, что его будет порядка нескольких эксабайты.[100][101][102] Это вызвало проблемы с безопасностью в отношении анонимности собранных данных.[103]
Розничная торговля
- Walmart обрабатывает более 1 миллиона клиентских транзакций каждый час, которые импортируются в базы данных, которые, по оценкам, содержат более 2,5 петабайт (2560 терабайт) данных, что в 167 раз больше информации, содержащейся во всех книгах в США. Библиотека Конгресса.[4]
- Недвижимость в Уиндермире использует информацию о местоположении от почти 100 миллионов водителей, чтобы помочь покупателям нового жилья определить типичное время в пути на работу и с работы в разное время дня.[104]
- Система обнаружения карт FICO защищает счета по всему миру.[105]
Наука
- В Большой адронный коллайдер эксперименты представляют собой около 150 миллионов датчиков, передающих данные 40 миллионов раз в секунду. В секунду происходит около 600 миллионов столкновений. После фильтрации и отказа от записи более 99,99995%[106] из этих потоков происходит 1000 интересных столкновений в секунду.[107][108][109]
- В результате, работая только с менее чем 0,001% данных потока сенсора, поток данных из всех четырех экспериментов LHC составляет 25 петабайт в год до репликации (по состоянию на 2012 г.[Обновить]). После репликации это становится почти 200 петабайт.
- Если бы все данные датчиков были записаны на LHC, с потоком данных было бы чрезвычайно сложно работать. Поток данных превысит 150 миллионов петабайт в год, или почти 500. эксабайты в сутки до репликации. Чтобы представить число в перспективе, это эквивалентно 500 квинтиллион (5×1020) байт в день, что почти в 200 раз больше, чем у всех других источников, вместе взятых в мире.
- В Массив квадратных километров это радиотелескоп, состоящий из тысяч антенн. Ожидается, что он будет введен в эксплуатацию к 2024 году. Ожидается, что в совокупности эти антенны будут собирать 14 эксабайт и хранить один петабайт в день.[110][111] Он считается одним из самых амбициозных научных проектов, когда-либо предпринимавшихся.[112]
- Когда Sloan Digital Sky Survey (SDSS) начал собирать астрономические данные в 2000 году, за первые несколько недель он собрал больше, чем все данные, собранные в истории астрономии ранее. Продолжая работать со скоростью около 200 ГБ за ночь, SDSS накопил более 140 терабайт информации.[4] Когда Большой синоптический обзорный телескоп, преемник SDSS, появится в сети в 2020 году, разработчики ожидают, что он будет получать такой объем данных каждые пять дней.[4]
- Расшифровка генома человека изначально на обработку ушло 10 лет; теперь это можно сделать менее чем за день. Секвенаторы ДНК разделили стоимость секвенирования на 10000 за последние десять лет, что в 100 раз дешевле, чем снижение стоимости, предсказанное Закон Мура.[113]
- В НАСА Центр климатического моделирования (NCCS) хранит 32 петабайта данных климатических наблюдений и моделирования в кластере суперкомпьютеров Discover.[114][115]
- DNAStack Google собирает и упорядочивает образцы ДНК генетических данных со всего мира для выявления заболеваний и других медицинских дефектов. Эти быстрые и точные расчеты исключают любые «точки трения» или человеческие ошибки, которые мог сделать один из многочисленных экспертов в области науки и биологии, работающих с ДНК. DNAStack, часть Google Genomics, позволяет ученым использовать обширную выборку ресурсов с поискового сервера Google для мгновенного масштабирования социальных экспериментов, которые обычно занимают годы.[116][117]
- 23andme с База данных ДНК содержит генетическую информацию о более чем 1 000 000 человек по всему миру.[118] Компания изучает возможность продажи «анонимных агрегированных генетических данных» другим исследователям и фармацевтическим компаниям в исследовательских целях, если пациенты дадут свое согласие.[119][120][121][122][123] Ахмад Харири, профессор психологии и нейробиологии в Университет Дьюка который использует 23andMe в своих исследованиях с 2009 года, заявляет, что наиболее важным аспектом новой услуги компании является то, что она делает генетические исследования доступными и относительно дешевыми для ученых.[119] Исследование, которое выявило 15 сайтов генома, связанных с депрессией, в базе данных 23andMe, привело к резкому увеличению запросов на доступ к репозиторию, поскольку 23andMe отправил почти 20 запросов на доступ к данным о депрессии в течение двух недель после публикации статьи.[124]
- Вычислительная гидродинамика (CFD ) и гидродинамический турбулентность исследования генерируют массивные наборы данных. Базы данных о турбулентности Джонса Хопкинса (JHTDB ) содержит более 350 терабайт пространственно-временных полей из прямого численного моделирования различных турбулентных течений. Такие данные было трудно разделить с использованием традиционных методов, таких как загрузка выходных файлов плоского моделирования. The data within JHTDB can be accessed using "virtual sensors" with various access modes ranging from direct web-browser queries, access through Matlab, Python, Fortran and C programs executing on clients' platforms, to cut out services to download raw data. The data have been used in over 150 scientific publications.
Спортивный
Big data can be used to improve training and understanding competitors, using sport sensors. It is also possible to predict winners in a match using big data analytics.[125]Future performance of players could be predicted as well. Thus, players' value and salary is determined by data collected throughout the season.[126]
In Formula One races, race cars with hundreds of sensors generate terabytes of data. These sensors collect data points from tire pressure to fuel burn efficiency.[127]Based on the data, engineers and data analysts decide whether adjustments should be made in order to win a race. Besides, using big data, race teams try to predict the time they will finish the race beforehand, based on simulations using data collected over the season.[128]
Технологии
- eBay.com uses two data warehouses at 7.5 petabytes and 40PB as well as a 40PB Hadoop cluster for search, consumer recommendations, and merchandising.[129]
- Amazon.com handles millions of back-end operations every day, as well as queries from more than half a million third-party sellers. The core technology that keeps Amazon running is Linux-based and as of 2005[Обновить] they had the world's three largest Linux databases, with capacities of 7.8 TB, 18.5 TB, and 24.7 TB.[130]
- Facebook handles 50 billion photos from its user base.[131] As of June 2017[Обновить], Facebook reached 2 billion monthly active users.[132]
- Google was handling roughly 100 billion searches per month as of August 2012[Обновить].[133]
COVID-19
Вовремя COVID-19 пандемия, big data was raised as a way to minimise the impact of the disease. Significant applications of big data included minimising the spread of the virus, case identification and development of medical treatment.[134]
Governments used big data to track infected people to minimise spread. Early adopters included Китай, Тайвань, Южная Корея и Израиль.[135][136][137]
Research activities
Encrypted search and cluster formation in big data were demonstrated in March 2014 at the American Society of Engineering Education. Gautam Siwach engaged at Tackling the challenges of Big Data к MIT Computer Science and Artificial Intelligence Laboratory and Dr. Amir Esmailpour at UNH Research Group investigated the key features of big data as the formation of clusters and their interconnections. They focused on the security of big data and the orientation of the term towards the presence of different types of data in an encrypted form at cloud interface by providing the raw definitions and real-time examples within the technology. Moreover, they proposed an approach for identifying the encoding technique to advance towards an expedited search over encrypted text leading to the security enhancements in big data.[138]
In March 2012, The White House announced a national "Big Data Initiative" that consisted of six Federal departments and agencies committing more than $200 million to big data research projects.[139]
The initiative included a National Science Foundation "Expeditions in Computing" grant of $10 million over 5 years to the AMPLab[140] at the University of California, Berkeley.[141] The AMPLab also received funds from DARPA, and over a dozen industrial sponsors and uses big data to attack a wide range of problems from predicting traffic congestion[142] to fighting cancer.[143]
The White House Big Data Initiative also included a commitment by the Department of Energy to provide $25 million in funding over 5 years to establish the scalable Data Management, Analysis and Visualization (SDAV) Institute,[144] led by the Energy Department's Lawrence Berkeley National Laboratory. The SDAV Institute aims to bring together the expertise of six national laboratories and seven universities to develop new tools to help scientists manage and visualize data on the Department's supercomputers.
The U.S. state of Массачусетс announced the Massachusetts Big Data Initiative in May 2012, which provides funding from the state government and private companies to a variety of research institutions.[145] В Массачусетский Институт Технологий hosts the Intel Science and Technology Center for Big Data in the MIT Computer Science and Artificial Intelligence Laboratory, combining government, corporate, and institutional funding and research efforts.[146]
The European Commission is funding the 2-year-long Big Data Public Private Forum through their Seventh Framework Program to engage companies, academics and other stakeholders in discussing big data issues. The project aims to define a strategy in terms of research and innovation to guide supporting actions from the European Commission in the successful implementation of the big data economy. Outcomes of this project will be used as input for Horizon 2020, their next framework program.[147]
The British government announced in March 2014 the founding of the Alan Turing Institute, named after the computer pioneer and code-breaker, which will focus on new ways to collect and analyze large data sets.[148]
На University of Waterloo Stratford Campus Canadian Open Data Experience (CODE) Inspiration Day, participants demonstrated how using data visualization can increase the understanding and appeal of big data sets and communicate their story to the world.[149]
Computational social sciences – Anyone can use Application Programming Interfaces (APIs) provided by big data holders, such as Google and Twitter, to do research in the social and behavioral sciences.[150] Often these APIs are provided for free.[150] Tobias Preis и другие. использовал Google Trends data to demonstrate that Internet users from countries with a higher per capita gross domestic product (GDP) are more likely to search for information about the future than information about the past. The findings suggest there may be a link between online behaviour and real-world economic indicators.[151][152][153] The authors of the study examined Google queries logs made by ratio of the volume of searches for the coming year ('2011') to the volume of searches for the previous year ('2009'), which they call the 'future orientation index '.[154] They compared the future orientation index to the per capita GDP of each country, and found a strong tendency for countries where Google users inquire more about the future to have a higher GDP. The results hint that there may potentially be a relationship between the economic success of a country and the information-seeking behavior of its citizens captured in big data.
Tobias Preis and his colleagues Helen Susannah Moat and H. Eugene Stanley introduced a method to identify online precursors for stock market moves, using trading strategies based on search volume data provided by Google Trends.[155] Their analysis of Google search volume for 98 terms of varying financial relevance, published in Scientific Reports,[156] suggests that increases in search volume for financially relevant search terms tend to precede large losses in financial markets.[157][158][159][160][161][162][163]
Big data sets come with algorithmic challenges that previously did not exist. Hence, there is a need to fundamentally change the processing ways.[164]
The Workshops on Algorithms for Modern Massive Data Sets (MMDS) bring together computer scientists, statisticians, mathematicians, and data analysis practitioners to discuss algorithmic challenges of big data.[165] Regarding big data, one needs to keep in mind that such concepts of magnitude are relative. As it is stated "If the past is of any guidance, then today’s big data most likely will not be considered as such in the near future."[70]
Sampling big data
An important research question that can be asked about big data sets is whether you need to look at the full data to draw certain conclusions about the properties of the data or is a sample good enough. The name big data itself contains a term related to size and this is an important characteristic of big data. But Sampling (statistics) enables the selection of right data points from within the larger data set to estimate the characteristics of the whole population. For example, there are about 600 million tweets produced every day. Is it necessary to look at all of them to determine the topics that are discussed during the day? Is it necessary to look at all the tweets to determine the sentiment on each of the topics? In manufacturing different types of sensory data such as acoustics, vibration, pressure, current, voltage and controller data are available at short time intervals. To predict downtime it may not be necessary to look at all the data but a sample may be sufficient. Big Data can be broken down by various data point categories such as demographic, psychographic, behavioral, and transactional data. With large sets of data points, marketers are able to create and use more customized segments of consumers for more strategic targeting.
There has been some work done in Sampling algorithms for big data. A theoretical formulation for sampling Twitter data has been developed.[166]
Critique
Critiques of the big data paradigm come in two flavors: those that question the implications of the approach itself, and those that question the way it is currently done.[167] One approach to this criticism is the field of critical data studies.
Critiques of the big data paradigm
"A crucial problem is that we do not know much about the underlying empirical micro-processes that lead to the emergence of the[se] typical network characteristics of Big Data".[17] In their critique, Snijders, Matzat, and Reips point out that often very strong assumptions are made about mathematical properties that may not at all reflect what is really going on at the level of micro-processes. Mark Graham has leveled broad critiques at Chris Anderson 's assertion that big data will spell the end of theory:[168] focusing in particular on the notion that big data must always be contextualized in their social, economic, and political contexts.[169] Even as companies invest eight- and nine-figure sums to derive insight from information streaming in from suppliers and customers, less than 40% of employees have sufficiently mature processes and skills to do so. To overcome this insight deficit, big data, no matter how comprehensive or well analyzed, must be complemented by "big judgment," according to an article in the Harvard Business Review.[170]
Much in the same line, it has been pointed out that the decisions based on the analysis of big data are inevitably "informed by the world as it was in the past, or, at best, as it currently is".[57] Fed by a large number of data on past experiences, algorithms can predict future development if the future is similar to the past.[171] If the system's dynamics of the future change (if it is not a stationary process ), the past can say little about the future. In order to make predictions in changing environments, it would be necessary to have a thorough understanding of the systems dynamic, which requires theory.[171] As a response to this critique Alemany Oliver and Vayre suggest to use "abductive reasoning as a first step in the research process in order to bring context to consumers' digital traces and make new theories emerge".[172]Additionally, it has been suggested to combine big data approaches with computer simulations, such as agent-based models[57] и complex systems. Agent-based models are increasingly getting better in predicting the outcome of social complexities of even unknown future scenarios through computer simulations that are based on a collection of mutually interdependent algorithms.[173][174] Finally, the use of multivariate methods that probe for the latent structure of the data, such as factor analysis и cluster analysis, have proven useful as analytic approaches that go well beyond the bi-variate approaches (cross-tabs) typically employed with smaller data sets.
In health and biology, conventional scientific approaches are based on experimentation. For these approaches, the limiting factor is the relevant data that can confirm or refute the initial hypothesis.[175]A new postulate is accepted now in biosciences: the information provided by the data in huge volumes (omics ) without prior hypothesis is complementary and sometimes necessary to conventional approaches based on experimentation.[176][177] In the massive approaches it is the formulation of a relevant hypothesis to explain the data that is the limiting factor.[178] The search logic is reversed and the limits of induction ("Glory of Science and Philosophy scandal", C. D. Broad, 1926) are to be considered.[нужна цитата ]
Privacy advocates are concerned about the threat to privacy represented by increasing storage and integration of personally identifiable information; expert panels have released various policy recommendations to conform practice to expectations of privacy.[179][180][181] The misuse of Big Data in several cases by media, companies and even the government has allowed for abolition of trust in almost every fundamental institution holding up society.[182]
Nayef Al-Rodhan argues that a new kind of social contract will be needed to protect individual liberties in a context of Big Data and giant corporations that own vast amounts of information. The use of Big Data should be monitored and better regulated at the national and international levels.[183] Barocas and Nissenbaum argue that one way of protecting individual users is by being informed about the types of information being collected, with whom it is shared, under what constrains and for what purposes.[184]
Critiques of the 'V' model
The 'V' model of Big Data is concerting as it centres around computational scalability and lacks in a loss around the perceptibility and understandability of information. This led to the framework of cognitive big data, which characterizes Big Data application according to:[185]
- Data completeness: understanding of the non-obvious from data;
- Data correlation, causation, and predictability: causality as not essential requirement to achieve predictability;
- Explainability and interpretability: humans desire to understand and accept what they understand, where algorithms don't cope with this;
- Level of automated decision making: algorithms that support automated decision making and algorithmic self-learning;
Critiques of novelty
Large data sets have been analyzed by computing machines for well over a century, including the US census analytics performed by IBM 's punch-card machines which computed statistics including means and variances of populations across the whole continent. In more recent decades, science experiments such as CERN have produced data on similar scales to current commercial "big data". However, science experiments have tended to analyze their data using specialized custom-built high-performance computing (super-computing) clusters and grids, rather than clouds of cheap commodity computers as in the current commercial wave, implying a difference in both culture and technology stack.
Critiques of big data execution
Ulf-Dietrich Reips and Uwe Matzat wrote in 2014 that big data had become a "fad" in scientific research.[150] Исследователь Danah Boyd has raised concerns about the use of big data in science neglecting principles such as choosing a representative sample by being too concerned about handling the huge amounts of data.[186] This approach may lead to results that have bias in one way or another.[187] Integration across heterogeneous data resources—some that might be considered big data and others not—presents formidable logistical as well as analytical challenges, but many researchers argue that such integrations are likely to represent the most promising new frontiers in science.[188]In the provocative article "Critical Questions for Big Data",[189] the authors title big data a part of mythology: "large data sets offer a higher form of intelligence and knowledge [...], with the aura of truth, objectivity, and accuracy". Users of big data are often "lost in the sheer volume of numbers", and "working with Big Data is still subjective, and what it quantifies does not necessarily have a closer claim on objective truth".[189] Recent developments in BI domain, such as pro-active reporting especially target improvements in usability of big data, through automated filtering из non-useful data and correlations.[190] Big structures are full of spurious correlations[191] either because of non-causal coincidences (law of truly large numbers ), solely nature of big randomness[192] (Теория Рамсея ) or existence of non-included factors so the hope, of early experimenters to make large databases of numbers "speak for themselves" and revolutionize scientific method, is questioned.[193]
Big data analysis is often shallow compared to analysis of smaller data sets.[194] In many big data projects, there is no large data analysis happening, but the challenge is the extract, transform, load part of data pre-processing.[194]
Big data is a модное слово and a "vague term",[195][196] but at the same time an "obsession"[196] with entrepreneurs, consultants, scientists and the media. Big data showcases such as Google Flu Trends failed to deliver good predictions in recent years, overstating the flu outbreaks by a factor of two. По аналогии, Academy awards and election predictions solely based on Twitter were more often off than on target.Big data often poses the same challenges as small data; adding more data does not solve problems of bias, but may emphasize other problems. In particular data sources such as Twitter are not representative of the overall population, and results drawn from such sources may then lead to wrong conclusions. переводчик Google —which is based on big data statistical analysis of text—does a good job at translating web pages. However, results from specialized domains may be dramatically skewed.On the other hand, big data may also introduce new problems, such as the multiple comparisons problem: simultaneously testing a large set of hypotheses is likely to produce many false results that mistakenly appear significant.Ioannidis argued that "most published research findings are false"[197] due to essentially the same effect: when many scientific teams and researchers each perform many experiments (i.e. process a big amount of scientific data; although not with big data technology), the likelihood of a "significant" result being false grows fast – even more so, when only positive results are published.Furthermore, big data analytics results are only as good as the model on which they are predicated. In an example, big data took part in attempting to predict the results of the 2016 U.S. Presidential Election[198] with varying degrees of success.
Critiques of big data policing and surveillance
Big Data has been used in policing and surveillance by institutions like правоохранительные органы и корпорации.[199] Due to the less visible nature of data-based surveillance as compared to traditional method of policing, objections to big data policing are less likely to arise. According to Sarah Brayne's Big Data Surveillance: The Case of Policing,[200] big data policing can reproduce existing societal inequalities in three ways:
- Placing suspected criminals under increased surveillance by using the justification of a mathematical and therefore unbiased algorithm;
- Increasing the scope and number of people that are subject to law enforcement tracking and exacerbating existing racial overrepresentation in the criminal justice system;
- Encouraging members of society to abandon interactions with institutions that would create a digital trace, thus creating obstacles to social inclusion.
If these potential problems are not corrected or regulating, the effects of big data policing continue to shape societal hierarchies. Conscientious usage of big data policing could prevent individual level biases from becoming institutional biases, Brayne also notes.
В популярной культуре
Книги
- Moneyball is a non-fiction book that explores how the Oakland Athletics used statistical analysis to outperform teams with larger budgets. In 2011 a экранизация в главных ролях Brad Pitt was released.
- 1984 is a dystopian novel by Джордж Оруэлл. In 1984 the government collects information on citizens and uses the information to maintain an totalitarian rule.
Фильм
- В Капитан Америка: Зимний солдат H.Y.D.R.A (disguised as S.H.I.E.L.D ) develops helicarriers that use data to determine and eliminate threats over the globe.
- В The Dark Knight, Бэтмен uses a sonar device that can spy on all of Gotham City. The data is gathered from the mobile phones of people within the city.
Смотрите также
Рекомендации
- ^ Hilbert, Martin; López, Priscila (2011). "The World's Technological Capacity to Store, Communicate, and Compute Information". Наука. 332 (6025): 60–65. Bibcode:2011Sci...332...60H. Дои:10.1126/science.1200970. PMID 21310967. S2CID 206531385. Получено 13 апреля 2016.
- ^ Breur, Tom (July 2016). "Statistical Power Analysis and the contemporary "crisis" in social sciences". Journal of Marketing Analytics. 4 (2–3): 61–65. Дои:10.1057/s41270-016-0001-3. ISSN 2050-3318.
- ^ boyd, dana; Crawford, Kate (21 September 2011). "Six Provocations for Big Data". Social Science Research Network: A Decade in Internet Time: Symposium on the Dynamics of the Internet and Society. Дои:10.2139/ssrn.1926431. S2CID 148610111.
- ^ а б c d е ж грамм "Data, data everywhere". Экономист. 25 February 2010. Получено 9 декабря 2012.
- ^ "Community cleverness required". Природа. 455 (7209): 1. September 2008. Bibcode:2008Natur.455....1.. Дои:10.1038/455001a. PMID 18769385.
- ^ Reichman OJ, Jones MB, Schildhauer MP (February 2011). "Challenges and opportunities of open data in ecology". Наука. 331 (6018): 703–5. Bibcode:2011Sci...331..703R. Дои:10.1126/science.1197962. PMID 21311007. S2CID 22686503.
- ^ Hellerstein, Joe (9 November 2008). "Parallel Programming in the Age of Big Data". Gigaom Blog.
- ^ Segaran, Toby; Hammerbacher, Jeff (2009). Beautiful Data: The Stories Behind Elegant Data Solutions. O'Reilly Media. п. 257. ISBN 978-0-596-15711-1.
- ^ а б Hilbert M, López P (April 2011). "The world's technological capacity to store, communicate, and compute information" (PDF). Наука. 332 (6025): 60–5. Bibcode:2011Sci...332...60H. Дои:10.1126/science.1200970. PMID 21310967. S2CID 206531385.
- ^ "IBM What is big data? – Bringing big data to the enterprise". ibm.com. Получено 26 августа 2013.
- ^ Reinsel, David; Gantz, John; Rydning, John (13 April 2017). "Data Age 2025: The Evolution of Data to Life-Critical" (PDF). seagate.com. Framingham, MA, US: International Data Corporation. Получено 2 November 2017.
- ^ Oracle and FSN, "Mastering Big Data: CFO Strategies to Transform Insight into Opportunity" В архиве 4 August 2013 at the Wayback Machine, December 2012
- ^ Jacobs, A. (6 July 2009). "The Pathologies of Big Data". ACMQueue.
- ^ Magoulas, Roger; Lorica, Ben (February 2009). "Introduction to Big Data". Release 2.0. Sebastopol CA: O'Reilly Media (11).
- ^ John R. Mashey (25 April 1998). "Big Data ... and the Next Wave of InfraStress" (PDF). Slides from invited talk. Usenix. Получено 28 September 2016.
- ^ Steve Lohr (1 February 2013). "The Origins of 'Big Data': An Etymological Detective Story". Нью-Йорк Таймс. Получено 28 September 2016.
- ^ а б Snijders, C.; Matzat, U.; Reips, U.-D. (2012). "'Big Data': Big gaps of knowledge in the field of Internet". International Journal of Internet Science. 7: 1–5.
- ^ Dedić, N.; Stanier, C. (2017). "Towards Differentiating Business Intelligence, Big Data, Data Analytics and Knowledge Discovery". Innovations in Enterprise Information Systems Management and Engineering. Lecture Notes in Business Information Processing. 285. Berlin ; Heidelberg: Springer International Publishing. pp. 114–122. Дои:10.1007/978-3-319-58801-8_10. ISBN 978-3-319-58800-1. ISSN 1865-1356. OCLC 909580101.
- ^ Everts, Sarah (2016). "Information Overload". Distillations. Vol. 2 no. 2. pp. 26–33. Получено 22 марта 2018.
- ^ Ibrahim; Targio Hashem, Abaker; Yaqoob, Ibrar; Badrul Anuar, Nor; Mokhtar, Salimah; Gani, Abdullah; Ullah Khan, Samee (2015). "big data" on cloud computing: Review and open research issues". Информационные системы. 47: 98–115. Дои:10.1016/j.is.2014.07.006.
- ^ Grimes, Seth. "Big Data: Avoid 'Wanna V' Confusion". InformationWeek. Получено 5 января 2016.
- ^ Fox, Charles (25 March 2018). Data Science for Transport. Springer Textbooks in Earth Sciences, Geography and Environment. Springer. ISBN 9783319729527.
- ^ "avec focalisation sur Big Data & Analytique" (PDF). Bigdataparis.com. Получено 8 октября 2017.
- ^ а б Billings S.A. "Nonlinear System Identification: NARMAX Methods in the Time, Frequency, and Spatio-Temporal Domains". Wiley, 2013
- ^ "le Blog ANDSI » DSI Big Data". Andsi.fr. Получено 8 октября 2017.
- ^ Les Echos (3 April 2013). "Les Echos – Big Data car Low-Density Data ? La faible densité en information comme facteur discriminant – Archives". Lesechos.fr. Получено 8 октября 2017.
- ^ Sagiroglu, Seref (2013). "Big data: A review". 2013 International Conference on Collaboration Technologies and Systems (CTS): 42–47. Дои:10.1109/CTS.2013.6567202. ISBN 978-1-4673-6404-1. S2CID 5724608.
- ^ Kitchin, Rob; McArdle, Gavin (17 February 2016). "What makes Big Data, Big Data? Exploring the ontological characteristics of 26 datasets". Big Data & Society. 3 (1): 205395171663113. Дои:10.1177/2053951716631130.
- ^ Onay, Ceylan; Öztürk, Elif (2018). "A review of credit scoring research in the age of Big Data". Journal of Financial Regulation and Compliance. 26 (3): 382–405. Дои:10.1108/JFRC-06-2017-0054.
- ^ Big Data's Fourth V
- ^ Kitchin, Rob; McArdle, Gavin (5 January 2016). "What makes Big Data, Big Data? Exploring the ontological characteristics of 26 datasets". Big Data & Society. 3 (1): 205395171663113. Дои:10.1177/2053951716631130. ISSN 2053-9517.
- ^ "Survey: Biggest Databases Approach 30 Terabytes". Eweek.com. Получено 8 октября 2017.
- ^ "LexisNexis To Buy Seisint For $775 Million". Вашингтон Пост. Получено 15 июля 2004.
- ^ https://www.washingtonpost.com/wp-dyn/content/article/2008/02/21/AR2008022100809.html
- ^ Bertolucci, Jeff "Hadoop: From Experiment To Leading Big Data Platform", "Information Week", 2013. Retrieved on 14 November 2013.
- ^ Webster, John. "MapReduce: Simplified Data Processing on Large Clusters", "Search Storage", 2004. Retrieved on 25 March 2013.
- ^ "Big Data Solution Offering". MIKE2.0. Получено 8 декабря 2013.
- ^ "Big Data Definition". MIKE2.0. Получено 9 марта 2013.
- ^ Boja, C; Pocovnicu, A; Bătăgan, L. (2012). "Distributed Parallel Architecture for Big Data". Informatica Economica. 16 (2): 116–127.
- ^ "SOLVING KEY BUSINESS CHALLENGES WITH A BIG DATA LAKE" (PDF). Hcltech.com. August 2014. Получено 8 октября 2017.
- ^ "Method for testing the fault tolerance of MapReduce frameworks" (PDF). Computer Networks. 2015 г.
- ^ а б Manyika, James; Chui, Michael; Bughin, Jaques; Brown, Brad; Dobbs, Richard; Roxburgh, Charles; Byers, Angela Hung (May 2011). "Big Data: The next frontier for innovation, competition, and productivity". McKinsey Global Institute. Получено 16 января 2016. Цитировать журнал требует
| журнал =(помощь) - ^ "Future Directions in Tensor-Based Computation and Modeling" (PDF). May 2009.
- ^ Lu, Haiping; Plataniotis, K.N.; Venetsanopoulos, A.N. (2011). "A Survey of Multilinear Subspace Learning for Tensor Data" (PDF). Pattern Recognition. 44 (7): 1540–1551. Дои:10.1016/j.patcog.2011.01.004.
- ^ Pllana, Sabri; Janciak, Ivan; Brezany, Peter; Wöhrer, Alexander (2016). "A Survey of the State of the Art in Data Mining and Integration Query Languages". 2011 14th International Conference on Network-Based Information Systems. 2011 International Conference on Network-Based Information Systems (NBIS 2011). IEEE Computer Society. pp. 341–348. arXiv:1603.01113. Bibcode:2016arXiv160301113P. Дои:10.1109/NBiS.2011.58. ISBN 978-1-4577-0789-6. S2CID 9285984.
- ^ Wang, Yandong; Goldstone, Robin; Yu, Weikuan; Wang, Teng (October 2014). "Characterization and Optimization of Memory-Resident MapReduce on HPC Systems". 2014 IEEE 28th International Parallel and Distributed Processing Symposium. IEEE. pp. 799–808. Дои:10.1109/IPDPS.2014.87. ISBN 978-1-4799-3800-1. S2CID 11157612.
- ^ L'Heureux, A.; Grolinger, K.; Elyamany, H. F.; Capretz, M. A. M. (2017). "Machine Learning With Big Data: Challenges and Approaches". Доступ IEEE. 5: 7776–7797. Дои:10.1109/ACCESS.2017.2696365. ISSN 2169-3536.
- ^ Monash, Curt (30 April 2009). "eBay's two enormous data warehouses".
Monash, Curt (6 October 2010). "eBay followup – Greenplum out, Teradata > 10 petabytes, Hadoop has some value, and more". - ^ "Resources on how Topological Data Analysis is used to analyze big data". Ayasdi.
- ^ CNET News (1 April 2011). "Storage area networks need not apply".
- ^ "How New Analytic Systems will Impact Storage". Сентябрь 2011. Архивировано с оригинал on 1 March 2012.
- ^ Hilbert, Martin (2014). "What is the Content of the World's Technologically Mediated Information and Communication Capacity: How Much Text, Image, Audio, and Video?". The Information Society. 30 (2): 127–143. Дои:10.1080/01972243.2013.873748. S2CID 45759014.
- ^ Rajpurohit, Anmol (11 July 2014). "Interview: Amy Gershkoff, Director of Customer Analytics & Insights, eBay on How to Design Custom In-House BI Tools". KDnuggets. Получено 14 July 2014.
Dr. Amy Gershkoff: "Generally, I find that off-the-shelf business intelligence tools do not meet the needs of clients who want to derive custom insights from their data. Therefore, for medium-to-large organizations with access to strong technical talent, I usually recommend building custom, in-house solutions."
- ^ "The Government and big data: Use, problems and potential". Computerworld. 21 марта 2012 г.. Получено 12 сентября 2016.
- ^ "White Paper: Big Data for Development: Opportunities & Challenges (2012) – United Nations Global Pulse". Unglobalpulse.org. Получено 13 апреля 2016.
- ^ "WEF (World Economic Forum), & Vital Wave Consulting. (2012). Big Data, Big Impact: New Possibilities for International Development". World Economic Forum. Получено 24 августа 2012.
- ^ а б c d Hilbert, Martin (15 January 2013). "Big Data for Development: From Information- to Knowledge Societies". SSRN 2205145. Цитировать журнал требует
| журнал =(помощь) - ^ "Elena Kvochko, Four Ways To talk About Big Data (Information Communication Technologies for Development Series)". worldbank.org. 4 декабря 2012 г.. Получено 30 мая 2012.
- ^ "Daniele Medri: Big Data & Business: An on-going revolution". Statistics Views. 21 October 2013.
- ^ Tobias Knobloch and Julia Manske (11 January 2016). "Responsible use of data". D+C, Development and Cooperation.
- ^ Huser V, Cimino JJ (July 2016). "Impending Challenges for the Use of Big Data". International Journal of Radiation Oncology, Biology, Physics. 95 (3): 890–894. Дои:10.1016/j.ijrobp.2015.10.060. ЧВК 4860172. PMID 26797535.
- ^ Sejdic, Ervin; Falk, Tiago H. (4 July 2018). Signal Processing and Machine Learning for Biomedical Big Data. Sejdić, Ervin, Falk, Tiago H. [Place of publication not identified]. ISBN 9781351061216. OCLC 1044733829.
- ^ Raghupathi W, Raghupathi V (December 2014). "Big data analytics in healthcare: promise and potential". Health Information Science and Systems. 2 (1): 3. Дои:10.1186/2047-2501-2-3. ЧВК 4341817. PMID 25825667.
- ^ Viceconti M, Hunter P, Hose R (July 2015). "Big data, big knowledge: big data for personalized healthcare" (PDF). IEEE Journal of Biomedical and Health Informatics. 19 (4): 1209–15. Дои:10.1109/JBHI.2015.2406883. PMID 26218867. S2CID 14710821.
- ^ O'Donoghue, John; Herbert, John (1 October 2012). "Data Management Within mHealth Environments: Patient Sensors, Mobile Devices, and Databases". Journal of Data and Information Quality. 4 (1): 5:1–5:20. Дои:10.1145/2378016.2378021. S2CID 2318649.
- ^ Mirkes EM, Coats TJ, Levesley J, Gorban AN (August 2016). "Handling missing data in large healthcare dataset: A case study of unknown trauma outcomes". Computers in Biology and Medicine. 75: 203–16. arXiv:1604.00627. Bibcode:2016arXiv160400627M. Дои:10.1016/j.compbiomed.2016.06.004. PMID 27318570. S2CID 5874067.
- ^ Murdoch TB, Detsky AS (April 2013). "The inevitable application of big data to health care". JAMA. 309 (13): 1351–2. Дои:10.1001/jama.2013.393. PMID 23549579.
- ^ Vayena E, Salathé M, Madoff LC, Brownstein JS (February 2015). "Ethical challenges of big data in public health". PLOS вычислительная биология. 11 (2): e1003904. Bibcode:2015PLSCB..11E3904V. Дои:10.1371/journal.pcbi.1003904. ЧВК 4321985. PMID 25664461.
- ^ Copeland, CS (July–August 2017). "Data Driving Discovery" (PDF). Healthcare Journal of New Orleans: 22–27.
- ^ а б Yanase J, Triantaphyllou E (2019). "A Systematic Survey of Computer-Aided Diagnosis in Medicine: Past and Present Developments". Expert Systems with Applications. 138: 112821. Дои:10.1016/j.eswa.2019.112821.
- ^ Dong X, Bahroos N, Sadhu E, Jackson T, Chukhman M, Johnson R, Boyd A, Hynes D (2013). "Leverage Hadoop framework for large scale clinical informatics applications". AMIA Joint Summits on Translational Science Proceedings. AMIA Joint Summits on Translational Science. 2013: 53. PMID 24303235.
- ^ Clunie D (2013). "Breast tomosynthesis challenges digital imaging infrastructure". Цитировать журнал требует
| журнал =(помощь) - ^ Yanase J, Triantaphyllou E (2019). "The Seven Key Challenges for the Future of Computer-Aided Diagnosis in Medicine". Journal of Medical Informatics. 129: 413–422. Дои:10.1016/j.ijmedinf.2019.06.017. PMID 31445285.
- ^ "Degrees in Big Data: Fad or Fast Track to Career Success". Forbes. Получено 21 February 2016.
- ^ "NY gets new boot camp for data scientists: It's free but harder to get into than Harvard". Венчурный бит. Получено 21 February 2016.
- ^ Wedel, Michel; Kannan, PK (2016). "Marketing Analytics for Data-Rich Environments". Журнал маркетинга. 80 (6): 97–121. Дои:10.1509/jm.15.0413. S2CID 168410284.
- ^ Couldry, Nick; Turow, Joseph (2014). "Advertising, Big Data, and the Clearance of the Public Realm: Marketers' New Approaches to the Content Subsidy". International Journal of Communication. 8: 1710–1726.
- ^ "Why Digital Advertising Agencies Suck at Acquisition and are in Dire Need of an AI Assisted Upgrade". Ishti.org. 15 April 2018. Получено 15 апреля 2018.
- ^ "Big data and analytics: C4 and Genius Digital". Ibc.org. Получено 8 октября 2017.
- ^ Marshall Allen (17 July 2018). "Health Insurers Are Vacuuming Up Details About You – And It Could Raise Your Rates". www.propublica.org. Получено 21 July 2018.
- ^ "QuiO Named Innovation Champion of the Accenture HealthTech Innovation Challenge". Businesswire.com. 10 January 2017. Получено 8 октября 2017.
- ^ "A Software Platform for Operational Technology Innovation" (PDF). Predix.com. Получено 8 октября 2017.
- ^ Z. Jenipher Wang (March 2017). "Big Data Driven Smart Transportation: the Underlying Story of IoT Transformed Mobility".
- ^ "That Internet Of Things Thing".
- ^ а б Solnik, Ray. "The Time Has Come: Analytics Delivers for IT Operations". Data Center Journal. Получено 21 июн 2016.
- ^ Josh Rogin (2 August 2018). "Ethnic cleansing makes a comeback – in China" (Washington Post). Получено 4 августа 2018.
Add to that the unprecedented security and surveillance state in Xinjiang, which includes all-encompassing monitoring based on identity cards, checkpoints, facial recognition and the collection of DNA from millions of individuals. The authorities feed all this data into an artificial-intelligence machine that rates people's loyalty to the Communist Party in order to control every aspect of their lives.
- ^ "China: Big Data Fuels Crackdown in Minority Region: Predictive Policing Program Flags Individuals for Investigations, Detentions". hrw.org. Хьюман Райтс Вотч. 26 February 2018. Получено 4 августа 2018.
- ^ "Discipline and Punish: The Birth of China's Social-Credit System". Нация. 23 января 2019.
- ^ "China's behavior monitoring system bars some from travel, purchasing property". CBS Новости. 24 апреля 2018.
- ^ "The complicated truth about China's social credit system". WIRED. 21 января 2019.
- ^ "News: Live Mint". Are Indian companies making enough sense of Big Data?. Live Mint. 23 июня 2014 г.. Получено 22 ноября 2014.
- ^ "Israeli startup uses big data, minimal hardware to treat diabetes". Получено 28 февраля 2018.
- ^ "Survey on Big Data Using Data Mining" (PDF). International Journal of Engineering Development and Research. 2015 г.. Получено 14 сентября 2016.
- ^ "Recent advances delivered by Mobile Cloud Computing and Internet of Things for Big Data applications: a survey". International Journal of Network Management. 11 March 2016. Получено 14 сентября 2016.
- ^ Kalil, Tom (29 March 2012). "Big Data is a Big Deal". White House. Получено 26 сентября 2012.
- ^ Executive Office of the President (March 2012). "Big Data Across the Federal Government" (PDF). White House. Архивировано из оригинал (PDF) on 11 December 2016. Получено 26 сентября 2012.
- ^ Lampitt, Andrew (14 February 2013). "The real story of how big data analytics helped Obama win". InfoWorld. Получено 31 мая 2014.
- ^ "November 2018 | TOP500 Supercomputer Sites".
- ^ Hoover, J. Nicholas. "Government's 10 Most Powerful Supercomputers". Информационная неделя. UBM. Получено 26 сентября 2012.
- ^ Bamford, James (15 March 2012). "The NSA Is Building the Country's Biggest Spy Center (Watch What You Say)". Wired Magazine. Получено 18 марта 2013.
- ^ "Groundbreaking Ceremony Held for $1.2 Billion Utah Data Center". National Security Agency Central Security Service. Архивировано из оригинал 5 сентября 2013 г.. Получено 18 марта 2013.
- ^ Hill, Kashmir. "Blueprints of NSA's Ridiculously Expensive Data Center in Utah Suggest It Holds Less Info Than Thought". Forbes. Получено 31 октября 2013.
- ^ Smith, Gerry; Hallman, Ben (12 June 2013). "NSA Spying Controversy Highlights Embrace of Big Data". Huffington Post. Получено 7 мая 2018.
- ^ Wingfield, Nick (12 March 2013). "Predicting Commutes More Accurately for Would-Be Home Buyers – NYTimes.com". Bits.blogs.nytimes.com. Получено 21 July 2013.
- ^ "FICO® Falcon® Fraud Manager". Fico.com. Получено 21 July 2013.
- ^ Alexandru, Dan. "Prof" (PDF). cds.cern.ch. CERN. Получено 24 марта 2015.
- ^ "LHC Brochure, English version. A presentation of the largest and the most powerful particle accelerator in the world, the Large Hadron Collider (LHC), which started up in 2008. Its role, characteristics, technologies, etc. are explained for the general public". CERN-Brochure-2010-006-Eng. LHC Brochure, English version. CERN. Получено 20 January 2013.
- ^ "LHC Guide, English version. A collection of facts and figures about the Large Hadron Collider (LHC) in the form of questions and answers". CERN-Brochure-2008-001-Eng. LHC Guide, English version. CERN. Получено 20 January 2013.
- ^ Brumfiel, Geoff (19 January 2011). "High-energy physics: Down the petabyte highway". Природа. 469. pp. 282–83. Bibcode:2011Natur.469..282B. Дои:10.1038/469282a.
- ^ "IBM Research – Zurich" (PDF). Zurich.ibm.com. Получено 8 октября 2017.
- ^ "Future telescope array drives development of Exabyte processing". Ars Technica. Получено 15 апреля 2015.
- ^ "Australia's bid for the Square Kilometre Array – an insider's perspective". The Conversation. 1 февраля 2012 г.. Получено 27 сентября 2016.
- ^ "Delort P., OECD ICCP Technology Foresight Forum, 2012" (PDF). Oecd.org. Получено 8 октября 2017.
- ^ "NASA – NASA Goddard Introduces the NASA Center for Climate Simulation". Nasa.gov. Получено 13 апреля 2016.
- ^ Webster, Phil. "Supercomputing the Climate: NASA's Big Data Mission". CSC World. Computer Sciences Corporation. Архивировано из оригинал on 4 January 2013. Получено 18 January 2013.
- ^ "These six great neuroscience ideas could make the leap from lab to market". Глобус и почта. 20 November 2014. Получено 1 октября 2016.
- ^ "DNAstack tackles massive, complex DNA datasets with Google Genomics". Облачная платформа Google. Получено 1 октября 2016.
- ^ "23andMe – Ancestry". 23andme.com. Получено 29 декабря 2016.
- ^ а б Potenza, Alessandra (13 July 2016). "23andMe wants researchers to use its kits, in a bid to expand its collection of genetic data". Грани. Получено 29 декабря 2016.
- ^ "This Startup Will Sequence Your DNA, So You Can Contribute To Medical Research". Быстрая Компания. 23 December 2016. Получено 29 декабря 2016.
- ^ Seife, Charles. "23andMe Is Terrifying, but Not for the Reasons the FDA Thinks". Scientific American. Получено 29 декабря 2016.
- ^ Zaleski, Andrew (22 June 2016). "This biotech start-up is betting your genes will yield the next wonder drug". CNBC. Получено 29 декабря 2016.
- ^ Regalado, Antonio. «Как 23andMe превратил вашу ДНК в машину для открытия лекарств стоимостью 1 миллиард долларов». Обзор технологий MIT. Получено 29 декабря 2016.
- ^ «23andMe сообщает о резком росте запросов на получение данных после исследования депрессии Pfizer | FierceBiotech». fiercebiotech.com. Получено 29 декабря 2016.
- ^ Полюбуйтесь Мойо. «Специалисты по анализу данных предсказывают поражение Спрингбока». itweb.co.za. Получено 12 декабря 2015.
- ^ Регина Пазвакавамбва. «Прогнозная аналитика, большие данные трансформируют спорт». itweb.co.za. Получено 12 декабря 2015.
- ^ Дэйв Райан. «Спорт: где большие данные, наконец, имеют смысл». huffingtonpost.com. Получено 12 декабря 2015.
- ^ Фрэнк Би. «Как команды Формулы-1 используют большие данные, чтобы получить доступ изнутри». Forbes. Получено 12 декабря 2015.
- ^ Тай, Лиз. "Внутри хранилища данных eBay 90 ПБ". ITNews. Получено 12 февраля 2016.
- ^ Лейтон, Джулия. «Amazon Technology». Money.howstuffworks.com. Получено 5 марта 2013.
- ^ «Масштабирование Facebook до 500 миллионов пользователей и не только». Facebook.com. Получено 21 июля 2013.
- ^ Константин, Джош (27 июня 2017 г.). «Facebook теперь имеет 2 миллиарда пользователей в месяц… и ответственность». TechCrunch. Получено 3 сентября 2018.
- ^ «Google по-прежнему выполняет не менее 1 триллиона запросов в год». Search Engine Land. 16 января 2015 г.. Получено 15 апреля 2015.
- ^ Халим, Абид; Джавид, Мохд; Хан, Ибрагим; Вайшья, Раджу (2020). «Важные применения больших данных в пандемии COVID-19». Индийский журнал ортопедии. 54 (4): 526–528. Дои:10.1007 / s43465-020-00129-z. ЧВК 7204193. PMID 32382166.
- ^ Мананкур, Винсент (10 марта 2020 г.). «Коронавирус проверяет решимость Европы в отношении конфиденциальности». Политико. Получено 30 октября 2020.
- ^ Чоудхури, Амит Рой (27 марта 2020 г.). «Правительство во времена короны». Gov Insider. Получено 30 октября 2020.
- ^ Селлан-Джонс, Рори (11 февраля 2020 г.). «Китай запускает приложение« Детектор близкого контакта »коронавируса». BBC. Архивировано из оригинал 28 февраля 2020 г.. Получено 30 октября 2020.
- ^ Сивах, Гаутам; Эсмаилпур, Амир (март 2014 г.). Зашифрованный поиск и формирование кластеров в больших данных (PDF). Конференция ASEE 2014 Zone I. Университет Бриджпорта, Бриджпорт, Коннектикут, США. Архивировано из оригинал (PDF) 9 августа 2014 г.. Получено 26 июля 2014.
- ^ «Администрация Обамы представляет инициативу« Большие данные »: объявляет о новых инвестициях в НИОКР на сумму 200 миллионов долларов» (PDF). Белый дом. Архивировано из оригинал (PDF) 1 ноября 2012 г.
- ^ "AMPLab в Калифорнийском университете в Беркли". Amplab.cs.berkeley.edu. Получено 5 марта 2013.
- ^ «NSF возглавляет федеральные усилия в области больших данных». Национальный научный фонд (NSF). 29 марта 2012 г.
- ^ Тимоти Хантер; Теодор Молдован; Матей Захария; Джастин Ма; Майкл Франклин; Питер Аббель; Александр Байен (октябрь 2011 г.). Масштабирование системы Mobile Millennium в облаке.
- ^ Дэвид Паттерсон (5 декабря 2011 г.). «У компьютерных ученых есть все, что нужно, чтобы помочь вылечить рак». Нью-Йорк Таймс.
- ^ «Секретарь Чу объявляет о создании нового института, который поможет ученым улучшить исследования массивов данных на суперкомпьютерах Министерства энергетики». energy.gov.
- ^ office / pressreleases / 2012/2012530-губернатор-анонс-большие-данные-инициативы.html "Губернатор Патрик объявляет о новой инициативе по укреплению позиций Массачусетса как мирового лидера в области больших данных" Проверять
| url =ценить (помощь). Содружество Массачусетса. - ^ «Большие данные @ CSAIL». Bigdata.csail.mit.edu. 22 февраля 2013 г.. Получено 5 марта 2013.
- ^ "Государственно-частный форум по большим данным". cordis.europa.eu. 1 сентября 2012 г.. Получено 16 марта 2020.
- ^ «Институт Алана Тьюринга будет создан для исследования больших данных». Новости BBC. 19 марта 2014 г.. Получено 19 марта 2014.
- ^ «День вдохновения в Университете Ватерлоо, Стратфордский кампус». betakit.com/. Получено 28 февраля 2014.
- ^ а б c Рейпс, Ульф-Дитрих; Мацат, Уве (2014). «Майнинг« больших данных »с помощью сервисов больших данных». Международный журнал интернет-науки. 1 (1): 1–8.
- ^ Прейс Т., Моат Х.С., Стэнли Х.Э., Епископ С.Р. (2012). «Количественная оценка преимущества ожидания». Научные отчеты. 2: 350. Bibcode:2012НатСР ... 2Е.350П. Дои:10.1038 / srep00350. ЧВК 3320057. PMID 22482034.
- ^ Марк, Пол (5 апреля 2012 г.). «Интернет-поиск будущего, связанный с экономическим успехом». Новый ученый. Получено 9 апреля 2012.
- ^ Джонстон, Кейси (6 апреля 2012 г.). «Google Trends дает подсказки о менталитете более богатых стран». Ars Technica. Получено 9 апреля 2012.
- ^ Тобиас Прейс (24 мая 2012 г.). «Дополнительная информация: Индекс ориентации на будущее доступен для загрузки» (PDF). Получено 24 мая 2012.
- ^ Филип Болл (26 апреля 2013 г.). «Подсчет поисковых запросов в Google предсказывает движения рынка». Природа. Получено 9 августа 2013.
- ^ Прейс Т., Моат Х.С., Стэнли Х.Э. (2013). «Количественная оценка торгового поведения на финансовых рынках с помощью Google Trends». Научные отчеты. 3: 1684. Bibcode:2013НатСР ... 3Э1684П. Дои:10.1038 / srep01684. ЧВК 3635219. PMID 23619126.
- ^ Ник Билтон (26 апреля 2013 г.). «Поисковые запросы Google могут предсказывать фондовый рынок, результаты исследований». Нью-Йорк Таймс. Получено 9 августа 2013.
- ^ Кристофер Мэтьюз (26 апреля 2013 г.). "Проблемы с вашим инвестиционным портфелем? Google It!". Журнал Тайм. Получено 9 августа 2013.
- ^ Филип Болл (26 апреля 2013 г.). «Подсчет поисковых запросов в Google предсказывает движения рынка». Природа. Получено 9 августа 2013.
- ^ Бернхард Уорнер (25 апреля 2013 г.). "'Исследователи "больших данных" обращаются к Google, чтобы обойти рынки ". Bloomberg Businessweek. Получено 9 августа 2013.
- ^ Хэмиш МакРэй (28 апреля 2013 г.). «Хэмиш МакРэй: Нужна ценная информация о настроениях инвесторов? Погуглите». Независимый. Лондон. Получено 9 августа 2013.
- ^ Ричард Уотерс (25 апреля 2013 г.). «Поиск в Google оказался новым словом в прогнозировании фондового рынка». Financial Times. Получено 9 августа 2013.
- ^ Джейсон Палмер (25 апреля 2013 г.). «Поиск в Google предсказывает движение рынка». BBC. Получено 9 августа 2013.
- ^ Э. Сейдич, «Адаптируйте существующие инструменты для использования с большими данными», Природа, т. 507, нет. 7492, стр. 306, март 2014 г.
- ^ Стэнфорд."MMDS. Практикум по алгоритмам для современных массивов данных".
- ^ Дипан Палгуна; Викас Джоши; Венкатесан Чакраварти; Рави Котари и Л. В. Субраманиам (2015). Анализ алгоритмов выборки для Twitter. Международная совместная конференция по искусственному интеллекту.
- ^ Kimble, C .; Милолидакис, Г. (2015). «Большие данные и бизнес-аналитика: развенчание мифов». Глобальный бизнес и организационное совершенство. 35 (1): 23–34. arXiv:1511.03085. Bibcode:2015arXiv151103085K. Дои:10.1002 / joe.21642. S2CID 21113389.
- ^ Крис Андерсон (23 июня 2008 г.). «Конец теории: поток данных делает научный метод устаревшим». ПРОВОДНОЙ.
- ^ Грэм М. (9 марта 2012 г.). «Большие данные и конец теории?». Хранитель. Лондон.
- ^ Шах, Шветанк; Хорн, Эндрю; Капелла, Хайме (апрель 2012 г.). «Хорошие данные не гарантируют правильных решений. Harvard Business Review». HBR.org. Получено 8 сентября 2012.
- ^ а б Большие данные требуют большого видения для больших изменений., Гильберт, М. (2014). Лондон: TEDx UCL, x = независимо организованные выступления на TED
- ^ Алемани Оливер, Матьё; Вайр, Жан-Себастьян (2015). «Большие данные и будущее производства знаний в маркетинговых исследованиях: этика, цифровые следы и абдуктивное мышление». Журнал маркетинговой аналитики. 3 (1): 5–13. Дои:10.1057 / jma.2015.1. S2CID 111360835.
- ^ Джонатан Раух (1 апреля 2002 г.). "Осматривая за углами". Атлантический океан.
- ^ Эпштейн, Дж. М., и Акстелл, Р. Л. (1996). Растущие искусственные общества: социальные науки снизу вверх. Книга Брэдфорда.
- ^ "Делорт П., Большие данные в биологических науках, Большие данные, Париж, 2012" (PDF). Bigdataparis.com. Получено 8 октября 2017.
- ^ «Геномика нового поколения: интегративный подход» (PDF). природа. Июль 2010 г.. Получено 18 октября 2016.
- ^ «БОЛЬШИЕ ДАННЫЕ В БИОЛОГИИ». Октябрь 2015 г.. Получено 18 октября 2016.
- ^ «Большие данные: мы делаем большую ошибку?». Financial Times. 28 марта 2014 г.. Получено 20 октября 2016.
- ^ Ом, Пол (23 августа 2012). «Не создавайте базу данных разорения». Harvard Business Review.
- ^ Дарвин Бонд-Грэм, Iron Cagebook - логический конец патентов Facebook, Counterpunch.org, 2013.12.03
- ^ Дарвин Бонд-Грэм, Внутри конференции стартапов технологической индустрии, Counterpunch.org, 2013.09.11
- ^ Дарвин Бонд-Грэм, Перспектива больших данных, ThePerspective.com, 2018
- ^ Аль-Родхан, Найеф (16 сентября 2014 г.). «Социальный договор 2.0: большие данные и необходимость гарантировать конфиденциальность и гражданские свободы - Harvard International Review». Гарвардский международный обзор. Архивировано из оригинал 13 апреля 2017 г.. Получено 3 апреля 2017.
- ^ Барокас, Солон; Ниссенбаум, Хелен; Лейн, Юлия; Стодден, Виктория; Бендер, Стефан; Ниссенбаум, Хелен (июнь 2014 г.). Конечная цель больших данных - анонимность и согласие. Издательство Кембриджского университета. С. 44–75. Дои:10.1017 / cbo9781107590205.004. ISBN 9781107067356. S2CID 152939392.
- ^ Лугмайр, Артур; Стоклебен, Бьорн; Шейб, Кристоф; Маилапарампил, Мэтью; Месия, Нура; Ранта, Ханну; Lab, Emmi (1 июня 2016 г.). «КОМПЛЕКСНОЕ ИССЛЕДОВАНИЕ ИССЛЕДОВАНИЯ БОЛЬШИХ ДАННЫХ И ЕГО ПОСЛЕДСТВИЯ - ЧТО ДЕЙСТВИТЕЛЬНО« НОВОГО »В БОЛЬШИХ ДАННЫХ? - ПОЗНАВАТЕЛЬНЫЕ БОЛЬШИЕ ДАННЫЕ!». Цитировать журнал требует
| журнал =(помощь) - ^ Дана Бойд (29 апреля 2010 г.). «Конфиденциальность и гласность в контексте больших данных». Конференция WWW 2010. Получено 18 апреля 2011.
- ^ Катяль, Соня К. (2019). «Искусственный интеллект, реклама и дезинформация». Реклама и общество ежеквартально. 20 (4). Дои:10.1353 / asr.2019.0026. ISSN 2475-1790.
- ^ Джонс, МБ; Шильдхауэр, депутат; Reichman, OJ; Бауэрс, S (2006). «Новая биоинформатика: интеграция экологических данных от гена в биосферу» (PDF). Ежегодный обзор экологии, эволюции и систематики. 37 (1): 519–544. Дои:10.1146 / annurev.ecolsys.37.091305.110031.
- ^ а б Boyd, D .; Кроуфорд, К. (2012). «Критические вопросы для больших данных». Информация, коммуникация и общество. 15 (5): 662–679. Дои:10.1080 / 1369118X.2012.678878. S2CID 51843165.
- ^ Неудача: от больших данных к важным решениям В архиве 6 декабря 2016 г. Wayback Machine, Forte Wares.
- ^ «15 безумных вещей, которые взаимосвязаны друг с другом».
- ^ Случайные структуры и алгоритмы
- ^ Кристиан С. Калуде, Джузеппе Лонго, (2016), Поток ложных корреляций в больших данных, Основы науки
- ^ а б Григорий Пятецкий (12 августа 2014 г.). «Интервью: Майкл Бертольд, основатель KNIME, об исследованиях, творчестве, больших данных и конфиденциальности, часть 2». KDnuggets. Получено 13 августа 2014.
- ^ Пелт, Мейсон (26 октября 2015 г.). ""«Большие данные» - это слово, которое слишком часто используется, и этот Twitter-бот доказывает это.. Siliconangle.com. КремнийУГОЛ. Получено 4 ноября 2015.
- ^ а б Харфорд, Тим (28 марта 2014 г.). «Большие данные: мы делаем большую ошибку?». Financial Times. Получено 7 апреля 2014.
- ^ Иоаннидис JP (Август 2005 г.). «Почему большинство опубликованных результатов исследований ложны». PLOS Медицина. 2 (8): e124. Дои:10.1371 / journal.pmed.0020124. ЧВК 1182327. PMID 16060722.
- ^ Лор, Стив; Певица, Наташа (10 ноября 2016 г.). «Как данные не помогли нам объявить выборы». Нью-Йорк Таймс. ISSN 0362-4331. Получено 27 ноября 2016.
- ^ «Как деятельность полиции на основе данных угрожает свободе человека». Экономист. 4 июня 2018. ISSN 0013-0613. Получено 27 октября 2019.
- ^ Брейн, Сара (29 августа 2017 г.). «Наблюдение за большими данными: пример полицейской деятельности». Американский социологический обзор. 82 (5): 977–1008. Дои:10.1177/0003122417725865. S2CID 3609838.
дальнейшее чтение
| Библиотечные ресурсы о Большое количество данных |
- Питер Киннэрд; Инбал Талгам-Коэн, ред. (2012). "Большое количество данных". Студенческий журнал ACM Crossroads. XRDS: Crossroads, Журнал ACM для студентов. Vol. 19 нет. 1. Ассоциация вычислительной техники. ISSN 1528-4980. OCLC 779657714.
- Юре Лесковец; Ананд Раджараман; Джеффри Д. Уллман (2014). Майнинг массивных наборов данных. Издательство Кембриджского университета. ISBN 9781107077232. OCLC 888463433.
- Виктор Майер-Шёнбергер; Кеннет Кукьер (2013). Большие данные: революция, которая изменит то, как мы живем, работаем и думаем. Houghton Mifflin Harcourt. ISBN 9781299903029. OCLC 828620988.
- Press, Gil (9 мая 2013 г.). «Очень краткая история больших данных». forbes.com. Джерси-Сити, штат Нью-Джерси: Журнал Forbes. Получено 17 сентября 2016.
- «Большие данные: революция в управлении». hbr.org. Harvard Business Review. Октябрь 2012 г.
- О'Нил, Кэти (2017). Оружие разрушения математики: как большие данные увеличивают неравенство и угрожают демократии. Бродвейские книги. ISBN 978-0553418835.
внешняя ссылка
 СМИ, связанные с Большое количество данных в Wikimedia Commons
СМИ, связанные с Большое количество данных в Wikimedia Commons Словарное определение большое количество данных в Викисловарь
Словарное определение большое количество данных в Викисловарь