Анализ данных - Data analysis
| Часть серии по Статистика |
| Визуализация данных |
|---|
Важные цифры |
| Вычислительная физика |
|---|
 |
| Механика · Электромагнетизм · Термодинамика · Моделирование |
Анализ данных это процесс проверки, очищение, преобразование и моделирование данные с целью получения полезной информации, обоснования выводов и поддержки принятия решений. Анализ данных имеет множество аспектов и подходов, охватывающих различные методы под разными названиями, и используется в различных областях бизнеса, науки и социальных наук. В современном деловом мире анализ данных играет роль в принятии более научных решений и помогает предприятиям работать более эффективно.[1]
Сбор данных - это особый метод анализа данных, который фокусируется на статистическом моделировании и открытии знаний для прогнозных, а не чисто описательных целей, в то время как бизнес-аналитика охватывает анализ данных, который в значительной степени опирается на агрегирование, уделяя основное внимание бизнес-информации.[2] В статистических приложениях анализ данных можно разделить на описательная статистика, разведочный анализ данных (EDA) и подтверждающий анализ данных (CDA). EDA фокусируется на обнаружении новых функций в данных, в то время как CDA фокусируется на подтверждении или фальсификации существующих гипотезы. Прогнозная аналитика фокусируется на применении статистических моделей для прогнозирования или классификации, в то время как текстовая аналитика применяет статистические, лингвистические и структурные методы для извлечения и классификации информации из текстовых источников, разновидностей неструктурированные данные. Все вышеперечисленное - разновидности анализа данных.
Интеграция данных является предшественником анализа данных, и анализ данных тесно связан с визуализация данных и распространение данных.[3]
Процесс анализа данных
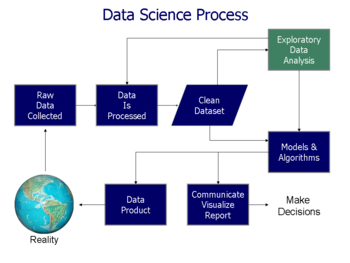
Анализ, относится к разделению целого на отдельные компоненты для индивидуального изучения. Анализ данных, это процесс для получения необработанные данные, а затем преобразовать ее в информацию, полезную для принятия решений пользователями. Данные, собирается и анализируется, чтобы ответить на вопросы, проверить гипотезы или опровергнуть теории.[4]
Статистик Джон Тьюки, определил анализ данных в 1961 году как:
"Процедуры анализа данных, методы интерпретации результатов таких процедур, способы планирования сбора данных, чтобы сделать их анализ более простым, точным или более точным, а также все механизмы и результаты (математической) статистики, которые применяются к анализу данных . "[5]
Можно выделить несколько этапов, описанных ниже. Фазы итеративный, поскольку обратная связь от более поздних этапов может привести к дополнительной работе на более ранних этапах.[6] В Структура CRISP, используется в сбор данных, имеет аналогичные шаги.
Требования к данным
Данные необходимы в качестве входных данных для анализа, который определяется на основе требований тех, кто руководит анализом, или клиентов (которые будут использовать готовый продукт анализа). Общий тип объекта, по которому будут собираться данные, называется экспериментальная установка (например, человек или группа людей). Могут быть указаны и получены конкретные переменные, относящиеся к населению (например, возраст и доход). Данные могут быть числовыми или категориальными (например, текстовая метка для чисел).[6]
Сбор информации
Данные собираются из различных источников. Аналитики могут сообщить о требованиях хранители данных; Такие как, Персонал информационных технологий внутри организации. Данные также могут быть получены с датчиков в окружающей среде, включая камеры трафика, спутники, записывающие устройства и т. Д. Их также можно получить посредством интервью, загрузок из онлайн-источников или чтения документации.[6]
Обработка данных

Данные, изначально полученные, должны быть обработаны или организованы для анализа. Например, они могут включать размещение данных в строках и столбцах в формате таблицы (известный как структурированные данные ) для дальнейшего анализа, часто с использованием электронных таблиц или статистического программного обеспечения.[6]
Очистка данных
После обработки и организации данные могут быть неполными, содержать дубликаты или ошибки. Нужда в очистка данных, возникнет из-за проблем, связанных с вводом и сохранением данных. Очистка данных - это процесс предотвращения и исправления этих ошибок. Общие задачи включают сопоставление записей, определение неточности данных, общее качество существующих данных, дедупликацию и сегментацию столбцов.[7] Такие проблемы с данными также можно выявить с помощью различных аналитических методов. Например, с финансовой информацией, итоговые значения для определенных переменных могут сравниваться с отдельно опубликованными цифрами, которые считаются надежными.[8] Также могут быть рассмотрены необычные суммы, превышающие или ниже заранее определенных пороговых значений. Существует несколько типов очистки данных, которые зависят от типа данных в наборе; это могут быть номера телефонов, адреса электронной почты, работодатели или другие значения. Методы количественных данных для обнаружения выбросов могут использоваться, чтобы избавиться от данных, которые, как представляется, имеют более высокую вероятность неправильного ввода. Средство проверки орфографии текстовых данных может использоваться для уменьшения количества неправильно набранных слов, однако труднее определить, правильны ли сами слова.[9]
Исследовательский анализ данных
После очистки наборов данных их можно проанализировать. Аналитики могут применять различные методы, называемые разведочный анализ данных, чтобы начать понимать сообщения, содержащиеся в полученных данных. Процесс исследования данных может привести к дополнительной очистке данных или дополнительным запросам данных; таким образом, инициализация итерационные фазы упомянутые в начальном абзаце этого раздела. Описательная статистика, например, среднее значение или медиана, могут быть сгенерированы для облегчения понимания данных. Визуализация данных также используется метод, в котором аналитик может исследовать данные в графическом формате, чтобы получить дополнительную информацию о сообщениях в данных.[6]
Моделирование и алгоритмы
Математические формулы или же модели (известный как алгоритмы), может применяться к данным для определения взаимосвязей между переменными; например, используя корреляция или же причинность. В общих чертах, модели могут быть разработаны для оценки конкретной переменной на основе других переменных, содержащихся в наборе данных, с некоторыми остаточная ошибка в зависимости от точности реализованной модели (например, Данные = Модель + Ошибка).[4]
Выведенный статистика, включает использование методов, которые измеряют отношения между конкретными переменными. Например, регрессивный анализ может использоваться для моделирования того, может ли изменение рекламы (независимая переменная X), дает объяснение различий в продажах (зависимая переменная Y). С математической точки зрения, Y (продажи) - это функция Икс (Реклама). Его можно описать как (Y = aX + б + ошибка), где модель построена так, что (а) и нd (), минимизировать ошибку, или когда модель предсказывает Y для данного диапазона значений (f).Икс. Аналитики также могут попытаться построить модели, описывающие данные, с целью упрощения анализа и передачи результатов.[4]
Информационный продукт
А информационный продукт, это компьютерное приложение, которое принимает ввод данных и генерирует выходы, возвращая их в окружающую среду. Он может быть основан на модели или алгоритме. Например, приложение, которое анализирует данные об истории покупок клиента и использует результаты, чтобы рекомендовать другие покупки, которые могут понравиться покупателю.[6]
Коммуникация
После того, как данные проанализированы, они могут быть представлены во многих форматах пользователям анализа для поддержки их требований. Пользователи могут оставлять отзывы, по результатам которых проводится дополнительный анализ. Таким образом, большая часть аналитического цикла является итеративной.[6]
При определении того, как сообщить результаты, аналитик может рассмотреть возможность применения различных методов визуализации данных, чтобы помочь ясно и эффективно донести сообщение до аудитории. Визуализация данных использует информационные дисплеи (графики, такие как таблицы и диаграммы), чтобы помочь передать ключевые сообщения, содержащиеся в данных. Столы являются ценным инструментом, позволяя пользователю запрашивать и сосредотачиваться на конкретных числах; а диаграммы (например, гистограммы или линейные диаграммы) могут помочь объяснить количественные сообщения, содержащиеся в данных.
Количественные сообщения
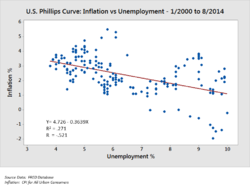
Стивен Фью описал восемь типов количественных сообщений, которые пользователи могут попытаться понять или передать на основе набора данных и связанных графиков, используемых для передачи сообщения. Заказчики, определяющие требования, и аналитики, выполняющие анализ данных, могут рассматривать эти сообщения в ходе процесса.
- Временной ряд: одна переменная фиксируется за определенный период времени, например, уровень безработицы за 10-летний период. А линейный график может использоваться для демонстрации тренда.
- Ранжирование: категориальные подразделения ранжируются в порядке возрастания или убывания, например, рейтинг эффективности продаж ( мера) продавцами ( категория, с каждым продавцом категориальное подразделение) в течение одного периода. А гистограмма может использоваться для сравнения продавцов.
- От части к целому: категориальные подразделения измеряются как отношение к целому (т. Е. Процент от 100%). А круговая диаграмма или гистограмма может отображать сравнение соотношений, таких как рыночная доля, представленная конкурентами на рынке.
- Отклонение: категориальные подразделения сравниваются с эталоном, например, сравнение фактических и бюджетных расходов для нескольких отделов бизнеса за определенный период времени. Гистограмма может показать сравнение фактической суммы с контрольной.
- Частотное распределение: показывает количество наблюдений за определенной переменной для данного интервала, например, количество лет, в течение которых доходность фондового рынка находится между такими интервалами, как 0–10%, 11–20% и т. Д. A гистограмма, тип столбчатой диаграммы, может использоваться для этого анализа.
- Корреляция: сравнение между наблюдениями, представленными двумя переменными (X, Y), чтобы определить, имеют ли они тенденцию двигаться в одном или противоположных направлениях. Например, построение графика безработицы (X) и инфляции (Y) для выборки месяцев. А диаграмма рассеяния обычно используется для этого сообщения.
- Номинальное сравнение: сравнение категорийных подразделений без определенного порядка, например, объем продаж по коду продукта. Для этого сравнения можно использовать гистограмму.
- Географические или геопространственные: сравнение переменной на карте или макете, например, уровень безработицы по штатам или количество людей на разных этажах здания. А картограмма - это типичный графический объект.[11][12]
Методы анализа количественных данных
Автор Джонатан Кумей рекомендовал ряд лучших практик для понимания количественных данных. К ним относятся:
- Перед выполнением анализа проверьте исходные данные на наличие аномалий;
- Повторно выполните важные вычисления, такие как проверка столбцов данных, которые управляются формулами;
- Подтвердите, что основные итоги - это сумма промежуточных итогов;
- Проверьте отношения между числами, которые должны быть связаны предсказуемым образом, например, отношения во времени;
- Нормализовать числа, чтобы упростить сравнения, например, анализировать суммы на человека или относительно ВВП или как значение индекса относительно базового года;
- Разбейте проблемы на составные части, проанализировав факторы, которые привели к результатам, например: Анализ DuPont рентабельности собственного капитала.[8]
Для исследуемых переменных аналитики обычно получают описательная статистика для них, например, среднее (среднее), медиана, и стандартное отклонение. Они также могут анализировать распределение ключевых переменных, чтобы увидеть, как отдельные значения группируются вокруг среднего.

Консультанты в McKinsey и компания назвал метод разделения количественной проблемы на составляющие части, названный Принцип MECE. Каждый слой можно разбить на составляющие; каждый из подкомпонентов должен быть взаимоисключающий друг друга и коллективно добавить к слою над ними. Отношения называются «взаимоисключающими и коллективно исчерпывающими» или MECE. Например, прибыль по определению можно разделить на общий доход и общие затраты. В свою очередь, общий доход можно анализировать по его компонентам, таким как выручка подразделений A, B и C (которые исключают друг друга), и его следует добавлять к общему доходу (совокупно исчерпывающий).
Аналитики могут использовать надежные статистические измерения для решения определенных аналитических задач. Проверка гипотезы используется, когда аналитик делает определенную гипотезу об истинном положении дел и собирает данные, чтобы определить, является ли это положение дел истинным или ложным. Например, гипотеза может заключаться в том, что «Безработица не влияет на инфляцию», что относится к экономической концепции, называемой Кривая Филлипса. Проверка гипотез включает рассмотрение вероятности Ошибки типа I и типа II, которые относятся к тому, поддерживают ли данные принятие или отклонение гипотезы.
Регрессивный анализ может использоваться, когда аналитик пытается определить степень, в которой независимая переменная X влияет на зависимую переменную Y (например, «В какой степени изменения уровня безработицы (X) влияют на уровень инфляции (Y)?»). Это попытка смоделировать или подогнать линию уравнения или кривую к данным, так что Y является функцией X.
Анализ необходимого состояния (NCA) может использоваться, когда аналитик пытается определить степень, в которой независимая переменная X допускает переменную Y (например, «В какой степени определенный уровень безработицы (X) необходим для определенного уровня инфляции (Y)?») . В то время как (множественный) регрессионный анализ использует аддитивную логику, где каждая X-переменная может давать результат, а X могут компенсировать друг друга (они достаточны, но не необходимы), анализ необходимых условий (NCA) использует логику необходимости, где один или несколько X -Переменные позволяют результату существовать, но могут не производить его (они необходимы, но недостаточны). Должны быть выполнены все необходимые условия, компенсация невозможна.
Аналитическая деятельность пользователей данных
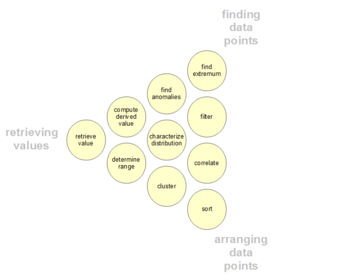
У пользователей могут быть определенные точки интереса в наборе данных, в отличие от общих сообщений, описанных выше. Такие низкоуровневые аналитические действия пользователей представлены в следующей таблице. Таксономия также может быть организована по трем направлениям деятельности: получение значений, поиск точек данных и организация точек данных.[13][14][15][16]
| # | Задача | Общий Описание | Pro Forma Абстрактный | Примеры |
|---|---|---|---|---|
| 1 | Получить значение | Учитывая набор конкретных случаев, найдите атрибуты этих случаев. | Каковы значения атрибутов {X, Y, Z, ...} в случаях данных {A, B, C, ...}? | - Какой пробег на галлон у Ford Mondeo? - Как долго длится фильм «Унесенные ветром»? |
| 2 | Фильтр | Учитывая некоторые конкретные условия для значений атрибутов, найдите случаи данных, удовлетворяющие этим условиям. | Какие варианты данных удовлетворяют условиям {A, B, C ...}? | - Какие злаки Kellogg имеют высокое содержание клетчатки? - Какие комедии удостоены наград? - Какие фонды уступили SP-500? |
| 3 | Вычислить производное значение | Учитывая набор кейсов данных, вычислите агрегированное числовое представление этих кейсов данных. | Каково значение функции агрегирования F для данного набора S случаев данных? | - Какая в среднем калорийность хлопьев Post? - Каков валовой доход всех магазинов вместе взятых? - Сколько сейчас производителей автомобилей? |
| 4 | Найдите экстремум | Найдите в наборе данных кейсы с экстремальным значением атрибута в его диапазоне. | Каковы верхние / нижние N случаев данных по отношению к атрибуту A? | - Какая машина с максимальным расходом топлива? - Какой режиссер / фильм получил больше всего наград? - У какого фильма Marvel Studios самая последняя дата выхода? |
| 5 | Сортировать | Учитывая набор вариантов данных, ранжируйте их по некоторой порядковой метрике. | Каков порядок сортировки набора S наблюдений данных в соответствии с их значением атрибута A? | - Заказ автомобилей по весу. - Оцените крупы по калорийности. |
| 6 | Определить диапазон | Учитывая набор вариантов данных и интересующий атрибут, найдите диапазон значений в наборе. | Каков диапазон значений атрибута A в наборе S случаев данных? | - Какой диапазон длин фильмов? - Какая у машины мощность в лошадиных силах? - Какие актрисы есть в наборе данных? |
| 7 | Охарактеризуйте распространение | Учитывая набор случаев данных и интересующий количественный атрибут, охарактеризуйте распределение значений этого атрибута по набору. | Каково распределение значений атрибута A в наборе S случаев данных? | - Каково распределение углеводов в крупах? - Каков возрастной состав покупателей? |
| 8 | Найдите аномалии | Идентифицируйте любые аномалии в заданном наборе случаев данных в отношении заданных отношений или ожиданий, например статистические выбросы. | Какие кейсы данных в наборе S кейсов данных имеют неожиданные / исключительные значения? | - Есть ли исключения из отношения между мощностью и ускорением? - Есть ли выбросы в белке? |
| 9 | Кластер | Для набора вариантов данных найдите кластеры с похожими значениями атрибутов. | Какие варианты данных в наборе S вариантов данных аналогичны по значению для атрибутов {X, Y, Z, ...}? | - Существуют ли группы злаков с одинаковым содержанием жира / калорий / сахара? - Есть ли кластер типичной длины пленки? |
| 10 | Соотносить | Учитывая набор случаев данных и два атрибута, определите полезные отношения между значениями этих атрибутов. | Какова корреляция между атрибутами X и Y для данного набора S случаев данных? | - Есть ли корреляция между углеводами и жирами? - Есть ли корреляция между страной происхождения и MPG? - Есть ли у разных полов предпочтительный способ оплаты? - Есть ли тенденция увеличения продолжительности фильмов с годами? |
| 11 | Контекстуализация[16] | Учитывая набор случаев данных, найдите контекстную релевантность данных для пользователей. | Какие кейсы данных в наборе S кейсов данных имеют отношение к контексту текущего пользователя? | - Существуют ли группы ресторанов, в которых есть продукты, основанные на моем текущем потреблении калорий? |
Препятствия на пути к эффективному анализу
Препятствия на пути к эффективному анализу могут существовать среди аналитиков, выполняющих анализ данных, или среди аудитории. Отличить факты от мнения, когнитивные предубеждения и неумелость - все это проблемы для надежного анализа данных.
Сбивающие с толку факт и мнение
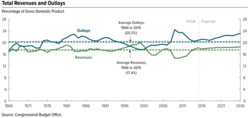
Эффективный анализ требует получения соответствующих факты ответить на вопросы, поддержать заключение или формально мнение, или тест гипотезы. Факты по определению неопровержимы, а это означает, что любой человек, участвующий в анализе, должен иметь возможность согласиться с ними. Например, в августе 2010 г. Бюджетное управление Конгресса (CBO) подсчитала, что расширение Снижение налогов Бушем в 2001 и 2003 годах на период 2011–2020 годов добавит к государственному долгу примерно 3,3 триллиона долларов.[17] Каждый должен быть в состоянии согласиться с тем, что именно об этом сообщила CBO; они все могут изучить отчет. Это факт. Согласны или не согласны люди с CBO - их собственное мнение.
Другой пример: аудитор публичной компании должен прийти к официальному мнению о том, является ли финансовая отчетность публично торгуемых корпораций «достоверной во всех существенных отношениях». Это требует обширного анализа фактических данных и доказательств, подтверждающих их мнение. При переходе от фактов к мнениям всегда существует вероятность того, что мнение ошибочный.
Когнитивные предубеждения
Есть множество когнитивные предубеждения что может отрицательно повлиять на анализ. Например, Подтверждение смещения это тенденция искать или интерпретировать информацию таким образом, чтобы подтвердить свои предубеждения. Кроме того, люди могут дискредитировать информацию, не подтверждающую их взгляды.
Аналитики могут быть специально обучены тому, чтобы знать об этих предубеждениях и способах их преодоления. В его книге Психология анализа интеллекта, бывший аналитик ЦРУ Ричардс Хойер написали, что аналитики должны четко очерчивать свои предположения и цепочки умозаключений и указывать степень и источник неопределенности, связанной с выводами. Он сделал упор на процедуры, помогающие выявить и обсудить альтернативные точки зрения.[18]
Безграмотность
Эффективные аналитики, как правило, владеют множеством численных методов. Однако аудитория может не обладать такой грамотностью с числами или умение считать; их называют бесчисленными. Лица, передающие данные, также могут пытаться ввести в заблуждение или дезинформировать, умышленно используя неверные числовые методы.[19]
Например, рост или падение числа может не быть ключевым фактором. Более важным может быть число относительно другого числа, например, размер государственных доходов или расходов относительно размера экономики (ВВП) или сумма затрат относительно доходов в корпоративной финансовой отчетности. Этот численный метод называется нормализацией[8] или обычного размера. Аналитики используют множество таких методов, будь то поправка на инфляцию (то есть сравнение реальных и номинальных данных) или с учетом прироста населения, демографии и т. Д. Аналитики применяют различные методы для обработки различных количественных сообщений, описанных в разделе выше.
Аналитики также могут анализировать данные при различных предположениях или сценариях. Например, когда аналитики выполняют анализ финансовой отчетности, они часто изменяют финансовую отчетность с учетом других допущений, чтобы помочь получить оценку будущего денежного потока, который затем дисконтируют до приведенной стоимости на основе некоторой процентной ставки, чтобы определить оценку компании или ее акций. Точно так же CBO анализирует влияние различных вариантов политики на доходы, расходы и дефицит правительства, создавая альтернативные сценарии будущего для ключевых мер.
Другие темы
Умные здания
Подход с аналитикой данных можно использовать для прогнозирования энергопотребления в зданиях.[20] Различные этапы процесса анализа данных выполняются для реализации интеллектуальных зданий, где операции по управлению и контролю здания, включая отопление, вентиляцию, кондиционирование, освещение и безопасность, выполняются автоматически, имитируя потребности пользователей здания и оптимизируя ресурсы. как энергия и время.
Аналитика и бизнес-аналитика
Аналитика - это «широкое использование данных, статистического и количественного анализа, пояснительных и прогнозных моделей и управления на основе фактов для принятия решений и действий». Это подмножество бизнес-аналитика, который представляет собой набор технологий и процессов, использующих данные для понимания и анализа эффективности бизнеса.[21]
Образование
В образование, большинство преподавателей имеют доступ к система данных с целью анализа данных о студентах.[22] Эти системы данных предоставляют данные преподавателям в внебиржевые данные формат (вложение этикеток, дополнительная документация и справочная система, а также принятие ключевых решений по упаковке / отображению и содержанию) для повышения точности анализа данных преподавателями.[23]
Заметки для практикующих
Этот раздел содержит довольно технические объяснения, которые могут помочь практикам, но выходят за рамки типичной статьи в Википедии.
Анализ исходных данных
Наиболее важное различие между этапом анализа исходных данных и этапом основного анализа заключается в том, что во время анализа исходных данных человек воздерживается от любого анализа, который направлен на ответ на исходный вопрос исследования. На этапе анализа исходных данных руководствуются следующими четырьмя вопросами:[24]
Качество данных
Качество данных следует проверять как можно раньше. Качество данных можно оценить несколькими способами, используя различные типы анализа: подсчет частоты, описательная статистика (среднее, стандартное отклонение, медиана), нормальность (асимметрия, эксцесс, частотные гистограммы), n: переменные сравниваются со схемами кодирования внешних переменных. к набору данных и, возможно, исправлены, если схемы кодирования не сопоставимы.
- Тест на дисперсия обычного метода.
Выбор анализов для оценки качества данных на этапе первоначального анализа данных зависит от анализа, который будет проводиться на этапе основного анализа.[25]
Качество измерений
Качество измерительные приборы следует проверять только на этапе первоначального анализа данных, когда это не является предметом внимания или исследовательским вопросом исследования. Следует проверить, соответствует ли структура средств измерений структуре, указанной в литературе.
Есть два способа оценить измерение: [ПРИМЕЧАНИЕ: кажется, что указан только один способ]
- Анализ однородности (Внутренняя согласованность ), что указывает на надежность измерительного прибора. Во время этого анализа проверяются отклонения позиций и весов, Кронбаха α шкал, и изменение альфы Кронбаха, когда элемент будет удален из шкалы[26]
Начальные преобразования
После оценки качества данных и измерений можно принять решение о вменении недостающих данных или о выполнении начальных преобразований одной или нескольких переменных, хотя это также можно сделать на этапе основного анализа.[27]
Возможные преобразования переменных:[28]
- Преобразование квадратного корня (если распределение умеренно отличается от нормального)
- Лог-преобразование (если распределение существенно отличается от нормального)
- Обратное преобразование (если распределение сильно отличается от нормального)
- Сделать категориальным (порядковым / дихотомическим) (если распределение сильно отличается от нормального и никакие преобразования не помогают)
Соответствует ли выполнение исследования целям дизайна исследования?
Следует проверить успешность рандомизация процедура, например, путем проверки того, одинаково ли распределены фоновые и существенные переменные внутри и между группами.
Если в исследовании не требовалось или не использовалась процедура рандомизации, следует проверить успешность неслучайной выборки, например, проверив, все ли подгруппы представляющей интерес совокупности представлены в выборке.
Другие возможные искажения данных, которые следует проверить:
- выбывать (это должно быть определено на этапе первоначального анализа данных)
- Элемент отсутствие ответа (является ли это случайным или нет, следует оценить на этапе анализа исходных данных)
- Качество лечения (использование проверки на манипуляции ).[29]
Характеристики выборки данных
В любом отчете или статье структура выборки должна быть точно описана. Особенно важно точно определить структуру выборки (и особенно размер подгрупп), когда анализ подгрупп будет выполняться на этапе основного анализа.
Характеристики выборки данных можно оценить, посмотрев на:
- Базовая статистика важных переменных
- Диаграммы разброса
- Корреляции и ассоциации
- Перекрестные таблицы[30]
Завершающий этап анализа исходных данных
На заключительном этапе результаты анализа исходных данных документируются, и принимаются необходимые, предпочтительные и возможные корректирующие действия.
Кроме того, исходный план анализа основных данных можно и нужно уточнить или переписать.
Для этого можно и нужно принять несколько решений относительно анализа основных данных:
- В случае не-нормали: следует преобразовать переменные; сделать переменные категориальными (порядковыми / дихотомическими); адаптировать метод анализа?
- В случае отсутствующие данные: следует пренебречь или вменять недостающие данные; какой метод вменения следует использовать?
- В случае выбросы: следует ли использовать надежные методы анализа?
- В случае, если элементы не соответствуют масштабу: следует ли адаптировать измерительный инструмент, исключив элементы, или, скорее, обеспечить сопоставимость с другими (видами использования) измерительным инструментом (ами)?
- В случае (слишком) малых подгрупп: следует ли отказаться от гипотезы о межгрупповых различиях или использовать методы малых выборок, такие как точные тесты или самонастройка ?
- В случае если рандомизация процедура кажется неполноценной: можно и нужно рассчитывать оценка предрасположенности и включить их как ковариаты в основной анализ?[31]
Анализ
На этапе анализа исходных данных можно использовать несколько анализов:[32]
- Одномерная статистика (одна переменная)
- Двумерные ассоциации (корреляции)
- Графические методы (точечные диаграммы)
При анализе важно учитывать уровни измерения переменных, поскольку для каждого уровня доступны специальные статистические методы:[33]
- Номинальные и порядковые переменные
- Подсчет частоты (числа и проценты)
- Ассоциации
- обходы (кросс-таблицы)
- иерархический логлинейный анализ (до 8 переменных)
- логлинейный анализ (для определения релевантных / важных переменных и возможных искажающих факторов)
- Точные тесты или бутстреппинг (в случае небольших подгрупп)
- Вычисление новых переменных
- Непрерывные переменные
- Распределение
- Статистика (M, SD, дисперсия, асимметрия, эксцесс)
- Стволовые и листовые дисплеи
- Коробчатые диаграммы
- Распределение
Нелинейный анализ
Нелинейный анализ часто необходим, когда данные записываются с нелинейная система. Нелинейные системы могут проявлять сложные динамические эффекты, включая бифуркации, хаос, гармоники и субгармоники которые нельзя проанализировать простыми линейными методами. Нелинейный анализ данных тесно связан с идентификация нелинейных систем.[34]
Анализ основных данных
На этапе основного анализа выполняется анализ, направленный на ответ на вопрос исследования, а также любой другой соответствующий анализ, необходимый для написания первого проекта отчета об исследовании.[35]
Исследовательский и подтверждающий подходы
На этапе основного анализа может быть использован исследовательский или подтверждающий подход. Обычно подход определяется до сбора данных. В исследовательском анализе перед анализом данных не формулируется четкая гипотеза, и в данных ведется поиск моделей, которые хорошо описывают данные. В подтверждающем анализе проверяются четкие гипотезы о данных.
Исследовательский анализ данных следует толковать осторожно. При одновременном тестировании нескольких моделей высока вероятность того, что хотя бы одна из них будет значимой, но это может быть связано с ошибка 1 типа. Очень важно всегда корректировать уровень значимости при тестировании нескольких моделей, например, с помощью Коррекция Бонферрони. Кроме того, не следует сопровождать исследовательский анализ подтверждающим анализом того же набора данных. Исследовательский анализ используется для поиска идей для теории, но не для проверки этой теории. Когда в наборе данных обнаруживается исследовательская модель, то продолжение этого анализа подтверждающим анализом в том же наборе данных может просто означать, что результаты подтверждающего анализа обусловлены одним и тем же. ошибка 1 типа что привело в первую очередь к исследовательской модели. Таким образом, подтверждающий анализ не будет более информативным, чем исходный исследовательский анализ.[36]
Стабильность результатов
Важно получить некоторое представление о том, насколько обобщаемы результаты.[37] Хотя это часто бывает трудно проверить, можно посмотреть на стабильность результатов. Являются ли результаты надежными и воспроизводимыми? Есть два основных способа сделать это.
- Перекрестная проверка. Разделив данные на несколько частей, мы можем проверить, распространяется ли анализ (например, подобранная модель) на основе одной части данных на другую часть данных. Однако перекрестная проверка обычно неуместна, если в данных есть корреляции, например с данные панели. Следовательно, иногда необходимо использовать другие методы проверки. Для получения дополнительной информации по этой теме см. проверка статистической модели.
- Анализ чувствительности. Процедура для изучения поведения системы или модели при (систематическом) изменении глобальных параметров. Один из способов сделать это - через самонастройка.
Бесплатное программное обеспечение для анализа данных
Среди известных бесплатных программ для анализа данных:
- DevInfo - Система баз данных, одобренная Группа развития ООН для мониторинга и анализа человеческого развития.
- ELKI - Среда интеллектуального анализа данных на Java с функциями визуализации, ориентированными на интеллектуальный анализ данных.
- KNIME - Konstanz Information Miner, удобный и комплексный фреймворк для анализа данных.
- апельсин - Инструмент визуального программирования с интерактивная визуализация данных и методы статистического анализа данных, сбор данных, и машинное обучение.
- Панды - Библиотека Python для анализа данных.
- Лапа - Фреймворк для анализа данных FORTRAN / C, разработанный в ЦЕРН.
- р - Язык программирования и программная среда для статистических вычислений и графики.
- КОРЕНЬ - Фреймворк для анализа данных C ++, разработанный в ЦЕРН.
- SciPy - Библиотека Python для анализа данных.
- Анализ данных - Библиотека .NET для анализа и преобразования данных.
- Юля - Язык программирования, хорошо подходящий для численного анализа и вычислений.
Международные конкурсы анализа данных
Различные компании или организации проводят конкурсы по анализу данных, чтобы побудить исследователей использовать свои данные или решить конкретный вопрос с помощью анализа данных. Вот несколько примеров хорошо известных международных конкурсов по анализу данных.
Смотрите также
- Актуарная наука
- Аналитика
- Большое количество данных
- Бизнес-аналитика
- Цензура (статистика)
- Вычислительная физика
- Получение данных
- Смешивание данных
- Управление данными
- Сбор данных
- Архитектура представления данных
- Наука о данных
- Цифровая обработка сигналов
- Уменьшение размеров
- Ранняя оценка случая
- Исследовательский анализ данных
- Анализ Фурье
- Машинное обучение
- Мультилинейный PCA
- Мультилинейное подпространственное обучение
- Многосторонний анализ данных
- Поиск ближайшего соседа
- Идентификация нелинейной системы
- Прогнозная аналитика
- Анализ главных компонентов
- Качественное исследование
- Научные вычисления
- Анализ структурированных данных (статистика)
- Идентификация системы
- Метод испытания
- Текстовая аналитика
- Неструктурированные данные
- Вейвлет
- Список компаний, занимающихся большими данными
Рекомендации
Цитаты
- ^ Ся, Б. С., и Гонг, П. (2015). Обзор бизнес-аналитики посредством анализа данных. Сравнительный анализ, 21(2), 300-311. DOI: 10.1108 / BIJ-08-2012-0050
- ^ Изучение анализа данных
- ^ Шерман, Рик (4 ноября 2014 г.). Руководство по бизнес-аналитике: от интеграции данных к аналитике. Амстердам. ISBN 978-0-12-411528-6. OCLC 894555128.
- ^ а б c Джадд, Чарльз и Макклеланд, Гэри (1989). Анализ данных. Харкорт Брейс Йованович. ISBN 0-15-516765-0.
- ^ Джон Тьюки - будущее анализа данных - июль 1961 г.
- ^ а б c d е ж грамм Шутт, Рэйчел; О'Нил, Кэти (2013). Заниматься наукой о данных. O'Reilly Media. ISBN 978-1-449-35865-5.
- ^ «Очистка данных». Microsoft Research. Получено 26 октября 2013.
- ^ а б c Perceptual Edge - Джонатан Куми - Лучшие практики понимания количественных данных - 14 февраля 2006 г.
- ^ Хеллерштейн, Джозеф (27 февраля 2008 г.). «Количественная очистка данных для больших баз данных» (PDF). Отдел компьютерных наук EECS: 3. Получено 26 октября 2013.
- ^ Гранджан, Мартин (2014). "La connaissance est un réseau" (PDF). Les Cahiers du Numérique. 10 (3): 37–54. Дои:10.3166 / lcn.10.3.37-54.
- ^ Стивен Фью-Perceptual Edge-Выбор правильного графика для вашего сообщения-2004
- ^ Стивен Фью-Перцепционная матрица выбора граничного графа
- ^ Роберт Амар, Джеймс Иган и Джон Стаско (2005) «Низкоуровневые компоненты аналитической деятельности в визуализации информации»
- ^ Уильям Ньюман (1994) «Предварительный анализ результатов исследований HCI с использованием аннотаций Pro Forma»
- ^ Мэри Шоу (2002) «Что дает хорошие исследования в области разработки программного обеспечения?»
- ^ а б «ConTaaS: подход к контекстуализации в масштабе Интернета для разработки эффективных приложений Интернета вещей». ScholarSpace. HICSS50. Получено 24 мая, 2017.
- ^ «Бюджетное управление Конгресса - Бюджет и экономические перспективы - август 2010 - Таблица 1.7 на стр. 24» (PDF). Получено 2011-03-31.
- ^ "Вступление". cia.gov.
- ^ Bloomberg-Barry Ritholz-Bad Math that Passes for Insight-28 октября 2014 г.
- ^ Гонсалес-Видаль, Аврора; Морено-Кано, Виктория (2016). «На пути к энергоэффективным моделям умных зданий на основе интеллектуальной аналитики данных». Процедуры информатики. 83 (Elsevier): 994–999. Дои:10.1016 / j.procs.2016.04.213.
- ^ Давенпорт, Томас и Харрис, Жанна (2007). Конкуренция в Google Analytics. О'Рейли. ISBN 978-1-4221-0332-6.
- ^ Ааронс, Д. (2009). Отчет находит состояния на курсе для создания систем данных об учениках. Неделя образования, 29(13), 6.
- ^ Ранкин Дж. (28 марта 2013 г.). Как системы данных и отчеты могут бороться или распространять эпидемию ошибок анализа данных и как руководители учебных заведений могут помочь. Презентация проведена на Саммите школы лидерства Технологического информационного центра административного лидерства (TICAL).
- ^ Adèr 2008a, п. 337.
- ^ Adèr 2008a, стр. 338-341.
- ^ Adèr 2008a, стр. 341-342.
- ^ Adèr 2008a, п. 344.
- ^ Табачник и Фиделл, 2007, стр. 87-88.
- ^ Adèr 2008a, стр. 344-345.
- ^ Adèr 2008a, п. 345.
- ^ Adèr 2008a, стр. 345-346.
- ^ Adèr 2008a, стр. 346-347.
- ^ Adèr 2008a, стр. 349-353.
- ^ Биллингс С.А. "Нелинейная идентификация систем: методы NARMAX во временной, частотной и пространственно-временной областях". Вайли, 2013
- ^ Адер 2008b, п. 363.
- ^ Адер 2008b, стр. 361-362.
- ^ Адер 2008b С. 361-371.
- ^ «Сообщество машинного обучения берет верх над Хиггсом». Журнал Симметрия. 15 июля 2014 г.. Получено 14 января 2015.
- ^ Нехме, Жан (29 сентября 2016 г.). «Международный конкурс анализа данных LTPP». Федеральное управление автомобильных дорог. Получено 22 октября, 2017.
- ^ "Data.Gov: Long-Term Pavement Performance (LTPP)". 26 мая, 2016. Получено 10 ноября, 2017.
Библиография
- Адер, Герман Дж. (2008a). «Глава 14: Этапы и начальные шаги в анализе данных». В Adèr, Herman J .; Мелленберг, Гидеон Дж.; Рука, Дэвид Дж (ред.). Консультации по методам исследования: товарищ консультанта. Хейзен, Нидерланды: Паб Йоханнес ван Кессель. С. 333–356. ISBN 9789079418015. OCLC 905799857.CS1 maint: ref = harv (связь)
- Адер, Герман Дж. (2008b). «Глава 15: Основная фаза анализа». В Adèr, Herman J .; Мелленберг, Гидеон Дж.; Рука, Дэвид Дж (ред.). Консультации по методам исследования: товарищ консультанта. Хейзен, Нидерланды: Паб Йоханнес ван Кессель. С. 357–386. ISBN 9789079418015. OCLC 905799857.CS1 maint: ref = harv (связь)
- Табачник, Б. И Фиделл, Л. (2007). Глава 4: Приведение в порядок своего выступления. Данные скрининга перед анализом. В B.G. Табачник и Л. Фиделл (ред.), Использование многомерной статистики, пятое издание (стр. 60–116). Бостон: Pearson Education, Inc. / Аллин и Бэкон.
дальнейшее чтение
- Адер, Х.Дж. & Мелленберг, Г.Дж. (при участии Д.Дж. Хэнда) (2008). Консультации по методам исследования: помощник консультанта. Huizen, Нидерланды: Johannes van Kessel Publishing.
- Чемберс, Джон М .; Кливленд, Уильям С .; Кляйнер, Бит; Тьюки, Пол А. (1983). Графические методы анализа данных, Wadsworth / Duxbury Press. ISBN 0-534-98052-X
- Фанданго, Армандо (2008). Анализ данных Python, 2-е издание. Издательство Packt.
- Джуран, Джозеф М .; Годфри, А. Блэнтон (1999). Справочник Джурана по качеству, 5-е издание. Нью-Йорк: Макгроу Хилл. ISBN 0-07-034003-X
- Льюис-Бек, Майкл С. (1995). Анализ данных: введение, Sage Publications Inc, ISBN 0-8039-5772-6
- NIST / SEMATECH (2008) Справочник по статистическим методам,
- Пыздек, Т. (2003). Справочник по качеству, ISBN 0-8247-4614-7
- Ричард Верьярд (1984). Прагматический анализ данных. Оксфорд: Научные публикации Блэквелла. ISBN 0-632-01311-7
- Табачник, Б.Г .; Фидель, Л. (2007). Использование многомерной статистики, 5-е издание. Бостон: Pearson Education, Inc. / Аллин и Бэкон, ISBN 978-0-205-45938-4