Преобразование данных (статистика) - Data transformation (statistics)
Эта статья поднимает множество проблем. Пожалуйста помоги Улучши это или обсудите эти вопросы на страница обсуждения. (Узнайте, как и когда удалить эти сообщения-шаблоны) (Узнайте, как и когда удалить этот шаблон сообщения)
|
В статистика, данные трансформация это приложение детерминированный математический функция к каждой точке в данные набор - то есть каждая точка данных zя заменяется преобразованным значением уя = ж(zя), куда ж это функция. Преобразования обычно применяются для того, чтобы данные более точно соответствовали предположениям статистические выводы процедуры, которая должна быть применена, или для улучшения интерпретируемости или внешнего вида графики.
Почти всегда функция, которая используется для преобразования данных, обратимый, и обычно непрерывный. Преобразование обычно применяется к набору сопоставимых измерений. Например, если мы работаем с данными о доходах людей в некоторых валюта единицы, обычно значение дохода каждого человека преобразуется на логарифм функция.
Мотивация
Рекомендации относительно того, как данные должны быть преобразованы, или следует ли вообще применять преобразование, должны исходить из конкретного статистического анализа, который необходимо выполнить. Например, простой способ построить приблизительно 95% доверительный интервал для населения означает взять выборочное среднее плюс-минус два стандартная ошибка единицы. Однако постоянный коэффициент 2, используемый здесь, специфичен для нормальное распределение, и применимо только в том случае, если выборочное среднее варьируется приблизительно нормально. В Центральная предельная теорема заявляет, что во многих ситуациях среднее значение выборки обычно меняется, если размер выборки достаточно велик. Однако если численность населения существенно перекошенный и размер выборки самый умеренный, приближение, обеспечиваемое центральной предельной теоремой, может быть плохим, и результирующий доверительный интервал, вероятно, будет иметь неверный вероятность покрытия. Таким образом, когда есть свидетельства существенного перекоса в данных, их обычно преобразуют в симметричный распределение[1] перед построением доверительного интервала. При желании доверительный интервал можно затем преобразовать обратно к исходному масштабу, используя преобразование, обратное преобразованию, которое было применено к данным.[2][3]
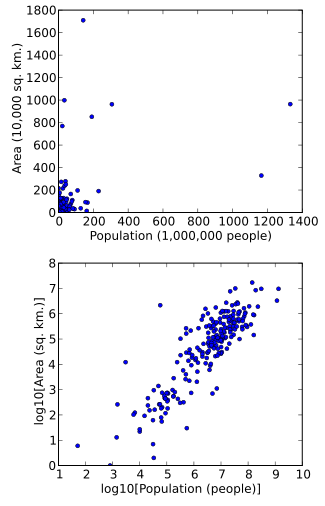
Данные также можно преобразовать, чтобы упростить их визуализацию. Например, предположим, что у нас есть диаграмма рассеяния, на которой точки - это страны мира, а отображаемые значения данных - это площадь суши и население каждой страны. Если график строится с использованием нетрансформированных данных (например, квадратных километров для площади и количества людей для населения), большинство стран будут отображены в виде плотной группы точек в нижнем левом углу графика. Несколько стран с очень большими территориями и / или населением будут рассредоточены по большей части площади графика. Простое изменение масштаба единиц (например, до тысяч квадратных километров или миллионов людей) этого не изменит. Однако после логарифмический трансформации как площади, так и населения, точки будут более равномерно распределены на графике.
Другой причиной применения преобразования данных является улучшение интерпретируемости, даже если формальный статистический анализ или визуализация не требуется. Например, предположим, что мы сравниваем автомобили с точки зрения их экономии топлива. Эти данные обычно представлены в виде «километров на литр» или «миль на галлон». Однако, если цель состоит в том, чтобы оценить, сколько дополнительного топлива человек использовал бы в течение одного года при управлении одним автомобилем по сравнению с другим, более естественно работать с данными, преобразованными с помощью взаимная функция, давая литры на километр или галлоны на милю.
В регрессе
Преобразование данных можно использовать в качестве корректирующей меры, чтобы сделать данные пригодными для моделирования с помощью линейная регрессия если исходные данные нарушают одно или несколько предположений линейной регрессии.[4] Например, простейшие модели линейной регрессии предполагают линейный отношения между ожидаемое значение из Y (в переменная ответа быть предсказанным) и каждый независимая переменная (когда другие независимые переменные остаются неизменными). Если линейность не соблюдается даже приблизительно, иногда можно преобразовать независимые или зависимые переменные в регрессионной модели для улучшения линейности.[5] Например, добавление квадратичных функций исходных независимых переменных может привести к линейной зависимости от ожидаемое значение из Y, в результате полиномиальная регрессия модель, частный случай линейной регрессии.
Еще одно предположение линейной регрессии: гомоскедастичность, это отклонение из ошибки должны быть одинаковыми независимо от значений предикторов. Если это предположение нарушается (т.е. если данные гетероскедастический ), возможно, удастся найти преобразование Y в одиночку или трансформации обоих Икс (в переменные-предикторы ) и Y, такое, что предположение гомоскедастичности (в дополнение к предположению линейности) выполняется для преобразованных переменных[5] поэтому к ним может применяться линейная регрессия.
Еще одно применение преобразования данных - решение проблемы отсутствия нормальность в терминах ошибок. Одномерная нормальность не требуется для наименьших квадратов оценки параметров регрессии, чтобы быть значимыми (см. Теорема Гаусса – Маркова ). Однако доверительные интервалы и проверка гипотез будут иметь лучшие статистические свойства, если переменные демонстрируют многомерная нормальность. Преобразования, которые стабилизируют дисперсию терминов ошибки (т. Е. Те, которые направлены на гетероскедатичность), часто также помогают сделать термины ошибки приблизительно нормальными.[5][6]
Примеры
Уравнение:

- Смысл: Увеличение X на единицу связано с увеличением Y в среднем на b единиц.
Уравнение: (Из возведения в степень обе части уравнения: )


- Смысл: Единичное увеличение X связано со средним увеличением на b единиц в , или, что то же самое, Y увеличивается в среднем на мультипликативный коэффициент . В иллюстративных целях, если логарифм по основанию 10 использовались вместо натуральный логарифм в приведенном выше преобразовании и те же символы (а и б) используются для обозначения коэффициентов регрессии, то увеличение X на единицу приведет к в среднем увеличивается Y раз. Если бы b было 1, то это означает 10-кратное увеличение Y для увеличения X на единицу.



Уравнение:

- Смысл: Увеличение X в k раз связано со средним значением единиц увеличиваются в Y. В иллюстративных целях, если логарифм по основанию 10 использовались вместо натуральный логарифм в приведенном выше преобразовании и те же символы (а и б) используются для обозначения коэффициентов регрессии, то десятикратное увеличение X приведет к среднему увеличению единиц в Y


Уравнение: (Из возведения в степень обе части уравнения: )


- Смысл: Увеличение X в k раз связано с мультипликативное увеличение Y в среднем. Таким образом, если X удвоится, это приведет к изменению Y на мультипликативный коэффициент .[7]


Альтернатива
Обобщенные линейные модели (GLM) обеспечивают гибкое обобщение обычной линейной регрессии, которое позволяет использовать переменные отклика, которые имеют модели распределения ошибок, отличные от нормального распределения. GLM позволяют связать линейную модель с переменной отклика через функцию связи и позволяют величине дисперсии каждого измерения быть функцией его предсказанного значения.[8][9]
Общие случаи
В логарифм и квадратный корень преобразования обычно используются для положительных данных, а мультипликативный обратный (обратное) преобразование может использоваться для ненулевых данных. В преобразование власти представляет собой семейство преобразований, параметризованных неотрицательным значением λ, которое включает в себя логарифм, квадратный корень и мультипликативную обратную величину как особые случаи. Чтобы подойти к преобразованию данных систематически, можно использовать статистическая оценка методы для оценки параметра λ в преобразовании мощности, тем самым идентифицируя преобразование, которое является приблизительно наиболее подходящим в данной настройке. Поскольку семейство степенных преобразований также включает в себя преобразование идентичности, этот подход также может указать, лучше ли анализировать данные без преобразования. В регрессионном анализе этот подход известен как Техника Бокса – Кокса.
Взаимное преобразование, некоторые преобразования мощности, такие как преобразование Йео-Джонсона, и некоторые другие преобразования, такие как применение обратный гиперболический синус, может быть осмысленно применен к данным, которые включают как положительные, так и отрицательные значения.[10] (преобразование степени обратимо для всех действительных чисел, если λ - нечетное целое число). Однако, когда наблюдаются как отрицательные, так и положительные значения, иногда обычно начинают с добавления константы ко всем значениям, создавая набор неотрицательных данных, к которым может быть применено любое преобразование мощности.[3]
Типичная ситуация, когда применяется преобразование данных, - это когда интересующее значение колеблется в нескольких порядки величины. Многие физические и социальные явления демонстрируют такое поведение - доходы, популяции видов, размеры галактик и количество осадков, и это лишь некоторые из них. Преобразования мощности, в частности логарифм, часто можно использовать для создания симметрии в таких данных. Часто отдают предпочтение логарифму, потому что его результат легко интерпретировать в терминах «кратных изменений».
Логарифм также оказывает полезное влияние на отношения. Если мы сравниваем положительные величины Икс и Y используя соотношение Икс / Y, то если Икс < Y, отношение находится в интервале (0,1), тогда как если Икс > Y, отношение находится в полупрямой (1, ∞), где отношение 1 соответствует равенству. В анализе, где Икс и Y обрабатываются симметрично, log-ratio log (Икс / Y) равен нулю в случае равенства и обладает тем свойством, что если Икс является K раз больше, чем Y, логарифм является равноудаленным от нуля, как в ситуации, когда Y является K раз больше, чем Икс (логарифмические отношения являются логарифмическими (K) и −log (K) в этих двух ситуациях).
Если значения естественным образом ограничены диапазоном от 0 до 1, не включая конечные точки, тогда преобразование логита может быть подходящим: это дает значения в диапазоне (−∞, ∞).
Превращение в нормальность
1. Не всегда необходимо или желательно преобразовывать набор данных, чтобы он напоминал нормальное распределение. Однако, если требуется симметрия или нормальность, их часто можно вызвать с помощью одного из степенных преобразований;
2. Лингвистическая степенная функция распределяется согласно Закон Ципфа-Мандельброта. Распределение чрезвычайно резкое и лептокуртика, по этой причине исследователям пришлось отказаться от статистики, чтобы решить, например, присуждение авторства проблемы. Тем не менее, использование гауссовой статистики вполне возможно при применении преобразования данных.[11]
3. Чтобы оценить, была ли достигнута нормальность после преобразования, любой из стандартных тесты на нормальность может быть использовано. Графический подход обычно более информативен, чем формальный статистический тест, и, следовательно, нормальный квантильный график обычно используется для оценки соответствия набора данных нормальной совокупности. В качестве альтернативы, практические правила на основе выборки перекос и эксцесс также были предложены.[12][13]
Переход к равномерному или произвольному распределению
Если мы наблюдаем набор п значения Икс1, ..., Иксп без связи (т.е. есть п различные значения), мы можем заменить Икся с преобразованным значением Yя = k, куда k определяется так, что Икся это kth самый большой среди всех Икс значения. Это называется преобразование ранга,[14] и создает данные, идеально подходящие для равномерное распределение. Этот подход имеет численность населения аналог.
С использованием интегральное преобразование вероятности, если Икс есть ли случайная переменная, и F это кумулятивная функция распределения из Икс, то пока F обратима, случайная величина U = F(Икс) следует равномерному распределению на единичный интервал [0,1].
От равномерного распределения мы можем перейти к любому распределению с обратимой кумулятивной функцией распределения. Если грамм - обратимая кумулятивная функция распределения, и U является равномерно распределенной случайной величиной, то случайная величина грамм−1(U) имеет грамм как его кумулятивная функция распределения.
Соединяя их вместе, если Икс любая случайная величина, F - обратимая кумулятивная функция распределения Икс, и грамм - обратимая кумулятивная функция распределения, то случайная величина грамм−1(F(Икс)) имеет грамм как его кумулятивная функция распределения.
Преобразования, стабилизирующие дисперсию
Многие типы статистических данных показывают "отклонение -среднее отношение ", что означает, что изменчивость различна для значений данных с разными ожидаемые значения. Например, при сравнении различных групп населения в мире разница в доходе имеет тенденцию увеличиваться со средним доходом. Если мы рассмотрим несколько небольших территориальных единиц (например, округа в США) и получим среднее значение и дисперсию доходов в каждом округе, то обычно округа с более высоким средним доходом также имеют более высокие отклонения.
А преобразование, стабилизирующее дисперсию направлена на устранение зависимости отклонения от среднего, чтобы дисперсия стала постоянной по отношению к среднему. Примерами преобразований, стабилизирующих дисперсию, являются Преобразование фишера для выборочного коэффициента корреляции квадратный корень преобразование или Преобразование Анскомба за Пуассон данные (данные подсчета), Преобразование Бокса – Кокса для регрессионного анализа, а преобразование квадратного корня арксинуса или угловое преобразование для пропорций (биномиальный данные). Хотя обычно используется для статистического анализа пропорциональных данных, преобразование квадратного корня арксинуса не рекомендуется, поскольку логистическая регрессия или преобразование логита более подходят для биномиальных или небиномиальных пропорций соответственно, особенно из-за уменьшения ошибка типа II.[15][3]
Преобразования для многомерных данных
Одномерные функции могут применяться точечно к многомерным данным для изменения их предельных распределений. Также можно изменить некоторые атрибуты многомерного распределения, используя правильно построенное преобразование. Например, при работе с Временные ряды и другие типы последовательных данных, обычно разница данные для улучшения стационарность. Если данные генерируются случайным вектором Икс наблюдаются как векторы Икся наблюдений с ковариационная матрица Σ, а линейное преобразование может использоваться для декорреляции данных. Для этого Разложение Холецкого используется для выражения Σ = А А '. Тогда преобразованный вектор Yя = А−1Икся имеет единичная матрица как его ковариационная матрица.
Смотрите также
- Arcsin
- Разработка функций
- Logit
- Нелинейная регрессия # Преобразование
- Коэффициент корреляции Пирсона
- Преобразование мощности (Бокс – Кокс)
Рекомендации
- ^ Кун, Макс; Джонсон, Кьелл (2013). Прикладное прогнозное моделирование. Нью-Йорк. Дои:10.1007/978-1-4614-6849-3. ISBN 9781461468493. LCCN 2013933452. OCLC 844349710. S2CID 60246745.
- ^ Альтман, Дуглас Дж .; Блэнд, Дж. Мартин (1996-04-27). «Статистические заметки: преобразования, средние значения и доверительные интервалы». BMJ. 312 (7038): 1079. Дои:10.1136 / bmj.312.7038.1079. ISSN 0959-8138. ЧВК 2350916. PMID 8616417.
- ^ а б c «Преобразования данных - Справочник по биологической статистике». www.biostathandbook.com. Получено 2019-03-19.
- ^ «Урок 9: Преобразование данных | STAT 501». newonlinecourses.science.psu.edu. Получено 2019-03-17.
- ^ а б c Катнер, Майкл Х .; Nachtsheim, Christopher J .; Нетер, Джон; Ли, Уильям (2005). Прикладные линейные статистические модели (5-е изд.). Бостон: Макгроу-Хилл Ирвин. стр.129 –133. ISBN 0072386886. LCCN 2004052447. OCLC 55502728.
- ^ Альтман, Дуглас Дж .; Блэнд, Дж. Мартин (1996-03-23). «Статистические заметки: преобразование данных». BMJ. 312 (7033): 770. Дои:10.1136 / bmj.312.7033.770. ISSN 0959-8138. ЧВК 2350481. PMID 8605469.
- ^ «9.3 - Лог-преобразование предсказателя и ответа | STAT 501». newonlinecourses.science.psu.edu. Получено 2019-03-17.
- ^ Тернер, Хизер (2008). «Введение в обобщенные линейные модели» (PDF).
- ^ Ло, Стесон; Эндрюс, Салли (2015-08-07). «Преобразовывать или не преобразовывать: использование обобщенных линейных смешанных моделей для анализа данных о времени реакции». Границы в психологии. 6: 1171. Дои:10.3389 / fpsyg.2015.01171. ISSN 1664-1078. ЧВК 4528092. PMID 26300841.
- ^ «Преобразования: введение». fmwww.bc.edu. Получено 2019-03-19.
- ^ Ван Дроогенброк Ф.Дж., 'Существенная перефразировка закона Ципфа-Мандельброта для решения приложений атрибуции авторства с помощью гауссовой статистики' (2019) [1]
- ^ Ким, Хэ Ён (01.02.2013). «Статистические заметки для клинических исследователей: оценка нормального распределения (2) с использованием асимметрии и эксцесса». Восстановительная стоматология и эндодонтия. 38 (1): 52–54. Дои:10.5395 / rde.2013.38.1.52. ISSN 2234-7658. ЧВК 3591587. PMID 23495371.
- ^ «Проверка нормальности, включая асимметрию и эксцесс». imaging.mrc-cbu.cam.ac.uk. Получено 2019-03-18.
- ^ «Новый взгляд на статистику: непараметрические модели: преобразование рангов». www.sportsci.org. Получено 2019-03-23.
- ^ Warton, D .; Хуэй, Ф. (2011). «Арксинус глуп: анализ пропорций в экологии». Экология. 92 (1): 3–10. Дои:10.1890/10-0340.1. HDL:1885/152287. PMID 21560670.
внешняя ссылка
- Преобразования журналов для искаженных и широких распределений - обсуждение журнала и преобразований «логарифма со знаком» (глава из «Практическая наука о данных с R»).