Нейрокомпьютерная обработка речи - Neurocomputational speech processing
Нейрокомпьютерная обработка речи компьютерное моделирование производство речи и восприятие речи ссылаясь на естественные нейронные процессы производство речи и восприятие речи, как они встречаются в человеческом нервная система (Центральная нервная система и периферическая нервная система ). Эта тема основана на нейробиология и вычислительная нейробиология.[1]
Обзор
Нейровычислительные модели обработки речи сложны. Они составляют не менее познавательная часть, а моторная часть и сенсорная часть.
Когнитивная или лингвистическая часть нейровычислительной модели обработки речи включает нейронную активацию или генерацию фонематическое представление на стороне производство речи (например, нейровычислительная и расширенная версия модели Levelt, разработанная Арди Рулофсом:[2] ТКАЧ ++[3] а также нейронная активация или генерация намерения или значения на стороне восприятие речи или же понимание речи.
В моторная часть нейровычислительной модели обработки речи начинается с фонематическое представление речевого элемента, активирует двигательный план и заканчивается артикуляция этого конкретного речевого элемента (см. также: артикуляционная фонетика ).
В сенсорная часть нейровычислительной модели обработки речи начинается с акустического сигнала речевого элемента (акустический речевой сигнал ), порождает слуховое представление для этого сигнала и активирует фонематические представления для этого речевого элемента.
Темы нейрокомпьютерной обработки речи
Нейрокомпьютерная обработка речи - это обработка речи искусственные нейронные сети. Нейронные карты, сопоставления и пути, описанные ниже, являются модельными структурами, то есть важными структурами в искусственных нейронных сетях.
Нейронные карты
Искусственная нейронная сеть может быть разделена на три типа нейронных карт, также называемых «слоями»:
- входные карты (в случае обработки речи: первичная слуховая карта в пределах слуховая кора, первичная соматосенсорная карта в соматосенсорная кора ),
- выходные карты (первичная моторная карта в первичной моторная кора ), и
- кортикальные карты более высокого уровня (также называемые «скрытыми слоями»).
Термин «нейронная карта» предпочтительнее термина «нейронный слой», потому что кортиальная нейронная карта должна быть смоделирована как 2D-карта взаимосвязанных нейронов (например, как самоорганизующаяся карта; см. также рис. 1). Таким образом, каждый «модельный нейрон» или «искусственный нейрон "на этой 2D-карте физиологически представлена кортикальный столб так как кора головного мозга анатомически имеет слоистую структуру.
Нейронные представления (нейронные состояния)
Нейронное представление внутри искусственная нейронная сеть - это временно активированное (нейронное) состояние на определенной нейронной карте. Каждое нервное состояние представлено определенным паттерном нейронной активации. Этот образец активации изменяется во время обработки речи (например, от слога к слогу).

В модели ACT (см. Ниже) предполагается, что слуховое состояние может быть представлено "нервной системой". спектрограмма "(см. рис. 2) на карте слухового состояния. Предполагается, что эта карта слухового состояния расположена в коре слуховых ассоциаций (см. кора головного мозга ).
Соматосенсорное состояние можно разделить на тактильный и проприоцептивное состояние и может быть представлен конкретным паттерном нейронной активации на карте соматосенсорного состояния. Предполагается, что эта карта состояний расположена в коре соматосенсорных ассоциаций (см. кора головного мозга, соматосенсорная система, соматосенсорная кора ).
Состояние двигательного плана можно предположить для представления двигательного плана, то есть планирования речевой артикуляции для определенного слога или для более длинного речевого элемента (например, слова, короткой фразы). Предполагается, что эта карта состояний расположена в премоторная кора, в то время как мгновенная (или более низкий уровень) активация каждого речевого артикулятора происходит в пределах первичная моторная кора (видеть моторная кора ).
Нейронные репрезентации, встречающиеся на сенсорных и моторных картах (как было введено выше), являются распределенными репрезентациями (Hinton et al. 1968[4]): Каждый нейрон на сенсорной или моторной карте более или менее активирован, что приводит к определенному паттерну активации.
Нейронное представление речевых единиц, встречающихся в звуковой карте речи (см. Ниже: модель DIVA), является точечным или локальным представлением. Каждый речевой элемент или речевая единица здесь представлены определенным нейрон (модель ячейки, см. ниже).
Нейронные отображения (синаптические проекции)

Нейронная карта соединяет две корковые нейронные карты. Нейронные сопоставления (в отличие от нейронных путей) хранят обучающую информацию, изменяя веса их нейронных связей (см. искусственный нейрон, искусственные нейронные сети ). Нейронные сопоставления способны генерировать или активировать распределенное представление (см. Выше) сенсорного или моторного состояния на сенсорной или моторной карте из точечной или локальной активации в пределах другой карты (см., Например, синаптическую проекцию от звуковой карты речи на моторную). map, на карту слуховой целевой области или на карту соматосенсорной целевой области в модели DIVA, как описано ниже; или посмотрите, например, нейронное отображение из фонетической карты в карту слухового состояния и карту состояния моторного плана в модели ACT, как описано ниже и на рис. . 3).
Нейронные карты между двумя нейронными картами бывают компактными или плотными: каждый нейрон одной нейронной карты связан (почти) с каждым нейроном другой нейронной карты (связь многие-ко-многим, см. искусственные нейронные сети ). Из-за этого критерия плотности для нейронных отображений нейронные карты, которые связаны между собой нейронным отображением, находятся недалеко друг от друга.
Нервные пути
В отличие от нейронных отображений нервные пути может соединять нейронные карты, которые находятся далеко друг от друга (например, в разных долях коры, см. кора головного мозга ). С функциональной точки зрения или точки зрения моделирования нейронные пути в основном передают информацию, не обрабатывая эту информацию. Нейронный путь по сравнению с нейронным картированием требует гораздо меньше нейронных связей. Нейронный путь можно смоделировать, используя взаимно однозначное соединение нейронов обеих нейронных карт (см. топографическая карта и увидеть соматотопическое расположение ).
Пример: в случае двух нейронных карт, каждая из которых содержит 1000 модельных нейронов, для нейронного сопоставления требуется до 1000000 нейронных соединений (соединение многие-ко-многим), тогда как в случае соединения нейронного пути требуется только 1000 соединений.
Кроме того, веса связей в нейронном отображении корректируются во время обучения, в то время как нейронные связи в случае нейронного пути не нужно обучать (каждое соединение является максимально показательным).
DIVA модель
Ведущим подходом в нейровычислительном моделировании речевого производства является модель DIVA, разработанная Франк Х. Гюнтер и его группа в Бостонском университете.[5][6][7][8] Модель учитывает широкий диапазон фонетический и нейровизуализация данные, но - как и каждая нейровычислительная модель - в некоторой степени остается спекулятивным.
Структура модели

Организация или структура модели DIVA показана на рисунке 4.
Звуковая карта речи: фонематическая репрезентация как отправная точка
Звуковая карта речи - предполагается, что она расположена в нижней и задней части Площадь Брока (левая лобная крышка) - представляет (фонологически уточненные) языковые речевые единицы (звуки, слоги, слова, короткие фразы). Каждая речевая единица (в основном слоги; например, слог и слово «ладонь» / pam /, слоги / pa /, / ta /, / ka /, ...) представлена определенной модельной ячейкой в звуковой карте речи ( то есть точечные нейронные репрезентации, см. выше). Каждая модельная ячейка (см. искусственный нейрон ) соответствует небольшой группе нейронов, которые расположены на близком расстоянии и срабатывают вместе.
Управление с прогнозированием: активация моторных представлений
Каждый нейрон (модельная клетка, искусственный нейрон ) в звуковой карте речи может быть активирован и впоследствии активирует команду движения вперед по направлению к карте мотора, называемую картой артикуляционной скорости и положения. Активированное нейронное представление на уровне этой моторной карты определяет артикуляцию речевой единицы, то есть управляет всеми артикуляторами (губами, языком, велумом, голосовой щелью) в течение временного интервала для создания этой речевой единицы. Прямой контроль также включает подкорковые структуры, такие как мозжечок, здесь не моделируется подробно.
Речь единица измерения представляет собой количество речи Предметы которые могут быть отнесены к той же фонематической категории. Таким образом, каждая речевая единица представлена одним конкретным нейроном в звуковой карте речи, в то время как реализация речевой единицы может демонстрировать некоторую артикуляционную и акустическую изменчивость. Эта фонетическая изменчивость является мотивацией для определения сенсорной цели. регионы в модели DIVA (см. Guenther et al. 1998[9]).
Артикуляторная модель: генерирование соматосенсорной и слуховой обратной связи
Паттерн активации в моторной карте определяет паттерн движения всех модельных артикуляторов (губ, языка, велума, голосовой щели) для речевого элемента. Чтобы не перегружать модель, детальное моделирование нервно-мышечная система готово. В Синтезатор артикуляционной речи Maeda используется для создания движений артикулятора, что позволяет генерировать изменяющиеся во времени форма голосового тракта и поколение акустический речевой сигнал для каждой конкретной речи.
С точки зрения искусственный интеллект артикуляционную модель можно назвать растительной (т.е. системой, которой управляет мозг); он представляет собой часть воплощение нейронной системы обработки речи. Артикуляционная модель порождает сенсорный выход который является основой для генерации информации обратной связи для модели DIVA (см. ниже: управление обратной связью).
Управление обратной связью: сенсорные целевые области, карты состояний и карты ошибок
С одной стороны, артикуляторная модель порождает сенсорная информация, то есть слуховое состояние для каждой речевой единицы, которое нейронно представлено в карте слухового состояния (распределенное представление), и соматосенсорное состояние для каждой речевой единицы, которое нейронно представлено в карте соматосенсорного состояния (также распределенное представление). Предполагается, что карта слухового состояния расположена в верхняя височная кора в то время как карта соматосенсорного состояния, как предполагается, находится в нижняя теменная кора.
С другой стороны, звуковая карта речи, если она активирована для конкретной речевой единицы (активация одного нейрона; точечная активация), активирует сенсорную информацию посредством синаптических проекций между звуковой картой речи и слуховой картой целевой области, а также между звуковой картой речи и соматосенсорной целевой областью. карта. Предполагается, что слуховые и соматосенсорные целевые области расположены в слуховые области коры высшего порядка И в соматосенсорные области коры высшего порядка соответственно. Эти модели сенсорной активации целевой области - которые существуют для каждой речевой единицы - изучаются во время приобретение речи (путем имитационного обучения; см. ниже: обучение).
Следовательно, доступны два типа сенсорной информации, если речевой блок активирован на уровне звуковой карты речи: (i) изученные сенсорные целевые области (т.е. предназначены сенсорное состояние для речевой единицы) и (ii) паттерны активации сенсорного состояния в результате возможно несовершенного исполнения (артикуляции) конкретной речевой единицы (т. е. Текущий сенсорное состояние, отражающее текущее производство и артикуляцию этой конкретной речевой единицы). Оба типа сенсорной информации проецируются на карты сенсорных ошибок, то есть на карту слуховых ошибок, которая, как предполагается, находится в верхняя височная кора (как карта слухового состояния) и карта соматосенсорной ошибки, которая предположительно находится в нижняя теменная кора (как карта соматосенсорного состояния) (см. рис. 4).
Если текущее сенсорное состояние отклоняется от намеченного сенсорного состояния, обе карты ошибок генерируют команды обратной связи, которые проецируются на моторную карту и способны корректировать паттерн моторной активации и, следовательно, артикуляцию воспроизводимой речевой единицы. Таким образом, в целом на паттерн активации моторной карты влияет не только конкретная команда прямой связи, изученная для речевого блока (и генерируемая синаптической проекцией из звуковой карты речи), но также и команда обратной связи, генерируемая на уровне карты сенсорных ошибок (см. рис. 4).
Обучение (моделирование приобретения речи)
В то время как структура нейробиологической модели обработки речи (приведенной на рис. 4 для модели DIVA) в основном определяется эволюционные процессы, (зависит от языка) знание а также (зависит от языка) разговорный навык изучаются и обучаются во время приобретение речи. В случае модели DIVA предполагается, что новорожденный не имеет уже структурированной (зависящей от языка) звуковой карты речи; то есть ни один нейрон в звуковой карте речи не связан с какой-либо речевой единицей. Скорее организация звуковой карты речи, а также настройка проекций на моторную карту и на сенсорные карты целевой области изучаются или обучаются во время приобретения речи. В подходе DIVA моделируются две важные фазы раннего овладения речью: лепет и по подражание.
Лепет
В течение лепет настраиваются синаптические проекции между картами сенсорных ошибок и моторными картами. Это обучение выполняется путем генерации количества полуслучайных команд с прямой связью, то есть модель DIVA «лепет». Каждая из этих команд лепетания приводит к созданию «артикуляционного элемента», также обозначаемого как «долингвистический (т.е. не зависящий от языка) речевой элемент» (то есть артикуляционная модель генерирует модель артикуляционных движений на основе моторики лепета. команда). После этого раздается акустический сигнал.
На основе артикуляционного и акустического сигнала активируется определенный паттерн слухового и соматосенсорного состояния на уровне карт сенсорных состояний (см. Рис. 4) для каждого (предлингвистического) речевого элемента. На данный момент модель DIVA имеет доступный сенсорный и связанный паттерн моторной активации для различных речевых элементов, что позволяет модели настраивать синаптические проекции между сенсорной картой ошибок и моторной картой. Таким образом, во время лепета модель DIVA изучает команды обратной связи (т. Е. Как произвести правильную (обратную) моторную команду для определенного сенсорного ввода).
Имитация
В течение подражание Модель DIVA организует свою звуковую карту речи и настраивает синаптические проекции между звуковой картой речи и моторной картой, т. е. настройкой прямых двигательных команд, а также синаптические проекции между звуковой картой речи и сенсорными целевыми областями (см. рис. 4). Имитационное обучение выполняется путем воздействия на модель определенного количества акустических речевых сигналов, представляющих реализации языковых речевых единиц (например, отдельные звуки речи, слоги, слова, короткие фразы).
Настройка синаптических проекций между звуковой картой речи и картой слуховой целевой области выполняется путем присвоения одного нейрона звуковой карты речи фонематическому представлению этого речевого элемента и путем связывания его со слуховым представлением этого речевого элемента, который активируется. на карте слуховой целевой области. Слуховой регионы (т. элемент и речь единица измерения см. выше: управление с прогнозированием).
Настройка синаптических проекций между звуковой картой речи и моторной картой (т. Е. Настройка прямых моторных команд) выполняется с помощью команд обратной связи, так как проекции между сенсорной картой ошибок и моторной картой уже были настроены во время обучения лепету (см. Выше) . Таким образом, модель DIVA пытается «имитировать» элемент слуховой речи, пытаясь найти правильную двигательную команду с прямой связью. Затем модель сравнивает полученный сенсорный выход (Текущий сенсорное состояние после артикуляции этой попытки) с уже изученной слуховой целевой областью (предназначены сенсорное состояние) для этого речевого элемента. Затем модель обновляет текущую команду двигателя с прямой связью с помощью команды двигателя с обратной связью по току, сгенерированной из карты слуховых ошибок системы слуховой обратной связи. Этот процесс может повторяться несколько раз (несколько попыток). Модель DIVA способна производить речевой элемент с уменьшающейся слуховой разницей между текущим и предполагаемым слуховым состоянием от попытки до попытки.
Во время имитации модель DIVA также способна настраивать синаптические проекции из звуковой карты речи на карту соматосенсорной целевой области, поскольку каждая новая попытка имитации производит новую артикуляцию речевого элемента и, таким образом, производит соматосенсорный паттерн состояния, связанный с фонематическим представлением этого речевого элемента.
Возмущающие эксперименты
Возмущение F1 в реальном времени: влияние слуховой обратной связи
Хотя слуховая обратная связь наиболее важна во время получения речи, она может быть активирована меньше, если модель выучила правильную команду двигателя с прямой связью для каждой речевой единицы. Но было показано, что слуховая обратная связь должна сильно коактивироваться в случае слухового возмущения (например, сдвиг частоты формант, Tourville et al. 2005).[10] Это сопоставимо с сильным влиянием визуальной обратной связи на достижение движений во время визуального возмущения (например, изменение местоположения объектов путем просмотра через призма ).
Неожиданная блокировка челюсти: влияние соматосенсорной обратной связи
Подобно слуховой обратной связи, соматосенсорная обратная связь также может сильно коактивироваться во время производства речи, например в случае неожиданной блокировки челюсти (Tourville et al. 2005).
Модель ACT
Еще одним подходом к нейровычислительному моделированию обработки речи является модель ACT, разработанная Бернд Дж. Крёгер и его группа[11] в RWTH Ахенский университет, Германия (Kröger et al.2014,[12] Kröger et al. 2009 г.,[13] Kröger et al. 2011 г.[14]). Модель ACT по большей части соответствует модели DIVA. Модель ACT фокусируется на "действие репозиторий "(т.е. хранилище за сенсомоторные разговорные навыки, сравнимо с ментальной слоговой, см. Levelt and Wheeldon 1994[15]), которая не прописана подробно в модели DIVA. Более того, модель ACT явно вводит уровень планы мотора, т.е. высокоуровневое моторное описание для производства речевых элементов (см. двигательные цели, моторная кора ). Модель ACT, как и любая нейровычислительная модель, до некоторой степени остается спекулятивной.
Структура
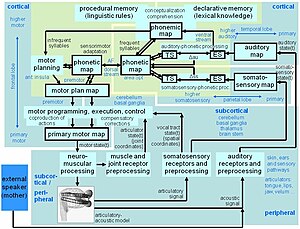
Организация или структура модели ACT представлена на рисунке 5.
За производство речи, модель ACT начинается с активации фонематическое представление речевого элемента (фонематическая карта). В случае частый слог, коактивация происходит на уровне фонетическая карта, что приводит к дальнейшей совместной активации предполагаемого сенсорного состояния на уровне карты сенсорных состояний и к совместной активации состояние плана двигателя на уровне карты плана движения. В случае нечастый слог, попытка план двигателя генерируется модулем моторного планирования для этого речевого элемента путем активации моторных планов для фонетически аналогичных речевых элементов через фонетическую карту (см. Kröger et al. 2011[16]). В план двигателя или оценка действий голосового тракта включает временно перекрывающиеся действия голосового тракта, которые программируются и впоследствии выполняются модуль программирования, исполнения и управления двигателем. Этот модуль в режиме реального времени получает информацию соматосенсорной обратной связи для контроля правильного выполнения (предполагаемого) двигательного плана. Моторное программирование приводит к паттерну активации на уровне l основная моторная карта и впоследствии активирует нервно-мышечная обработка. Паттерны активации мотонейронов генерировать мышечные силы и, следовательно, модели движения всех модельные артикуляторы (губы, язык, велум, голосовая щель). В Артикуляционный синтезатор Birkholz 3D используется для создания акустический речевой сигнал.
Артикуляционный и акустический сигналы обратной связи используются для генерации соматосенсорный и информация слуховой обратной связи через сенсорные модули предварительной обработки, которая направляется на слуховую и соматосенсорную карту. На уровне модулей сенсорно-фонетической обработки слуховая и соматосенсорная информация хранится в краткосрочная память а внешний сенсорный сигнал (ES, рис. 5, который активируется через петлю сенсорной обратной связи) можно сравнить с уже обученными сенсорными сигналами (TS, рис. 5, которые активируются через фонетическую карту). Сигналы слуховой и соматосенсорной ошибки могут быть сгенерированы, если внешние и намеченные (обученные) сенсорные сигналы заметно отличаются (см. Модель DIVA).
Светло-зеленая область на рис. 5 указывает те нейронные карты и модули обработки, которые обрабатывают слог как единое целое (конкретное временное окно обработки около 100 мс и более). Эта обработка включает в себя фонетическую карту и напрямую связанные карты сенсорных состояний в сенсорно-фонетических модулях обработки и напрямую связанную карту состояний моторного плана, в то время как первичная моторная карта, а также (первичная) слуховая и (первичная) соматосенсорная карта обрабатываются меньше. временные окна (около 10 мс в модели ACT).

Гипотетический корковое расположение нейронных карт в модели ACT показано на рис. 6. Гипотетические местоположения первичных моторных и первичных сенсорных карт показаны пурпурным цветом, гипотетические местоположения карты состояния моторного плана и карт сенсорного состояния (в модуле сенсорно-фонетической обработки сопоставимы к картам ошибок в DIVA) выделены оранжевым цветом, а гипотетические местоположения зеркальный фонетическая карта выделена красным цветом. Двойные стрелки указывают нейронные сопоставления. Нейронные отображения соединяют нейронные карты, которые находятся недалеко друг от друга (см. Выше). Два зеркальный Места на фонетической карте связаны нейронным путем (см. выше), что приводит к (простому) однозначному зеркальному отражению текущего паттерна активации для обеих реализаций фонетической карты. Предполагается, что этот нейронный путь между двумя точками фонетической карты является частью fasciculus arcuatus (AF, см. Рис. 5 и рис. 6).
За восприятие речи, модель запускается с внешнего акустического сигнала (например, из внешнего динамика). Этот сигнал предварительно обрабатывается, проходит слуховую карту и приводит к паттерну активации для каждого слога или слова на уровне модуля слухофонетической обработки (ES: внешний сигнал, см. Рис. 5). Вентральный путь восприятия речи (см. Hickok, Poeppel 2007[17]) напрямую активирует лексический элемент, но не реализован в ACT. Скорее, в ACT активация фонематического состояния происходит через фонематическую карту и, таким образом, может привести к коактивации моторных представлений для этого речевого элемента (то есть дорсального пути восприятия речи; там же).
Хранилище действий

Фонетическая карта вместе с картой состояний моторного плана, картами сенсорных состояний (происходящих в модулях сенсорно-фонетической обработки) и фонематической (государственной) картой образуют репозиторий действий. Фонетическая карта реализована в ACT как самоорганизующаяся нейронная карта и разные речевые элементы представлены разными нейронами на этой карте (точечное или локальное представление, см. выше: нейронные представления). Фонетическая карта имеет три основных характеристики:
- Больше одного фонетическая реализация может встречаться в фонетической карте для одного фонематическое состояние (см. веса фонематических ссылок на рис. 7: например, слог / de: m / представлен тремя нейронами на фонетической карте)
- Фонетотопия: Фонетическая карта показывает порядок речевых элементов в зависимости от фонетические особенности (см. веса фонематических связей на рис. 7. Три примера: (i) слоги / p @ /, / t @ / и / k @ / расположены в восходящем порядке слева в пределах фонетической карты; (ii) слогово-начальные взрывные слова встречаются в верхней левой части фонетической карты, в то время как начальные фрикативные слоги встречаются в нижней правой половине; (iii) слоги CV и слоги CVC также встречаются в разных областях фонетической карты).
- Фонетическая карта гипермодальная или мультимодальный: Активация фонетического элемента на уровне фонетической карты коактивирует (i) фонематическое состояние (см. Веса фонематических связей на рис.7), (ii) состояние моторного плана (см. Веса связей моторного плана на рис.7) , (iii) слуховое состояние (см. веса слуховых звеньев на рис. 7) и (iv) соматосенсорное состояние (не показано на рис. 7). Все эти состояния изучаются или обучаются во время овладения речью путем настройки весовых коэффициентов синаптических связей между каждым нейроном в фонетической карте, представляющей конкретное фонетическое состояние и все нейроны в соответствующем двигательном плане и картах сенсорных состояний (см. Также рис.
Фонетическая карта реализует действие-восприятие-ссылка в модели ACT (см. также рис. 5 и рис. 6: двойное нейронное представление фонетической карты в лобная доля и на пересечении височная доля и теменная доля ).
Моторные планы
Двигательный план - это моторное описание высокого уровня для производства и артикуляции речевых элементов (см. двигательные цели, двигательные навыки, артикуляционная фонетика, артикуляционная фонология ). В нашей нейровычислительной модели ACT двигательный план количественно определяется как оценка активности голосового тракта. Оценки действий голосового тракта количественно определяют количество действий голосового тракта (также называемых артикуляционными жестами), которые необходимо активировать, чтобы произвести речевой элемент, их степень реализации и продолжительность, а также временную организацию всех действий голосового тракта. речевой элемент (подробное описание оценок действий голосового тракта см., например, в Kröger & Birkholz 2007).[18] Детальная реализация каждого действия речевого тракта (артикуляционный жест) зависит от временной организации всех действий речевого тракта, составляющих речевой элемент, и особенно от их временного перекрытия. Таким образом, детальная реализация каждого действия речевого тракта в речевом элементе определена ниже уровня моторного плана в нашей нейровычислительной модели ACT (см. Kröger et al. 2011).[19]
Интеграция сенсомоторных и когнитивных аспектов: сочетание репозитория действий и ментальной лексики
Серьезная проблема фонетических или сенсомоторных моделей обработки речи (таких как DIVA или ACT) заключается в том, что развитие фонематическая карта во время набора речи не моделируется. Возможным решением этой проблемы может быть прямое соединение репозитория действий и ментального лексикона без явного введения фонематической карты в начале усвоения речи (даже в начале обучения имитации; см. Kröger et al., 2011 PALADYN Journal of Behavioral Robotics) .
Эксперименты: приобретение речи
Очень важным вопросом для всех нейробиологических или нейрокомпьютерных подходов является разделение структуры и знания. В то время как структура модели (т.е. нейронной сети человека, которая необходима для обработки речи) в основном определяется эволюционные процессы, знания собираются в основном во время приобретение речи процессами учусь. Были проведены различные обучающие эксперименты с моделью ACT, чтобы изучить (i) систему из пяти гласных / i, e, a, o, u / (см. Kröger et al. 2009), (ii) небольшую систему согласных ( звонкие взрывные / b, d, g / в сочетании со всеми пятью гласными, приобретенными ранее как слоги CV (там же), (iii) небольшой модельный язык, включающий систему из пяти гласных, звонкие и глухие взрывные / b, d, g, p, t, k /, носовые / m, n / и латеральные / l / и три слога (V, CV и CCV) (см. Kröger et al.2011)[20] и (iv) 200 наиболее часто употребляемых слогов стандартного немецкого языка для 6-летнего ребенка (см. Kröger et al. 2011).[21] Во всех случаях можно наблюдать упорядочение фонетических элементов по различным фонетическим признакам.
Эксперименты: восприятие речи
Несмотря на то, что модель ACT в своих более ранних версиях была разработана как модель чисто речевого производства (включая приобретение речи), модель способна отображать важные основные явления восприятия речи, то есть категориальное восприятие и эффект Мак-Гурка. В случае категоричное восприятие, модель может показать, что категориальное восприятие сильнее в случае взрывных звуков, чем в случае гласных (см. Kröger et al. 2009). Кроме того, модель ACT смогла продемонстрировать Эффект МакГерка, если был реализован специфический механизм ингибирования нейронов уровня фонетической карты (см. Kröger, Kannampuzha 2008).[22]
Смотрите также
- Производство речи
- Восприятие речи
- Вычислительная нейробиология
- Артикуляционный синтез
- Звуковая обратная связь
Рекомендации
- ^ Rouat J, Loiselle S, Pichevar R (2007) К нейровычислительной обработке речи и звука. В: Sytylianou Y, Faundez-Zanuy M, Esposito A. Прогресс в обработке нелинейной речи (Springer, Берлин) стр. 58-77. ACMDL
- ^ "Арди Рулофс". Архивировано из оригинал на 2012-04-26. Получено 2011-12-08.
- ^ ТКАЧ ++
- ^ Хинтон Г.Е., Макклелланд Дж. Л., Румелхарт Д. Е. (1968) Распределенные представления. В: Rumelhart DE, McClelland JL (ред.). Параллельная распределенная обработка: исследования микроструктуры познания. Том 1: Основы (MIT Press, Кембридж, Массачусетс)
- ^ Модель DIVA: модель производства речи с упором на процессы управления с обратной связью, разработанная Франк Х. Гюнтер и его группа в Бостонском университете, Массачусетс, США. Термин «DIVA» относится к «Направлениям скоростей артикуляторов».
- ^ Guenther, F.H., Ghosh, S.S., Tourville, J.A. (2006) pdf В архиве 2012-04-15 в Wayback Machine. Нейронное моделирование и визуализация корковых взаимодействий, лежащих в основе производства слогов. Мозг и язык, 96, с. 280–301
- ^ Guenther FH (2006) Корковое взаимодействие, лежащее в основе производства звуков речи. Журнал коммуникативных расстройств 39, 350–365
- ^ Гюнтер, Ф.Х., Перкелл, Дж. (2004) pdf В архиве 2012-04-15 в Wayback Machine. Нейронная модель речевого производства и ее применение к изучению роли слуховой обратной связи в речи. В: Б. Маассен, Р. Кент, Х. Петерс, П. Ван Лисхаут и В. Хулстейн (ред.), Управление речевой моторикой при нормальной и нарушенной речи (стр. 29–49). Оксфорд: Издательство Оксфордского университета
- ^ Гюнтер, Ф.Х., Хэмпсон, М., Джонсон, Д. (1998) Теоретическое исследование систем отсчета для планирования речевых движений. Психологический обзор 105: 611-633
- ^ Tourville J, Guenther F, Ghosh S, Reilly K, Bohland J, Nieto-Castanon A (2005) Влияние акустических и артикуляционных возмущений на корковую активность во время производства речи. Плакат 11-го ежегодного собрания Организации по картированию мозга человека (Торонто, Канада)
- ^ Модель ACT: модель производства, восприятия и усвоения речи, разработанная Бернд Й. Крёгер и его группа в RWTH Ахенском университете, Германия. Термин «ACT» относится к термину «ACTion».
- ^ Б. Дж. Крёгер, Дж. Каннампужа, Э. Кауфманн (2014) pdf Ассоциативное обучение и самоорганизация как основные принципы моделирования овладения речью, производства речи и восприятия речи. EPJ Нелинейная биомедицинская физика 2 (1), 1-28
- ^ Kröger BJ, Kannampuzha J, Neuschaefer-Rube C (2009) pdf К нейровычислительной модели производства и восприятия речи. Речевое общение 51: 793-809
- ^ Kröger BJ, Birkholz P, Neuschaefer-Rube C (2011) К подходу развивающей робототехники, основанному на артикуляции, для обработки текста при личном общении. ПАЛАДИН Журнал поведенческой робототехники 2: 82-93. DOI
- ^ Левелт, У.Дж.М., Уилдон, Л. (1994) Имеют ли говорящие доступ к умственной слоговой речи? Познание 50, 239–269
- ^ Kröger BJ, Miller N, Lowit A, Neuschaefer-Rube C. (2011) Defective neural motor speech mappings as a source for apraxia of speech: Evidence from a quantitative neural model of speech processing. In: Lowit A, Kent R (eds.) Assessment of Motor Speech Disorders. (Plural Publishing, San Diego, CA) pp. 325-346
- ^ Hickok G, Poeppel D (2007) Towards a functional neuroanatomy of speech perception. Тенденции в когнитивных науках 4, 131–138
- ^ Kröger BJ, Birkholz P (2007) A gesture-based concept for speech movement control in articulatory speech synthesis. In: Esposito A, Faundez-Zanuy M, Keller E, Marinaro M (eds.) Verbal and Nonverbal Communication Behaviours, LNAI 4775 (Springer Verlag, Berlin, Heidelberg) pp. 174-189
- ^ Kröger BJ, Birkholz P, Kannampuzha J, Eckers C, Kaufmann E, Neuschaefer-Rube C (2011) Neurobiological interpretation of a quantitative target approximation model for speech actions. In: Kröger BJ, Birkholz P (eds.) Studientexte zur Sprachkommunikation: Elektronische Sprachsignalverarbeitung 2011 (TUDpress, Dresden, Germany), pp. 184-194
- ^ Kröger BJ, Miller N, Lowit A, Neuschaefer-Rube C. (2011) Defective neural motor speech mappings as a source for apraxia of speech: Evidence from a quantitative neural model of speech processing. In: Lowit A, Kent R (eds.) Assessment of Motor Speech Disorders. (Plural Publishing, San Diego, CA) pp. 325-346
- ^ Kröger BJ, Birkholz P, Kannampuzha J, Kaufmann E, Neuschaefer-Rube C (2011) Towards the acquisition of a sensorimotor vocal tract action repository within a neural model of speech processing. In: Esposito A, Vinciarelli A, Vicsi K, Pelachaud C, Nijholt A (eds.) Analysis of Verbal and Nonverbal Communication and Enactment: The Processing Issues. LNCS 6800 (Springer, Berlin), pp. 287-293
- ^ Kröger BJ, Kannampuzha J (2008) A neurofunctional model of speech production including aspects of auditory and audio-visual speech perception. Proceedings of the International Conference on Audio-Visual Speech Processing 2008 (Moreton Island, Queensland, Australia) pp. 83–88